and Mitigating Algorithmic Unfairness with the MADD Metric
Sorbonne Université, CNRS, LIP6, F-75005 Paris, France
Abstract
Predictive student models are increasingly used in learning environments due to their ability to enhance educational outcomes and support stakeholders in making informed decisions. However, predictive models can be biased and produce unfair outcomes, leading to potential discrimination against certain individuals and harmful long-term implications. This has prompted research on fairness metrics meant to capture and quantify such biases. Nonetheless, current metrics primarily focus on predictive performance comparisons between groups, without considering the behavior of the models or the severity of the biases in the outcomes. To address this gap, we proposed a novel metric in a previous work (Verger et al., 2023) named Model Absolute Density Distance (MADD), measuring algorithmic unfairness as the difference of the probability distributions of the model’s outcomes. In this paper, we extended our previous work with two major additions. Firstly, we provided theoretical and practical considerations on a hyperparameter of MADD, named bandwidth, useful for optimal measurement of fairness with this metric. Secondly, we demonstrated how MADD can be used not only to measure unfairness but also to mitigate it through post-processing of the model’s outcomes while preserving its accuracy. We experimented with our approach on the same task of predicting student success in online courses as our previous work, and obtained successful results. To facilitate replication and future usages of MADD in different contexts, we developed an open-source Python package calledmaddlib(https://pypi.org/project/maddlib/).
Altogether, our work contributes to advancing the research on fair student models in education.
Keywords
1. Introduction
Since recent years, a growing body of research has shown that artificial intelligence (AI) and predictive models are not free from biases coming from technical and societal issues (Mehrabi et al., 2022, Selbst et al., 2019, Lopez, 2021). These models are consequently prone to produce harmful, unfair outcomes (Buolamwini and Gebru, 2018, Bolukbasi et al., 2016, Larson et al., 2016, Dastin, 2018). This has led not only to give a solid new impulsion to research on fairness (Hutchinson and Mitchell, 2019, Barocas et al., 2019), but also to increase public awareness about the potential harms of AI and predictive models and the enforcement of stricter regulations1 (Calvi and Kotzinos, 2023).
Particularly in education, where predictive models are meant to improve students’ learning experience (Romero and Ventura, 2020), unfair outcomes could, in turn, significantly hinder their academic achievements and could result in long-term negative implications for students (Baker and Hawn, 2021, Kizilcec and Lee, 2022, Vasquez Verdugo et al., 2022, Holstein and Doroudi, 2021). Indeed, based on these predictions, important decisions may be taken, such as reorienting them towards a different learning path, refusing their admission to a course, providing more limited learning support, or not considering them for a scholarship. Unfair predictions can thus lead to unfair decisions, and more often than not, none of the stakeholders involved (e.g., students, teachers, school, and university administration) are aware of unfairness issues in the considered process.
So far, research on fairness in AI and machine learning (ML) has given a lot of attention to classification models since a majority of tasks can be framed as classification problems (Barocas et al., 2019, Pessach and Shmueli, 2023, Makhlouf et al., 2021, Le Quy et al., 2022, Suresh and Guttag, 2021). This observation is equally applicable to AI and ML in education (Deho et al., 2022, Gardner et al., 2019, Hu and Rangwala, 2020, Lee and Kizilcec, 2020), where very common predictive tasks include predicting whether students will drop out, complete a course, be admitted to a particular university, or be granted a scholarship.
Hence, in a previous paper (Verger et al., 2023), we proposed a new fairness metric, Model Absolute Density Distance (MADD), applicable to binary classification tasks (and regression in Švábenský et al. (2024)’s work), particularly suitable to social contexts such as education. Indeed, in such contexts, the target variable we generally want to predict (e.g., dropout or success in education) cannot be explained solely by the features available for data collection. Other contextual factors (Lallé et al., 2024), including hidden historical biases (Mehrabi et al., 2022, Castelnovo et al., 2022), may also influence the target variable and cannot always be captured in the data. As a result, the target variable is not always a reliable indicator for evaluating fairness. The MADD metric was developed to address this limitation by not taking into account the target variable in its calculation. In (Verger et al., 2023), it allowed us to detect some algorithmic biases that were not visible otherwise.
In this paper, we provide two major additions to the MADD metric. Firstly, we offer an in-depth study of a MADD-specific parameter, the bandwidth, to demonstrate how to measure fairness with this metric optimally. We also develop an automated search algorithm to tune this parameter. Secondly, we provide a new method to mitigate algorithmic unfairness based on the MADD metric. This method enables us to preserve the accuracy of the predictions while correcting some of the unfairness of the model. For these two main new contributions, we consider the common task of predicting student success or failure at a course level, with both simulated data and real-world educational data. The real-world data came from the Open University Learning Analytics Dataset (OULAD) (Kuzilek et al., 2017) and was chosen as an open dataset as well as for the sake of comparison with our previous results. Furthermore, we discuss the implications of our results for both contributions and provide relevant guidelines for using MADD.
As a final contribution to foster future usages of this metric, we
provide the source code and the data of our experiments in open
access2, along with a Python
package called maddlib3
gathering all the programming functions needed for fairness evaluation and mitigation with
MADD.
The remainder of this paper is organized as follows. We first provide a context for our research in Section 2, reviewing the relevant literature and discussing related work. We then present the MADD metric in detail as well as how to use it in practice in Section 3. Next, we thoroughly study the bandwidth, the MADD hyperparameter, worthwhile for the optimal measurement of fairness with this metric, in Section 4. We thus replicate our previous results (Verger et al., 2023) with the optimal computation in Section 5, in particular thanks to the algorithm we introduce in the preceding section. Additionally, we propose a fair post-processing technique to improve fairness based on MADD in Section 6. Finally, we discuss all MADD-related contributions and limitations in Section 7 before concluding this paper in Section 8.
2. Related work
2.1. Fairness metrics
The following paragraphs discuss the positioning of MADD in the context of existing fairness metrics and present how it differs from them. The existing fairness metrics are categorized into three main approaches: causality-based (counterfactual), similarity-based (individual), and statistical (group) metrics (Castelnovo et al., 2022, Verma and Rubin, 2018). However, the first two categories, causality-based and similarity-based, are seldom used in practice since, in order to determine what is fair on a specific problem, they require either making strong assumptions that would introduce additional biases or gathering extensive prior knowledge which comes at a cost (Verma and Rubin, 2018). In contrast, statistical metrics, which only require the selection of comparison groups beforehand, are suitable in many applications, making them popularly studied in the literature and widely used in practice. MADD falls into this category.
Within statistical metrics, the concept of group fairness involves three main notions: independence, separation, and sufficiency (Castelnovo et al., 2022). In the literature, “independence is strictly linked to what is known as demographic (or statistical) parity, separation is related to equality of odds and its relaxed versions, while sufficiency is connected to the concept of calibration and predictive parity” (Castelnovo et al., 2022). More precisely, independence looks for the predictions to be independent of the group membership, separation for the predictions to be independent of the group membership conditionally to the ground truth, and sufficiency for the ground truth to be independent of the group membership conditionally to the predictions. These notions are useful in distinct real-life scenarios (Castelnovo et al., 2022): separation is more suitable when we trust the objectivity of the target variable and when making discrimination is justified as long as it follows the actual data; sufficiency takes the perspective of the decision maker, focusing on error parity among people who are given the same predictions, not the same ground truth as does separation; and independence is meaningful when hidden historical biases could impact the entire datasets in a complex way so that we cannot entirely trust the objectivity of the target variable, particularly in social contexts like education, as mentioned in Section 1. Therefore, MADD was designed as an independence criterion.
Moreover, unlike other metrics that assess unfairness based on predictive performance comparison across groups, MADD takes into account the two entire predicted probability distributions in a finer-grained way (see its definition in Section 3). That is why this metric is able to capture cases where a model generates errors with varying severity based on group membership, even when it produces on average similar error rates across different groups, which other metrics cannot capture. In addition, MADD offers a visual interpretation of how the models behave and of the related group distributions, allowing us to gain a deeper understanding of algorithmic biases (see Section 3.2 as well as Figure 6c as examples; see (Verger et al., 2023) for detailed visual analyses).
2.2. Fairness evaluation for classification in education
We now present how algorithmic fairness has been studied in education research. Although considerations of social fairness have always been deeply rooted in the field (e.g., studies on inequalities in educational opportunities and outcomes), the consideration of algorithmic fairness is in fact much more recent and motivated by the growing number of students who are affected by algorithmic systems in educational technologies today (Hutchinson and Mitchell, 2019, Kizilcec and Lee, 2022). Therefore, compared with the broader fields of AI and ML, algorithmic fairness studies in education are even more recent and less numerous.
Among them, most studies focused on comparing the predictive performance of models, for instance aimed at predicting student retention in an online college program between African-Americans and Whites (Kai et al., 2017), risk of failing a course between African-American and the other students (Hu and Rangwala, 2020), six-year college graduation or school and college dropout between multiple ethnic groups (Anderson et al., 2019, Christie et al., 2019, Yu et al., 2021), and course grade between males and females (Lee and Kizilcec, 2020). We refer the reader to the surveys (Baker and Hawn, 2021) and (Kizilcec and Lee, 2022) for a more comprehensive overview, but it is worth noting that these high-stakes real-world applications are primarily centered around classification tasks, in line with the prevalent trends in the fields of AI and ML as said above.
Other studies used well-established statistical fairness metrics such as group fairness, equalized odds, equal opportunity, true positive rate, and false positive rate between groups. They were applied in scenarios such as predicting course completion (Li et al., 2021), at-risk students (Hu and Rangwala, 2020), and college grades and success (Jiang and Pardos, 2021, Yu et al., 2020, Lee and Kizilcec, 2020). Additionally, Gardner et al. (2019) proposed a new fairness metric developed in this educational field, Absolute Between-ROC Area (ABROCA), which is based on the comparison of the Areas Under the Curve (AUC) of a given predictive model for different groups of students. The authors used it to assess gender-based differences in classification performance of MOOC dropout models, showing that ABROCA captured unfair classification performance related to the gender imbalance in the data. This metric has also been used to evaluate fairness across different sociodemographic groups in contexts of predicting college graduation (Hutt et al., 2019) and predicting the content-relevance of students’ educational forum posts (Sha et al., 2021).
Nonetheless, all of the aforementioned metrics rely on predictive performance comparison, and that is why we investigate the value of MADD as a fairness metric that accounts for the behaviors of the classifiers instead. This will contribute to the line of fairness work in education, and although they are two distinct approaches (independence vs. separation), we offered a comparison with ABROCA in (Verger et al., 2023) to demonstrate the complementary nature of the results, since fairness is a broad, complex and context-sensitive notion.
2.3. Unfairness mitigation
In addition to fairness evaluation, existing techniques aim to mitigate unfairness by reducing some algorithmic biases. These techniques could be deployed at different stages: in the pre-processing, the in-processing, and the post-processing phases of the ML pipeline (Kizilcec and Lee, 2022). Generally, pre-processing techniques try to transform the training data so that the underlying discrimination is removed, in-processing techniques try to modify and change state-of-the-art learning algorithms in order to remove discrimination during the model training, and post-processing techniques try to transform the model outputs to improve prediction fairness (d’Alessandro et al., 2017, Caton and Haas, 2024). The latter do not require access to the actual model, needing only access to the outputs and sensitive attributes information. They are performed after the training (by using a holdout set), which makes them a highly flexible approach. They are thus applicable to black-box scenarios, where models could be tailor-made for a specific task, and where the entire ML pipeline is not exposed (Mehrabi et al., 2022, Caton and Haas, 2024).
Moreover, the work in (Deho et al., 2022) and our previous findings in (Verger et al., 2023) did not show evidence of a direct relationship between data bias and predictive bias, meaning that trying to remove biases during the pre-processing and the in-processing phases would not guarantee fair model outputs. That is why one of the contributions of this paper is also to propose a post-processing method to improve fairness thanks to the MADD metric (see Section 6). Indeed, it consists in taking an already-trained model and transforming its outputs to satisfy the fairness notion implied by MADD, while preserving the model’s predictive performance as much as possible.
3. The MADD metric
This Section 3 is dedicated to explaining the MADD metric. In the following, we will introduce the necessary notations for the rest of the paper (Section 3.1), we will present the general idea behind the metric (Section 3.2), we will provide its formalized definition (Section 3.3), and we will conclude by indicating how to compute and implement it in a standard ML evaluation process (Section 3.4).
3.1. Notations
Data and model.Let \(\mathcal {C}\) be a binary classifier, which for instance aims to predict student success or failure at a course level. \(\mathcal {C}\) is trained on a dataset \(\left \{X, S, Y \right \}_{i = 1}^{n}\), with \(n\) the number of unique students or samples, \(X\) the features characterizing the students, \(S\) a binary sensitive feature that will be further detailed, and \(Y\) the binary target variable whose values \(y_i \in \left \{ 0, 1 \right \}\) (e.g. 1 for success and 0 for failure). The objective of \(\mathcal {C}\) is to minimize some loss function \(\mathcal {L}(Y, \hat {Y})\), with \(\hat {Y}\) its predictions that estimate \(Y\).
Model output.To calculate MADD, it is necessary for \(\mathcal {C}\) to be able to output not only its predictions \(\hat {y}_i \in \left \{ 0, 1 \right \}\) but also the predicted probability \(\hat {p_i}\) associated to each prediction \(\hat {y}_i\) (\( \mathcal {C} \rightarrow \left \{ \hat {y_i} = \left \{0, 1\right \}, \hat {p_i} \in [0, 1] \right \} \)). In the rest of the paper, we focus on the probability related to the positive prediction for every student \(i\), i.e., the probabilities \(\hat {p_i}\) associated to \(\hat {y_i}=1\). Indeed, \(\mathcal {C}\) predicts \(\hat {y}_i = 1\) if and only if \(\hat {p}_i \geq t\) with \(t\) the classification threshold, and it predicts \(\hat {y}_i = 0\) otherwise.
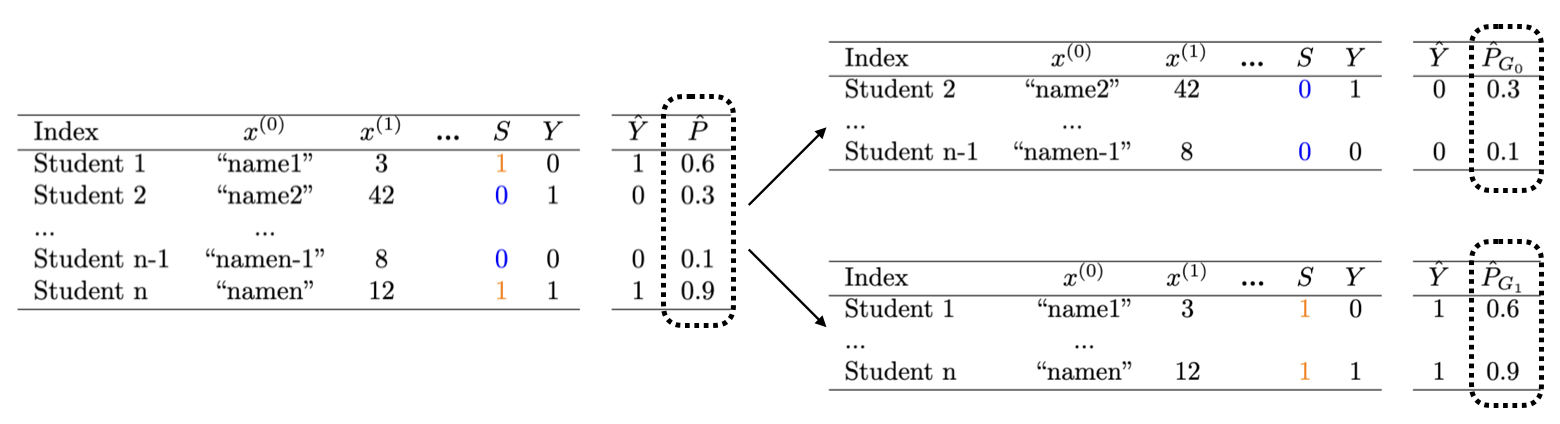
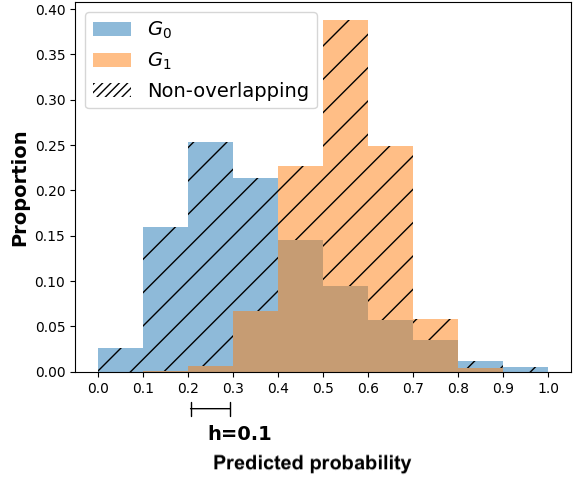
Sensitive feature.The feature \(S\) is the feature with respect to which we will evaluate algorithmic fairness with MADD. It is commonly called sensitive feature, but there is no restriction on what \(S\) should represent. Nonetheless, \(S\) should be a binary feature here, i.e., composed of two distinct groups of students, indexed respectively by \( G_0 = \left \{1 \leqslant i \leqslant n \mid S_i = 0\right \} \) and \( G_1 = \left \{1 \leqslant i \leqslant n \mid S_i = 1\right \} \). Plus, \(n_0 = \operatorname {card}(G_0)\) and \(n_1 = \operatorname {card}(G_1) \) are the number of students who belong to these groups respectively (which cannot be empty). As an example, if \(S\) corresponds to having declared a disability, a given student cannot belong to both the group of those who have not (e.g. \(G_0\)) and the group of those who have (e.g. \(G_1\)) declared a disability. It is worth noting that none of these groups are considered a baseline or a privileged group in the calculation of MADD. Indeed, most of the time, fairness is evaluated by comparing the predictive performance of a model between the majority group and a minority group, thus implicitly considering the majority group as the baseline or the privileged group. Considering that MADD will take into account an absolute distance, it does not assume a priori that there is one group towards which the results should converge. Then, we denote \(\hat {P}_{G_0} = (\hat {p}_i)_{i \in G_0}\) and \(\hat {P}_{G_1} = (\hat {p}_i)_{i \in G_1}\) the predicted probabilities for the groups \(G_0\) and \(G_1\) respectively. We refer the reader to the forthcoming Figures 3 and 4 for a summary of some of these notations.
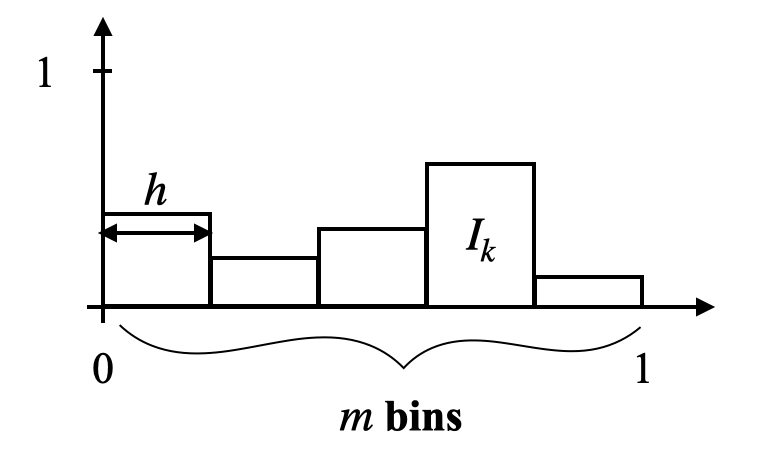
We introduce the hyperparameter \(h \in (0, 1]\), originally noted as \(e\) and called probability sampling step in (Verger et al., 2023), that we rename bandwidth here. Its name, role, and purpose will be further detailed in Section 4, but, as a first intuition, it represents the resolution with which we compute MADD in order to measure fairness with this metric optimally. The bandwidth \(h\) is directly linked to an equivalent parameter, \(m \in \mathbb {N}^{*}\), with \(m\) being equal to \(\lfloor 1/h \rfloor \). Thus, \(m\) is the number of subintervals of the unit interval \(I = [0, 1]\) that the value of \(h\) will determine. Let us see in Figure 1 an illustration of these parameters. In the figure, we can see that \(h\) corresponds to the width of the bins of a histogram (further studied in Section 4) while \(m\) corresponds to its total number of bins. For instance, if \(h=0.022\), then \(m=\lfloor 1/0.022 \rfloor =45\), meaning that there are 45 subintervals of the same width \(0.02\overline {2}\) (or 1/45) in \(I\): \([0, 1/45)\), \([ 1/45, 2/45)\), \(\ldots \), \([43/45, 44/45)\), \([44/45, 1]\). We finally introduce a last notation which is \(I_k\), representing the subinterval indexed by \(k\) where \(I_k = [(k-1) / m, k / m)\) for \(k \in [1, 2, ..., m - 1]\), and \(I_m = [(m-1) / m, 1]\) for \(k=m\). Following up on the above example, \(I_{44} = [43/45, 44/45)\).
3.2. Approach of MADD
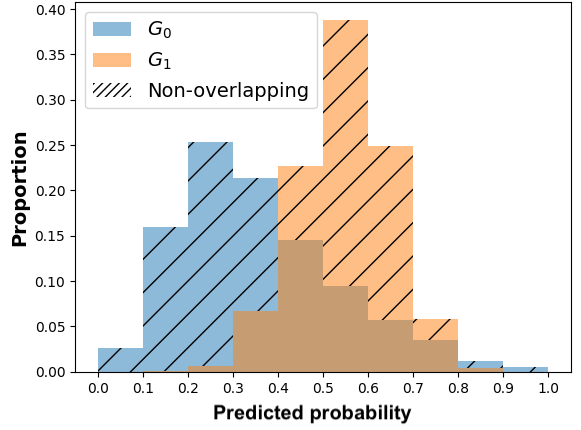
The general idea of MADD consists in comparing how a classifier \(\mathcal {C}\) distributes its predicted probabilities depending on the group the students belong to (\(G_0\) or \(G_1\)). Let us consider a toy example with the distributions displayed in Figure 1a and where \(h=0.1\) so \(m=10\). Thus, to measure how different these distributions are, our goal is to measure the absolute distance between the proportions (or percentages \(\in [0, 1]\)) of students receiving the same probabilities, according to their group membership. For each bin of the two histograms, a single distance corresponds to the red arrow in Figure 1a, and the total distance is consequently the sum of all these single absolute distances. It visually corresponds to the non-overlapping part of the two histograms, as shown in Figure 1b. Indeed, in the areas where the two distributions do not intersect, the model does not distribute its predicted probabilities the same according to the group membership. This is precisely what we intend to measure with MADD.
3.3. Definition of MADD
As previously mentioned in Section 3.2, Model Absolute Density Distance (MADD) is a measure of the absolute distance between the proportions of students of \(G_0\) and \(G_1\) receiving the same predicted probabilities. To define MADD, we first need to introduce two unidimensional vectors, \(D_{G_0}\) and \(D_{G_1}\), that correspond to the two histograms of the respective groups \(G_0\) and \(G_1\), exemplified in Figure 1a. Thus, we denote \(D_{G_0} = (d_{G_0,k})_{1\leqslant k \leqslant m}\) and \(D_{G_1} = (d_{G_1,k})_{1\leqslant k \leqslant m}\), where each \(d_{G_0,k}\) and \(d_{G_1,k}\) is defined such that:
\begin {equation} d_{G_0,k}= \frac {1}{n_0} \sum _{i \in G_0} \mathds {1}_{I_k}(\hat {p}_{i}),\quad d_{G_1,k}= \frac {1}{n_1} \sum _{i \in G_1} \mathds {1}_{I_k}(\hat {p}_{i}) \label {d-k-def} \end {equation}
with \(\mathds {1}\) the indicator function (and \(m\), \(n_0\), and \(n_1\) introduced in Section 3.1). The value of \(\mathds {1}_{I_k}(\hat {p}_{i})\) equals to 1 if \(\hat {p}_{i}\) belongs to the interval \(I_k\) and 0 otherwise:
\begin {equation} \mathds {1}_{I_k}(\hat {p}_{i}) = \left \{ \begin {array}{ll} 1 & \mbox {if } \hat {p}_{i} \in I_k \\ 0 & \mbox {if } \hat {p}_{i} \notin I_k \end {array} \right . \label {indicatorUNDERSCOREfunctionUNDERSCOREeq} \end {equation}
Thus, \(d_{G_0,k}\) (resp. \(d_{G_1,k}\)) contains the proportion of students of \(G_0\) (resp. \(G_1\)) for whom the model \(\mathcal {C}\) gave a predicted probability \(\hat {p}_i\) that fell into \(I_k\). We can now define MADD as follows:
\begin {equation} \label {MADDeq} \text {MADD}(D_{G_0}, D_{G_1}) = \sum _{k=1}^m | d_{G_0,k} - d_{G_1,k} | \end {equation}
The MADD metric satisfies the necessary properties of a metric: reflexivity, non-negativity, commutativity, and triangle inequality (Cha and Srihari, 2002) (see proofs in Appendix of Verger et al. (2023)’s paper). Moreover, a property of MADD is that it is bounded:
\begin {equation} \hspace {0.2cm} 0 \leqslant \text {MADD}(D_{G_0}, D_{G_1}) \leqslant 2 \label {MADDeq-boundaries} \end {equation}
The closer MADD is to 0, the fairer the outcomes of the model are regarding the two groups. Indeed, if the model produces the same probability outcomes for both groups, then \(D_{G_0} = D_{G_1}\) and \(\text {MADD}(D_{G_0}, D_{G_0}) = 0\). Conversely, in the most unfair case, where the model produces totally distinct probability outcomes for both groups, MADD is equal to 2 because we sum all the proportions of both groups whose respective total is 1. An example of such a situation could be when on the one hand, \(\exists k_{0}, d_{G_0,k_{0}} = 1\) and \(\forall k \in [1,m], k \neq k_{0}, d_{G_0,k} = 0\), and on the other hand, \(\exists k_{1} \neq k_{0}, d_{G_1,k_{1}} = 1\) and \(\forall k \in [1,m], k \neq k_{1}, d_{G_1,k} = 0\). In that case, Equation \eqref{MADDeq} simply becomes:
\begin {equation} \text {MADD}(D_{G_0}, D_{G_1}) = | d_{G_0,k_{0}} - 0| + | d_{G_1,k_{1}} - 0| = 1 + 1 = 2 \end {equation}
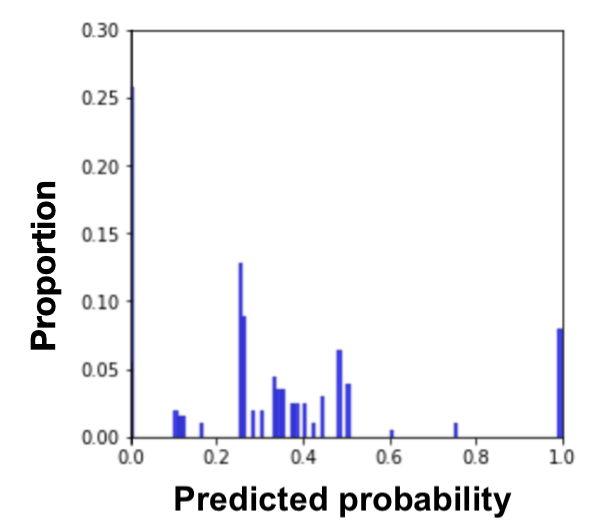
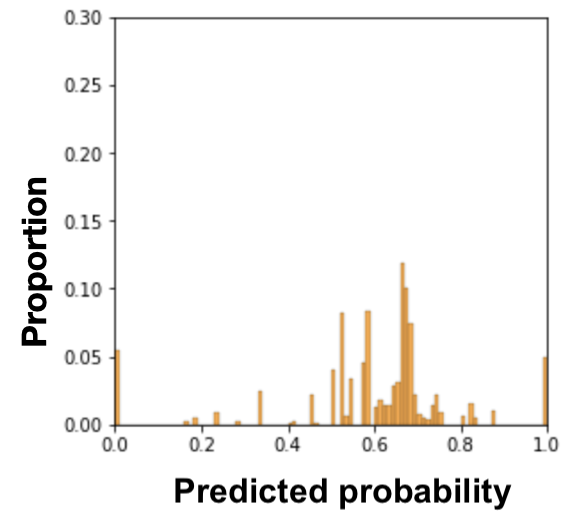
Also, in Equation \eqref{MADDeq}, we can see that the numerical value of MADD depends on its bandwidth parameter through the value of \(m\) in the sum (see Figure 5 for a visual example). Indeed, since \(m\) is also the number of bins of the histograms, it will affect the \(\hat {p}_i\) that would fall into the \(I_k\) and thus the values of \(d_{G_0,k}\) and \(d_{G_1,k}\). Furthermore, the bandwidth \(h\) allows us to make the two histograms \(D_{G_0}\) and \(D_{G_1}\) comparable for the MADD calculation. Indeed, let us say that the model \(\mathcal {C}\) outputs probabilities in the range of \([0.0, 1.0]\) for one group and of \([0.2, 0.9]\) for the other, such as illustrated in Figure 2. If \(h\) did not allow the discretization of the unit interval \(I=[0, 1]\) to have common bins for both histograms, then the comparison of \(D_{G_0}\) and \(D_{G_1}\) would have been biased and the MADD results would have been wrong estimations of the distance between these two. In Section 4 further on, we will address the selection of this bandwidth parameter \(h\) that allows MADD to best estimate this distance between the two distributions and thus best estimate (un)fairness with this metric.
It is worth emphasizing again, as explained in Section 2.1, that MADD is an independence metric, made for cases where we do not trust the objectivity of the target variable due to complex hidden historical biases. Therefore, a MADD value of 0 only means a fair output according to this definition of fairness. When it is acceptable that two groups have different histograms, e.g., representing a known historical advantage and disadvantage between two groups, this type of fairness should be measured by a separation metric.
3.4. Implementation of MADD
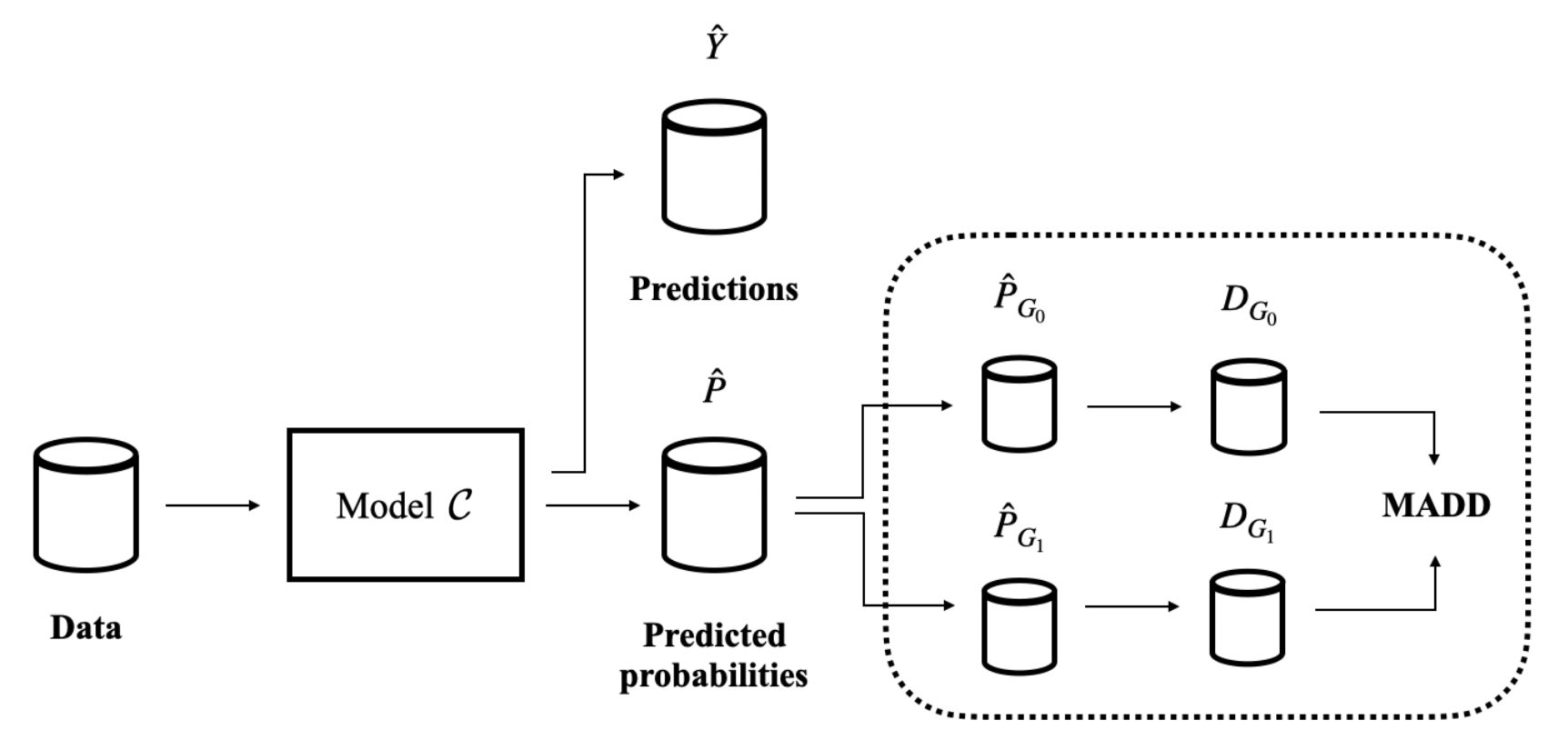
Now, in Figure 3, we show how to compute MADD within a standard ML pipeline. The computation of MADD is performed after the model \(\mathcal {C}\) has been trained, as shown in the dotted box. Hence, it does not affect the data or the model itself. More specifically, MADD is computed on the set of probabilities \(\hat {P}\) outputted by the model. The first step consists in splitting the probabilities pertaining to each group to get \(\hat {P}_{G_0}\) and \(\hat {P}_{G_1}\). An example of this step is provided in Figure 4 with a sample tabular view. Next, the \(D_{G_0}\) and \(D_{G_1}\) vectors are derived from \(\hat {P}_{G_0}\) and \(\hat {P}_{G_1}\) according to the \(h\) parameter, enabling to compute MADD (i.e., Equation \eqref{MADDeq}).
To ease its computation, we created an open-source Python package, maddlib. In particular, it
allows direct computation of MADD when provided with predicted probabilities, i.e., it
performs the split and the computation of \(D_{G_0}\) and \(D_{G_1}\) vectors directly (steps in the dotted box of
Figure 3). It also allows to plot the histograms and distributions for visual analysis. The
instructions for installing and using the package are available at its Python Package Index (PyPI)
link3.
4. Improving MADD computation
In this Section 4, we now focus on the influence of the bandwidth \(h\) on MADD and on how to fine-tune it. In our previous work (Verger et al., 2023), we considered that the choice of \(h\) was to be made by the data analyst based on what seems reasonable in a particular situation. Here, we will first explain how the bandwidth \(h\) intervenes in the MADD calculation (Section 4.1), then we will demonstrate why some optimal bandwidth values always exist (Section 4.2), and we will show how to select them. More precisely, we will provide an automated search algorithm to find this range of optimal bandwidth values (Section 4.3), and we will illustrate our findings on simulated data (Section 4.4) to confirm the validity of our approach, before applying it on real data in the next Section 5.
4.1. Influence of the bandwidth
At the end of Section 3.3, we saw that the bandwidth \(h\) influences the numerical value of MADD. Let us consider the example in Figure 5. When we have a few bins, such as when \(h=0.1\) (left-hand figure), all the probabilities fall into only a few (i.e., \(m=10\)) different intervals \(I_k\), which consequently see their proportions of corresponding \(\hat {p}_i\) increasing. On the other hand, when we increase the number of bins, for example by choosing a lower value of \(h\) such as \(h=0.05\) (right-hand figure), we increase the number of possible intervals (i.e., \(m=20\)) so that the probabilities are distributed into many more different intervals (leading to a visual spread out such as in Figure 4b). Therefore, the value of \(h\) affects the number of bins and thus the values of \(d_{G_0, k}\) and \(d_{G_1, k}\). This, in turn, can influence the numerical value of MADD, e.g., with a MADD of 1.18 for \(h=0.1\) and of 1.19 for \(h=0.05\) in the example of Figure 5.

In the next section, we will show that there exists a range of \(h\) values for which MADD best estimates the distance between the two distributions. Hence, we also call the \(h\) values of this range as optimal \(h\) values or optimal bandwidths. That is why we renamed this parameter as bandwidth (compared to probability sampling step noted \(e\) in (Verger et al., 2023)), as it refers to the range of \(h\) values for which the metric optimally measures (un)fairness.
4.2. Existence of optimal bandwidths
In this Section 4.2, we theoretically (and later experimentally) demonstrate that several optimal \(h\)
values always exist, ensuring that MADD is an optimal measure of (un)fairness, i.e., that it best
estimates the distance between the two distributions. We do so by first showing a property regarding \(D_{G_0}\)
and \(D_{G_1}\) (part 4.2.1), which then leads to demonstrating a theorem about MADD (part 4.2.2). More
specifically, we refine the definition of MADD using a well-established statistical tool, namely
histogram estimators. This enables us to borrow statistical properties from histogram estimators to
determine the optimal \(h\) values (part 4.2.3). In addition to the theoretical proofs, we will provide an
algorithm meant to infer the optimal \(h\) values in practice (next Section 4.3), which is implemented in the
maddlib package3.
4.2.1. Property on \(D_{G_0}\) and \(D_{G_1}\)
Here, we will see that \(D_{G_0}\) and \(D_{G_1}\) can be considered as probability density estimators. Indeed, the discrete values \(\hat {p}_i\), predicted by a model \(\mathcal {C}\), can be seen as samples of some respective underlying distributions with respect to the group \(G_0\) or \(G_1\). If we note the probability density functions (PDFs) of these underlying distributions as \(f^{G_0}\) and \(f^{G_1}\), therefore we can consider \(D_{G_0}\) and \(D_{G_1}\) as probability density estimators by histograms of \(f^{G_0}\) and \(f^{G_1}\) (Devroye and Gyorfi, 1985). An example is shown in Figure 6.
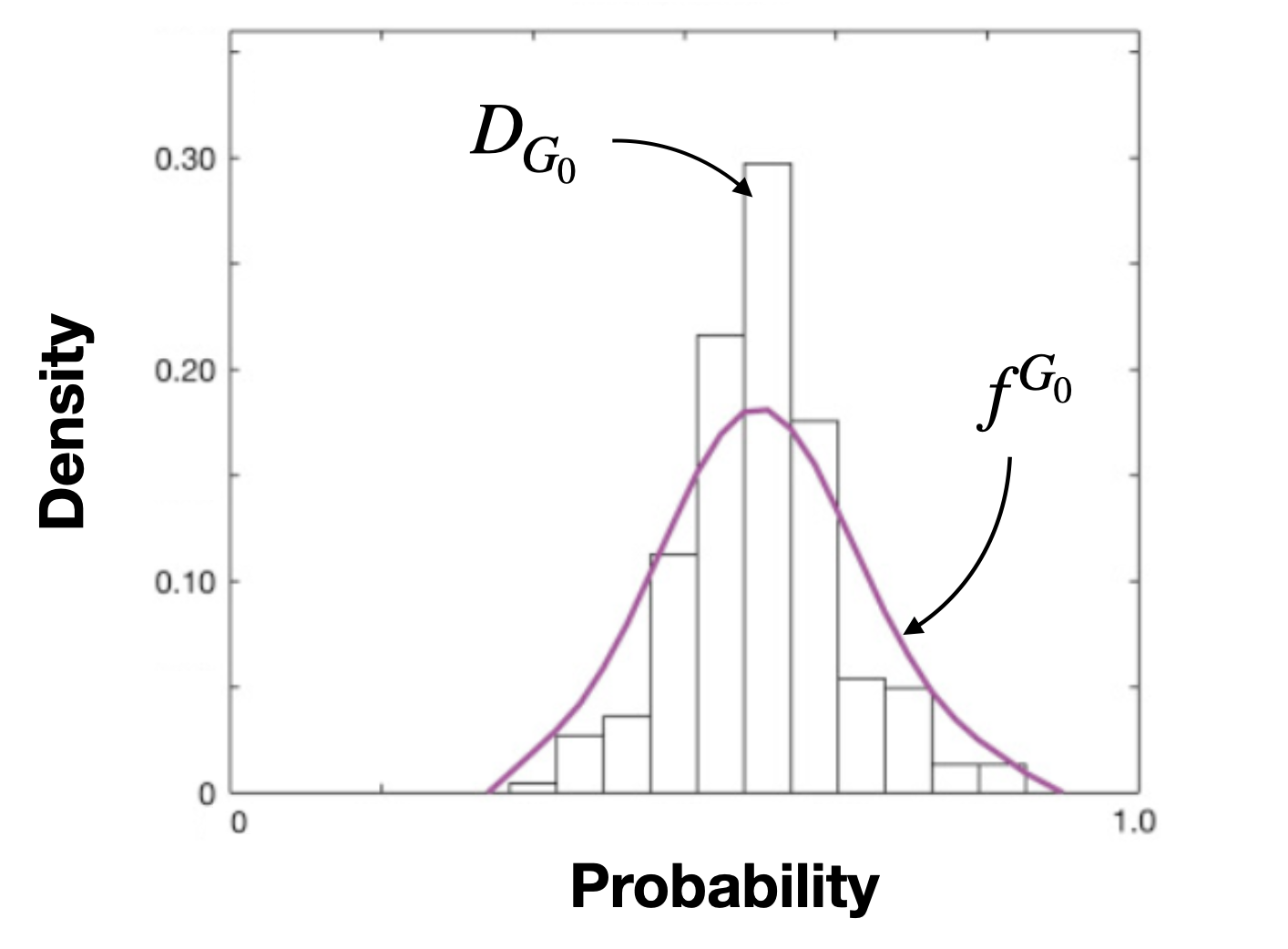
More precisely, the way we defined \(d_{G_0,k}\) and \(d_{G_1,k}\) in Equation \eqref{d-k-def} corresponds to the definition of a histogram estimator (Devroye and Gyorfi, 1985):
Definition 1. Assume \(f\) is the probability density function of a real distribution, \(\{q_i\}_{1 \leqslant i \leqslant n}\) are the samples of that distribution, and \(\mathds {1}\) the indicator function already defined in Section 3.3. The histogram function of the samples, also called the histogram estimator of \(f\) on \(I = [0,1]\), is: \begin {equation} \widehat {f}_h(x)= \frac {1}{h} \sum _{k=1}^m \left ( \frac {1}{n} \sum _{i=1}^{n} \mathds {1}_{I_k}(q_i) \right ) \mathds {1}_{I_k}(x). \end {equation}
It means that for a given \(h\), we discretize \(I\) in \(m = \lfloor 1/h \rfloor \) intervals \(I_k\) (external sum), and we see for each sample \(q_i\), how many other samples fall into each \(I_k\) (internal sum). Thus, for a \(x \in [0, 1]\), we count the number of \(q_i\) present in the same interval in which \(x\) falls and we divide this number by \(h\) to obtain a proportion. In the end, \(\widehat {f}_h(x)\) simply returns the proportion associated to the interval in which \(x\) falls, given a fixed bandwidth \(h\).
In the case of MADD, the \(\hat {p}_i\) in Equation \eqref{d-k-def} represent the samples \(q_i\) of the respective probability density functions \(f^{G_0}\) and \(f^{G_1}\), and \(d_{G_0,k}\) and \(d_{G_1,k}\) are the respective values of \(\widehat {f}_h(x)\) for the group \(G_0\) and \(G_1\). This property of \(D_{G_0}\) and \(D_{G_1}\) as probability density estimators leads us to a new theorem about MADD (see Theorem 1).
4.2.2. Theorem on MADD
Now, we will see that MADD is in fact a histogram-based estimator of the distance between two distributions on \(L_1[0,1]\) space. Let note \(\widehat {f}^{G_0}_h\), with \(G_0\) superscript, the histogram function of \(f^{G_0}\) (idem with the group \(G_1\)) for a given \(h\). From the previous part, we can interchangeably note \(D_{G_0}\) and \(D_{G_1}\) with \(\widehat {f}^{G_0}_h\) and \(\widehat {f}^{G_1}_h\), which are the histogram functions of \(f^{G_0}\) and \(f^{G_1}\) respectively (that can again be illustrated in Figure 6). Thus, we can formalize MADD as follows (see proof in Appendix 10.1):
Theorem 1___________
\begin {equation} \text {MADD}\left (D_{G_0}, D_{G_1}\right ) = \left \| \widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h \right \|_{L_1[0,1]} \end {equation}
____
Indeed, MADD in its original definition (Equation \eqref{MADDeq}) tries to estimate the distance on \(L_1[0,1]\) space between two distributions, \(f^{G_0}\) and \(f^{G_1}\), thanks to their histogram estimators \(D_{G_0}\) and \(D_{G_1}\). The distance on \(L_1[0,1]\) space is defined as follows (Devroye and Gyorfi, 1985):
Definition 2. Assume \(\widehat {f}^{G_0}_h\) and \(\widehat {f}^{G_1}_h\) are integrable functions on \([0,1]\). The distance between \(\widehat {f}^{G_0}_h\) and \(\widehat {f}^{G_1}_h\) on the space \(L_1[0,1]\) is thus defined as the integral of the absolute value of their difference on \([0,1]\), i.e.: \begin {equation} \left \|\widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h \right \|_{L_1[0,1]} := \int _0^1 \left |\widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h \right | \end {equation}
This measure actually represents, by definition, the area of the disjoint portion of the regions the distributions enclose with the x-axis. Therefore, Theorem 1 can be illustrated in Figure 7 by the red zone that MADD represents, and thus MADD itself can be seen as a histogram-based estimator of the distance between two distributions on \(L_1[0,1]\) space. This result will be crucial to prove the existence of optimal bandwidths in the following part 4.2.3.
4.2.3. Theorem on optimal bandwidths
Since MADD now consists of histogram estimators (part 4.2.1), and thanks to Theorem 1 applicable on \(L_1\) space (part 4.2.2), we can use statistical literature on histogram estimators on \(L_1\) space (Devroye and Gyorfi, 1985) to propose a new theorem on the optimal bandwidths of MADD. Indeed, in the next Theorem 2, we define the \(h\) values with which MADD best estimates (or converges to) the true distance \(\left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]}\). We display here a short version of this theorem, but its mathematically rigorous version and its proofs are available in Appendix 10.2.
Theorem 2 (Short version)_________________________
If \(f^{G_0}\) and \(f^{G_1}\) satisfy the commonly required assumptions of smoothness, then
\(\text {MADD}\left (D_{G_0}, D_{G_1}\right )\), whose \(D_{G_0}\) and \(D_{G_1}\) depend on \(h\), converges to \(\left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]}\)
with the smallest error (of at most \(O\left (\left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}}\right )\)), when \(h=O\left (\left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}}\right )\).
_________
There are three important points to highlight from this theorem. Let note \(c = \left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}}\). Firstly, when the number of samples or students \(n\) increases, MADD converges to the true distance between the two distributions, \(\left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]}\). It is exemplified later on in Figure 10b. Secondly, when MADD precisely converges to the true distance, the errors between MADD and the true distance are at most \(O(c)\), i.e., in order of \(c\). For simplification, the notation \(O(c)\) means that, if the errors are \(O(c)\), then they are inferior or equal to \(c\) multiplied by a constant \(k > 0\). Another way to apprehend the notation \(O\) is that the errors are asymptotically smaller or equal to \(c \times k\). Thirdly, and most importantly for the search of optimal bandwidths, the smallest error is reached when \(h\) is \(O(c)\). Again, it means that the optimal \(h\) this time should be inferior or equal to \(c \times k\). We will note \(h_{sup} = c \times 1 = c\) in the rest of the paper. In the end, we now know that MADD converges to a specific value, which is the best estimate of the true distance, and leading to a range of optimal \(h\) values around \(h_{sup}\).
If we knew the theoretical \(f^{G_0}\) and \(f^{G_1}\), we could find a single precise optimal \(h\) for which MADD is the very best estimate of \(\left \| f^{G_0} - f^{G_1} \right \|\). In practice, since we only have access to their histogram estimations \(D_{G_0}\) and \(D_{G_1}\) (or \(\widehat {f}^{G_0}_h\) and \(\widehat {f}^{G_1}_h\)), we can only identify the range of optimal \(h\) values. Consequently, in the following section, we elaborate on a search strategy to approximate this range of \(h\) values for which MADD optimally estimates (un)fairness.
4.3. Optimal Bandwidth Interval Search Algorithm
Now that we know that optimal bandwidths always exist, the question is: how can we find them in practice? To this end, we developed Algorithm 1, presented in the next pages, to infer these \(h\) automatically. We will first discuss the approach taken by the algorithm in part 4.3.1, followed by a detailed description of how the algorithm works in part 4.3.2.
4.3.1. Approach
As said in the previous part 4.2.3, Theorem 2 ensures that MADD will converge to the true distance \(\left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]}\) for a range of \(h\) that we will call optimal bandwidth interval in the following. Although we cannot know the single precise optimal \(h\) in practice, we can still identify an optimal bandwidth interval where MADD has converged and is considered “stable”. In this context, “stable” implies that the MADD values remain consistent, i.e., within a range that we will assess with the smallest standard deviation possible.
To find this optimal bandwidth interval, since \(h \in (0, 1]\) (Section 3.1), we first compute MADD for a large given number of \(h\) within the search space \((0,1]\) (e.g., we chose \(1,000\) distinct \(h\) values in Section 4.4, and the more the better depending on computation time). Then, we explore all possible eligible intervals of \(h\), whose conditions are below, within this search space, and we compute the standard deviation of the MADD values within each eligible interval to find the one with the smallest standard deviation. Nonetheless, as \(h_{sup}\) is already a compromise between the number of students \(n_0\) and \(n_1\) (part 4.2.3), it is most likely that \(h\) will be smaller than \(h_{sup}\) for better precision, which means that the experimental optimal \(h\) will be expected to lie before \(h_{sup}\) in the search space.
To define eligible intervals, we set two conditions. Firstly, each eligible interval should include at
least 50 MADD values minimum to ensure that the standard deviation is meaningful (\(nbPointsMin\) in Algorithm 1).
This condition comes from the fact that distinct MADD values are associated to \(h\) values that are not
linearly spaced, as explained in the next paragraph. Secondly, the width of the eligible intervals is set to
at least \(h_{sup} \times 0.45\) (\(percent\) in Algorithm 1) to ensure that MADD appears stable within a significantly large range, which
is unlikely due to chance. It has to be noted that the values of these two conditions, which we deem
reasonable based on our experience, are nonetheless arbitrary and can be fine-tuned in the maddlib
package3.
![Algorithm 1 F ind Stable Interval of M A D D w ith M inim um S tand ard D
1: Input:
2: Lh : ord ered list o f h values w here to find a stable interv al
-
3: Lmadd : ordered list of M A DD resu lts associated to the h in h list
4: n0 , n1: nu mb er of individuals in G0 and G1 respectively
5: [nbP ointsM in = 50 ]: desired m in im um num ber of stab le M A DD results (defau
50)
6: [percent = 0.45]: percent fo r th e m inim al length of the stable interval �
7: Ou tput:
8: indexes : tuple (i,j) of start and end indexes of the stable interval
9: stdM in: m inim um stand ard deviation found in this interva l
10: average : averag e M A D D within this interval
11: Initialization
12: indexes ← (0,0)
13: stdM in ← ∞
14: hM ax ← last elem ent of Lh
(√n-+√n--)23
15: order ← --√0n0n11
16: intervalLengthM in ← order × percent
17: Search of the optim al ba ndw id th interval
18: fo r 0 ≤ i ≤ length o f Lmadd − nbP ointsM in do
19: leftBound ← Lh [i]
20: // 1. B uilding eligible intervals (if needed)
21: if leftBound > (hM ax − intervalLengthM in) th en
22: break
23: end if
24: rightBound ← lef tBound + intervalLengthM in
25: rightBoundIndex ← (po sitio n of rightBound as if in Lh ) − 1
26: if rightBoundIndex < i + nbP ointsM in th en
27: rightBoundIndex ← i + nbP ointsM in
28: end if
29: // 2. Increasing u pper bo und of eligible intervals
30: for rightBoundIndex ≤ j ≤ en d of Lmadd d o
31: std ← standard d eviation o f Lmadd betw een ind exes i and j
32: if std < stdM in th en
33: stdM in ← std
34: indexes ← (i,j)
35: end if
36: end for
37: end for](data:image/svg+xml;base64,PD94bWwgdmVyc2lvbj0nMS4wJyBlbmNvZGluZz0nVVRGLTgnPz4KPCEtLSBUaGlzIGZpbGUgd2FzIGdlbmVyYXRlZCBieSBkdmlzdmdtIDMuMi4yIC0tPgo8c3ZnIHZlcnNpb249JzEuMScgeG1sbnM9J2h0dHA6Ly93d3cudzMub3JnLzIwMDAvc3ZnJyB4bWxuczp4bGluaz0naHR0cDovL3d3dy53My5vcmcvMTk5OS94bGluaycgd2lkdGg9JzYzNy41NjE0NTRwdCcgaGVpZ2h0PSc5MjMuMTczMTg4cHQnIHZpZXdCb3g9Jy4xNTAwNzIgMTA4Ljc3NDg0OSA2MzcuNTYxNDU0IDkyMy4xNzMxODgnPgo8ZGVmcz4KPHBhdGggaWQ9J2c0NC01OCcgZD0nTTIuMTk5NzUxLS41NzM4NDhDMi4xOTk3NTEtLjkyMDU0OCAxLjkxMjgyNy0xLjE1OTY1MSAxLjYyNTkwMy0xLjE1OTY1MUMxLjI3OTIwMy0xLjE1OTY1MSAxLjA0MDEtLjg3MjcyNyAxLjA0MDEtLjU4NTgwM0MxLjA0MDEtLjIzOTEwMyAxLjMyNzAyNCAwIDEuNjEzOTQ4IDBDMS45NjA2NDggMCAyLjE5OTc1MS0uMjg2OTI0IDIuMTk5NzUxLS41NzM4NDhaJy8+CjxwYXRoIGlkPSdnNDQtNTknIGQ9J00yLjMzMTI1OCAuMDQ3ODIxQzIuMzMxMjU4LS42NDU1NzkgMi4xMDQxMS0xLjE1OTY1MSAxLjYxMzk0OC0xLjE1OTY1MUMxLjIzMTM4Mi0xLjE1OTY1MSAxLjA0MDEtLjg0ODgxNyAxLjA0MDEtLjU4NTgwM1MxLjIxOTQyNyAwIDEuNjI1OTAzIDBDMS43ODEzMiAwIDEuOTEyODI3LS4wNDc4MjEgMi4wMjA0MjMtLjE1NTQxN0MyLjA0NDMzNC0uMTc5MzI4IDIuMDU2Mjg5LS4xNzkzMjggMi4wNjgyNDQtLjE3OTMyOEMyLjA5MjE1NC0uMTc5MzI4IDIuMDkyMTU0LS4wMTE5NTUgMi4wOTIxNTQgLjA0NzgyMUMyLjA5MjE1NCAuNDQyMzQxIDIuMDIwNDIzIDEuMjE5NDI3IDEuMzI3MDI0IDEuOTk2NTEzQzEuMTk1NTE3IDIuMTM5OTc1IDEuMTk1NTE3IDIuMTYzODg1IDEuMTk1NTE3IDIuMTg3Nzk2QzEuMTk1NTE3IDIuMjQ3NTcyIDEuMjU1MjkzIDIuMzA3MzQ3IDEuMzE1MDY4IDIuMzA3MzQ3QzEuNDEwNzEgMi4zMDczNDcgMi4zMzEyNTggMS40MjI2NjUgMi4zMzEyNTggLjA0NzgyMVonLz4KPHBhdGggaWQ9J2c0NC02MCcgZD0nTTcuODc4NDU2LTUuODIyMTY3QzguMDkzNjQ5LTUuOTE3ODA4IDguMTE3NTU5LTYuMDAxNDk0IDguMTE3NTU5LTYuMDczMjI1QzguMTE3NTU5LTYuMjA0NzMyIDguMDIxOTE4LTYuMzAwMzc0IDcuODkwNDExLTYuMzAwMzc0QzcuODY2NTAxLTYuMzAwMzc0IDcuODU0NTQ1LTYuMjg4NDE4IDcuNjg3MTczLTYuMjE2Njg3TDEuMjE5NDI3LTMuMjM5ODUxQzEuMDA0MjM0LTMuMTQ0MjA5IC45ODAzMjQtMy4wNjA1MjMgLjk4MDMyNC0yLjk4ODc5MkMuOTgwMzI0LTIuOTA1MTA2IC45OTIyNzktMi44MzMzNzUgMS4yMTk0MjctMi43MjU3NzhMNy42ODcxNzMgLjI1MTA1OUM3Ljg0MjU5IC4zMjI3OSA3Ljg2NjUwMSAuMzM0NzQ1IDcuODkwNDExIC4zMzQ3NDVDOC4wMjE5MTggLjMzNDc0NSA4LjExNzU1OSAuMjM5MTAzIDguMTE3NTU5IC4xMDc1OTdDOC4xMTc1NTkgLjAzNTg2NiA4LjA5MzY0OS0uMDQ3ODIxIDcuODc4NDU2LS4xNDM0NjJMMS43MjE1NDQtMi45NzY4MzdMNy44Nzg0NTYtNS44MjIxNjdaJy8+CjxwYXRoIGlkPSdnNDQtNjInIGQ9J003Ljg3ODQ1Ni0yLjcyNTc3OEM4LjEwNTYwNC0yLjgzMzM3NSA4LjExNzU1OS0yLjkwNTEwNiA4LjExNzU1OS0yLjk4ODc5MkM4LjExNzU1OS0zLjA2MDUyMyA4LjA5MzY0OS0zLjE0NDIwOSA3Ljg3ODQ1Ni0zLjIzOTg1MUwxLjQxMDcxLTYuMjE2Njg3QzEuMjU1MjkzLTYuMjg4NDE4IDEuMjMxMzgyLTYuMzAwMzc0IDEuMjA3NDcyLTYuMzAwMzc0QzEuMDY0MDEtNi4zMDAzNzQgLjk4MDMyNC02LjE4MDgyMiAuOTgwMzI0LTYuMDg1MTgxQy45ODAzMjQtNS45NDE3MTkgMS4wNzU5NjUtNS44OTM4OTggMS4yMzEzODItNS44MjIxNjdMNy4zNzYzMzktMi45ODg3OTJMMS4yMTk0MjctLjE0MzQ2MkMuOTgwMzI0LS4wMzU4NjYgLjk4MDMyNCAuMDQ3ODIxIC45ODAzMjQgLjExOTU1MkMuOTgwMzI0IC4yMTUxOTMgMS4wNjQwMSAuMzM0NzQ1IDEuMjA3NDcyIC4zMzQ3NDVDMS4yMzEzODIgLjMzNDc0NSAxLjI0MzMzNyAuMzIyNzkgMS40MTA3MSAuMjUxMDU5TDcuODc4NDU2LTIuNzI1Nzc4WicvPgo8cGF0aCBpZD0nZzQ0LTY2JyBkPSdNNC4zNzU1OTItNy4zNTI0MjhDNC40ODMxODgtNy43OTQ3NyA0LjUzMTAwOS03LjgxODY4IDQuOTk3MjYtNy44MTg2OEg2LjU1MTQzMkM3LjkwMjM2Ni03LjgxODY4IDcuOTAyMzY2LTYuNjcwOTg0IDcuOTAyMzY2LTYuNTYzMzg3QzcuOTAyMzY2LTUuNTk1MDE5IDYuOTMzOTk4LTQuMzYzNjM2IDUuMzU1OTE1LTQuMzYzNjM2SDMuNjM0MzcxTDQuMzc1NTkyLTcuMzUyNDI4Wk02LjM5NjAxNS00LjI2Nzk5NUM3LjY5OTEyOC00LjUwNzA5OCA4Ljg4MjY5LTUuNDE1NjkxIDguODgyNjktNi41MTU1NjdDOC44ODI2OS03LjQ0ODA3IDguMDU3NzgzLTguMTY1MzggNi43MDY4NDktOC4xNjUzOEgyLjg2OTI0QzIuNjQyMDkyLTguMTY1MzggMi41MzQ0OTYtOC4xNjUzOCAyLjUzNDQ5Ni03LjkzODIzMkMyLjUzNDQ5Ni03LjgxODY4IDIuNjQyMDkyLTcuODE4NjggMi44MjE0Mi03LjgxODY4QzMuNTUwNjg1LTcuODE4NjggMy41NTA2ODUtNy43MjMwMzkgMy41NTA2ODUtNy41OTE1MzJDMy41NTA2ODUtNy41Njc2MjEgMy41NTA2ODUtNy40OTU4OSAzLjUwMjg2NC03LjMxNjU2M0wxLjg4ODkxNy0uODg0NjgyQzEuNzgxMzItLjQ2NjI1MiAxLjc1NzQxLS4zNDY3IC45MjA1NDgtLjM0NjdDLjY5MzQtLjM0NjcgLjU3Mzg0OC0uMzQ2NyAuNTczODQ4LS4xMzE1MDdDLjU3Mzg0OCAwIC42NDU1NzkgMCAuODg0NjgyIDBINC45ODUzMDVDNi44MTQ0NDYgMCA4LjIyNTE1Ni0xLjM4NjggOC4yMjUxNTYtMi41OTQyNzFDOC4yMjUxNTYtMy41NzQ1OTUgNy4zNjQzODQtNC4xNzIzNTQgNi4zOTYwMTUtNC4yNjc5OTVaTTQuNjk4MzgxLS4zNDY3SDMuMDg0NDMzQzIuOTE3MDYxLS4zNDY3IDIuODkzMTUxLS4zNDY3IDIuODIxNDItLjM1ODY1NUMyLjY4OTkxMy0uMzcwNjEgMi42Nzc5NTgtLjM5NDUyMSAyLjY3Nzk1OC0uNDkwMTYyQzIuNjc3OTU4LS41NzM4NDggMi43MDE4NjgtLjY0NTU3OSAyLjcyNTc3OC0uNzUzMTc2TDMuNTYyNjQtNC4xMjQ1MzNINS44MTAyMTJDNy4yMjA5MjItNC4xMjQ1MzMgNy4yMjA5MjItMi44MDk0NjUgNy4yMjA5MjItMi43MTM4MjNDNy4yMjA5MjItMS41NjYxMjcgNi4xODA4MjItLjM0NjcgNC42OTgzODEtLjM0NjdaJy8+CjxwYXRoIGlkPSdnNDQtNzEnIGQ9J004LjkxODU1NS04LjMwODg0MkM4LjkxODU1NS04LjQxNjQzOCA4LjgzNDg2OS04LjQxNjQzOCA4LjgxMDk1OS04LjQxNjQzOFM4LjczOTIyOC04LjQxNjQzOCA4LjY0MzU4Ny04LjI5Njg4N0w3LjgxODY4LTcuMzA0NjA4QzcuNzU4OTA0LTcuNDAwMjQ5IDcuNTE5ODAxLTcuODE4NjggNy4wNTM1NDktOC4wOTM2NDlDNi41Mzk0NzctOC40MTY0MzggNi4wMjU0MDUtOC40MTY0MzggNS44NDYwNzctOC40MTY0MzhDMy4yODc2NzEtOC40MTY0MzggLjU5Nzc1OC01LjgxMDIxMiAuNTk3NzU4LTIuOTg4NzkyQy41OTc3NTgtMS4wMTYxODkgMS45NjA2NDggLjI1MTA1OSAzLjc1MzkyMyAuMjUxMDU5QzQuNjE0Njk1IC4yNTEwNTkgNS43MDI2MTUtLjAzNTg2NiA2LjMwMDM3NC0uNzg5MDQxQzYuNDMxODgtLjMzNDc0NSA2LjY5NDg5NC0uMDExOTU1IDYuNzc4NTgtLjAxMTk1NUM2LjgzODM1Ni0uMDExOTU1IDYuODUwMzExLS4wNDc4MjEgNi44NjIyNjctLjA0NzgyMUM2Ljg3NDIyMi0uMDcxNzMxIDYuOTY5ODYzLS40OTAxNjIgNy4wMjk2MzktLjcwNTM1NUw3LjIyMDkyMi0xLjQ3MDQ4NkM3LjMxNjU2My0xLjg2NTAwNiA3LjM2NDM4NC0yLjAzMjM3OSA3LjQ0ODA3LTIuMzkxMDM0QzcuNTY3NjIxLTIuODQ1MzMgNy41OTE1MzItMi44ODExOTYgOC4yNDkwNjYtMi44OTMxNTFDOC4yOTY4ODctMi44OTMxNTEgOC40NDAzNDktMi44OTMxNTEgOC40NDAzNDktMy4xMjAyOTlDOC40NDAzNDktMy4yMzk4NTEgOC4zMjA3OTctMy4yMzk4NTEgOC4yODQ5MzItMy4yMzk4NTFDOC4wODE2OTQtMy4yMzk4NTEgNy44NTQ1NDUtMy4yMTU5NCA3LjYzOTM1Mi0zLjIxNTk0SDYuOTkzNzczQzYuNDkxNjU2LTMuMjE1OTQgNS45NjU2MjktMy4yMzk4NTEgNS40NzU0NjctMy4yMzk4NTFDNS4zNjc4Ny0zLjIzOTg1MSA1LjIyNDQwOC0zLjIzOTg1MSA1LjIyNDQwOC0zLjAyNDY1OEM1LjIyNDQwOC0yLjkwNTEwNiA1LjMyMDA1LTIuOTA1MTA2IDUuMzIwMDUtMi44OTMxNTFINS42MTg5MjlDNi41NjMzODctMi44OTMxNTEgNi41NjMzODctMi43OTc1MDkgNi41NjMzODctMi42MTgxODJDNi41NjMzODctMi42MDYyMjcgNi4zMzYyMzktMS4zOTg3NTUgNi4xMDkwOTEtMS4wNDAxQzUuNjU0Nzk1LS4zNzA2MSA0LjcxMDMzNi0uMDk1NjQxIDQuMDA0OTgxLS4wOTU2NDFDMy4wODQ0MzMtLjA5NTY0MSAxLjU5MDAzNy0uNTczODQ4IDEuNTkwMDM3LTIuNjQyMDkyQzEuNTkwMDM3LTMuNDQzMDg4IDEuODc2OTYxLTUuMjcyMjI5IDMuMDM2NjEzLTYuNjIzMTYzQzMuNzg5Nzg4LTcuNDgzOTM1IDQuOTAxNjE5LTguMDY5NzM4IDUuOTUzNjc0LTguMDY5NzM4QzcuMzY0Mzg0LTguMDY5NzM4IDcuODY2NTAxLTYuODYyMjY3IDcuODY2NTAxLTUuNzYyMzkxQzcuODY2NTAxLTUuNTcxMTA4IDcuODE4NjgtNS4zMDgwOTUgNy44MTg2OC01LjE0MDcyMkM3LjgxODY4LTUuMDMzMTI2IDcuOTM4MjMyLTUuMDMzMTI2IDcuOTc0MDk3LTUuMDMzMTI2QzguMTA1NjA0LTUuMDMzMTI2IDguMTE3NTU5LTUuMDQ1MDgxIDguMTY1MzgtNS4yNjAyNzRMOC45MTg1NTUtOC4zMDg4NDJaJy8+CjxwYXRoIGlkPSdnNDQtNzMnIGQ9J000LjM5OTUwMi03LjI4MDY5N0M0LjUwNzA5OC03LjY5OTEyOCA0LjUzMTAwOS03LjgxODY4IDUuNDAzNzM2LTcuODE4NjhDNS42NjY3NS03LjgxODY4IDUuNzYyMzkxLTcuODE4NjggNS43NjIzOTEtOC4wNDU4MjhDNS43NjIzOTEtOC4xNjUzOCA1LjYzMDg4NC04LjE2NTM4IDUuNTk1MDE5LTguMTY1MzhDNS4zNzk4MjYtOC4xNjUzOCA1LjExNjgxMi04LjE0MTQ2OSA0LjkwMTYxOS04LjE0MTQ2OUgzLjQzMTEzM0MzLjE5MjAzLTguMTQxNDY5IDIuOTE3MDYxLTguMTY1MzggMi42Nzc5NTgtOC4xNjUzOEMyLjU4MjMxNi04LjE2NTM4IDIuNDUwODA5LTguMTY1MzggMi40NTA4MDktNy45MzgyMzJDMi40NTA4MDktNy44MTg2OCAyLjU0NjQ1MS03LjgxODY4IDIuNzg1NTU0LTcuODE4NjhDMy41MjY3NzUtNy44MTg2OCAzLjUyNjc3NS03LjcyMzAzOSAzLjUyNjc3NS03LjU5MTUzMkMzLjUyNjc3NS03LjUwNzg0NiAzLjUwMjg2NC03LjQzNjExNSAzLjQ3ODk1NC03LjMyODUxOEwxLjg2NTAwNi0uODg0NjgyQzEuNzU3NDEtLjQ2NjI1MiAxLjczMzQ5OS0uMzQ2NyAuODYwNzcyLS4zNDY3Qy41OTc3NTgtLjM0NjcgLjQ5MDE2Mi0uMzQ2NyAuNDkwMTYyLS4xMTk1NTJDLjQ5MDE2MiAwIC42MDk3MTQgMCAuNjY5NDg5IDBDLjg4NDY4MiAwIDEuMTQ3Njk2LS4wMjM5MSAxLjM2Mjg4OS0uMDIzOTFIMi44MzMzNzVDMy4wNzI0NzgtLjAyMzkxIDMuMzM1NDkyIDAgMy41NzQ1OTUgMEMzLjY3MDIzNyAwIDMuODEzNjk5IDAgMy44MTM2OTktLjIxNTE5M0MzLjgxMzY5OS0uMzQ2NyAzLjc0MTk2OC0uMzQ2NyAzLjQ3ODk1NC0uMzQ2N0MyLjczNzczMy0uMzQ2NyAyLjczNzczMy0uNDQyMzQxIDIuNzM3NzMzLS41ODU4MDNDMi43Mzc3MzMtLjYwOTcxNCAyLjczNzczMy0uNjY5NDg5IDIuNzg1NTU0LS44NjA3NzJMNC4zOTk1MDItNy4yODA2OTdaJy8+CjxwYXRoIGlkPSdnNDQtNzYnIGQ9J000LjM4NzU0Ny03LjI0NDgzMkM0LjQ5NTE0My03LjY5OTEyOCA0LjUzMTAwOS03LjgxODY4IDUuNTgzMDY0LTcuODE4NjhDNS45MDU4NTMtNy44MTg2OCA1Ljk4OTUzOS03LjgxODY4IDUuOTg5NTM5LTguMDQ1ODI4QzUuOTg5NTM5LTguMTY1MzggNS44NTgwMzItOC4xNjUzOCA1LjgxMDIxMi04LjE2NTM4QzUuNTcxMTA4LTguMTY1MzggNS4yOTYxMzktOC4xNDE0NjkgNS4wNTcwMzYtOC4xNDE0NjlIMy40NTUwNDRDMy4yMjc4OTUtOC4xNDE0NjkgMi45NjQ4ODItOC4xNjUzOCAyLjczNzczMy04LjE2NTM4QzIuNjQyMDkyLTguMTY1MzggMi41MTA1ODUtOC4xNjUzOCAyLjUxMDU4NS03LjkzODIzMkMyLjUxMDU4NS03LjgxODY4IDIuNjE4MTgyLTcuODE4NjggMi43OTc1MDktNy44MTg2OEMzLjUyNjc3NS03LjgxODY4IDMuNTI2Nzc1LTcuNzIzMDM5IDMuNTI2Nzc1LTcuNTkxNTMyQzMuNTI2Nzc1LTcuNTY3NjIxIDMuNTI2Nzc1LTcuNDk1ODkgMy40Nzg5NTQtNy4zMTY1NjNMMS44NjUwMDYtLjg4NDY4MkMxLjc1NzQxLS40NjYyNTIgMS43MzM0OTktLjM0NjcgLjg5NjYzOC0uMzQ2N0MuNjY5NDg5LS4zNDY3IC41NDk5MzgtLjM0NjcgLjU0OTkzOC0uMTMxNTA3Qy41NDk5MzggMCAuNjIxNjY5IDAgLjg2MDc3MiAwSDYuMjE2Njg3QzYuNDc5NzAxIDAgNi40OTE2NTYtLjAxMTk1NSA2LjU3NTM0Mi0uMjI3MTQ4TDcuNDk1ODktMi43NzM1OTlDNy41MTk4MDEtMi44MzMzNzUgNy41NDM3MTEtMi45MDUxMDYgNy41NDM3MTEtMi45NDA5NzFDNy41NDM3MTEtMy4wMTI3MDIgNy40ODM5MzUtMy4wNjA1MjMgNy40MjQxNTktMy4wNjA1MjNDNy40MTIyMDQtMy4wNjA1MjMgNy4zNTI0MjgtMy4wNjA1MjMgNy4zMjg1MTgtMy4wMTI3MDJDNy4zMDQ2MDgtMy4wMDA3NDcgNy4zMDQ2MDgtMi45NzY4MzcgNy4yMDg5NjYtMi43NDk2ODlDNi44MjY0MDEtMS42OTc2MzQgNi4yODg0MTgtLjM0NjcgNC4yNjc5OTUtLjM0NjdIMy4xMjAyOTlDMi45NTI5MjctLjM0NjcgMi45MjkwMTYtLjM0NjcgMi44NTcyODUtLjM1ODY1NUMyLjcyNTc3OC0uMzcwNjEgMi43MTM4MjMtLjM5NDUyMSAyLjcxMzgyMy0uNDkwMTYyQzIuNzEzODIzLS41NzM4NDggMi43Mzc3MzMtLjY0NTU3OSAyLjc2MTY0NC0uNzUzMTc2TDQuMzg3NTQ3LTcuMjQ0ODMyWicvPgo8cGF0aCBpZD0nZzQ0LTc3JyBkPSdNMTAuODU1MjkzLTcuMjkyNjUzQzEwLjk2Mjg4OS03LjY5OTEyOCAxMC45ODY4LTcuODE4NjggMTEuODM1NjE2LTcuODE4NjhDMTIuMDYyNzY1LTcuODE4NjggMTIuMTcwMzYxLTcuODE4NjggMTIuMTcwMzYxLTguMDQ1ODI4QzEyLjE3MDM2MS04LjE2NTM4IDEyLjA4NjY3NS04LjE2NTM4IDExLjg1OTUyNy04LjE2NTM4SDEwLjQyNDkwN0MxMC4xMjYwMjctOC4xNjUzOCAxMC4xMTQwNzItOC4xNTM0MjUgOS45ODI1NjUtNy45NjIxNDJMNS42MTg5MjktMS4wNjQwMUw0LjcyMjI5MS03LjkwMjM2NkM0LjY4NjQyNi04LjE2NTM4IDQuNjc0NDcxLTguMTY1MzggNC4zNjM2MzYtOC4xNjUzOEgyLjg4MTE5NkMyLjY1NDA0Ny04LjE2NTM4IDIuNTQ2NDUxLTguMTY1MzggMi41NDY0NTEtNy45MzgyMzJDMi41NDY0NTEtNy44MTg2OCAyLjY1NDA0Ny03LjgxODY4IDIuODMzMzc1LTcuODE4NjhDMy41NjI2NC03LjgxODY4IDMuNTYyNjQtNy43MjMwMzkgMy41NjI2NC03LjU5MTUzMkMzLjU2MjY0LTcuNTY3NjIxIDMuNTYyNjQtNy40OTU4OSAzLjUxNDgxOS03LjMxNjU2M0wxLjk4NDU1OC0xLjIxOTQyN0MxLjg0MTA5Ni0uNjQ1NTc5IDEuNTY2MTI3LS4zODI1NjUgLjc2NTEzMS0uMzQ2N0MuNzI5MjY1LS4zNDY3IC41ODU4MDMtLjMzNDc0NSAuNTg1ODAzLS4xMzE1MDdDLjU4NTgwMyAwIC42OTM0IDAgLjc0MTIyIDBDLjk4MDMyNCAwIDEuNTkwMDM3LS4wMjM5MSAxLjgyOTE0MS0uMDIzOTFIMi40MDI5ODlDMi41NzAzNjEtLjAyMzkxIDIuNzczNTk5IDAgMi45NDA5NzEgMEMzLjAyNDY1OCAwIDMuMTU2MTY0IDAgMy4xNTYxNjQtLjIyNzE0OEMzLjE1NjE2NC0uMzM0NzQ1IDMuMDM2NjEzLS4zNDY3IDIuOTg4NzkyLS4zNDY3QzIuNTk0MjcxLS4zNTg2NTUgMi4yMTE3MDYtLjQzMDM4NiAyLjIxMTcwNi0uODYwNzcyQzIuMjExNzA2LS45ODAzMjQgMi4yMTE3MDYtLjk5MjI3OSAyLjI1OTUyNy0xLjE1OTY1MUwzLjkwOTM0LTcuNzQ2OTQ5SDMuOTIxMjk1TDQuOTEzNTc0LS4zMjI3OUM0Ljk0OTQ0LS4wMzU4NjYgNC45NjEzOTUgMCA1LjA2ODk5MSAwQzUuMjAwNDk4IDAgNS4yNjAyNzQtLjA5NTY0MSA1LjMyMDA1LS4yMDMyMzhMMTAuMTI2MDI3LTcuODA2NzI1SDEwLjEzNzk4M0w4LjQwNDQ4My0uODg0NjgyQzguMjk2ODg3LS40NjYyNTIgOC4yNzI5NzYtLjM0NjcgNy40MzYxMTUtLjM0NjdDNy4yMDg5NjYtLjM0NjcgNy4wODk0MTUtLjM0NjcgNy4wODk0MTUtLjEzMTUwN0M3LjA4OTQxNSAwIDcuMTk3MDExIDAgNy4yNjg3NDIgMEM3LjQ3MTk4IDAgNy43MTEwODMtLjAyMzkxIDcuOTE0MzIxLS4wMjM5MUg5LjMyNTAzMUM5LjUyODI2OS0uMDIzOTEgOS43NzkzMjggMCA5Ljk4MjU2NSAwQzEwLjA3ODIwNyAwIDEwLjIwOTcxNCAwIDEwLjIwOTcxNC0uMjI3MTQ4QzEwLjIwOTcxNC0uMzQ2NyAxMC4xMDIxMTctLjM0NjcgOS45MjI3OS0uMzQ2N0M5LjE5MzUyNC0uMzQ2NyA5LjE5MzUyNC0uNDQyMzQxIDkuMTkzNTI0LS41NjE4OTNDOS4xOTM1MjQtLjU3Mzg0OCA5LjE5MzUyNC0uNjU3NTM0IDkuMjE3NDM1LS43NTMxNzZMMTAuODU1MjkzLTcuMjkyNjUzWicvPgo8cGF0aCBpZD0nZzQ0LTgwJyBkPSdNMy41Mzg3My0zLjgwMTc0M0g1LjU0NzE5OEM3LjE5NzAxMS0zLjgwMTc0MyA4Ljg0NjgyNC01LjAyMTE3MSA4Ljg0NjgyNC02LjM4NDA2QzguODQ2ODI0LTcuMzE2NTYzIDguMDU3NzgzLTguMTY1MzggNi41NTE0MzItOC4xNjUzOEgyLjg1NzI4NUMyLjYzMDEzNy04LjE2NTM4IDIuNTIyNTQtOC4xNjUzOCAyLjUyMjU0LTcuOTM4MjMyQzIuNTIyNTQtNy44MTg2OCAyLjYzMDEzNy03LjgxODY4IDIuODA5NDY1LTcuODE4NjhDMy41Mzg3My03LjgxODY4IDMuNTM4NzMtNy43MjMwMzkgMy41Mzg3My03LjU5MTUzMkMzLjUzODczLTcuNTY3NjIxIDMuNTM4NzMtNy40OTU4OSAzLjQ5MDkwOS03LjMxNjU2M0wxLjg3Njk2MS0uODg0NjgyQzEuNzY5MzY1LS40NjYyNTIgMS43NDU0NTUtLjM0NjcgLjkwODU5My0uMzQ2N0MuNjgxNDQ1LS4zNDY3IC41NjE4OTMtLjM0NjcgLjU2MTg5My0uMTMxNTA3Qy41NjE4OTMgMCAuNjY5NDg5IDAgLjc0MTIyIDBDLjk2ODM2OSAwIDEuMjA3NDcyLS4wMjM5MSAxLjQzNDYyLS4wMjM5MUgyLjgzMzM3NUMzLjA2MDUyMy0uMDIzOTEgMy4zMTE1ODIgMCAzLjUzODczIDBDMy42MzQzNzEgMCAzLjc2NTg3OCAwIDMuNzY1ODc4LS4yMjcxNDhDMy43NjU4NzgtLjM0NjcgMy42NTgyODEtLjM0NjcgMy40Nzg5NTQtLjM0NjdDMi43NjE2NDQtLjM0NjcgMi43NDk2ODktLjQzMDM4NiAyLjc0OTY4OS0uNTQ5OTM4QzIuNzQ5Njg5LS42MDk3MTQgMi43NjE2NDQtLjY5MzQgMi43NzM1OTktLjc1MzE3NkwzLjUzODczLTMuODAxNzQzWk00LjM5OTUwMi03LjM1MjQyOEM0LjUwNzA5OC03Ljc5NDc3IDQuNTU0OTE5LTcuODE4NjggNS4wMjExNzEtNy44MTg2OEg2LjIwNDczMkM3LjEwMTM3LTcuODE4NjggNy44NDI1OS03LjUzMTc1NiA3Ljg0MjU5LTYuNjM1MTE4QzcuODQyNTktNi4zMjQyODQgNy42ODcxNzMtNS4zMDgwOTUgNy4xMzcyMzUtNC43NTgxNTdDNi45MzM5OTgtNC41NDI5NjQgNi4zNjAxNDktNC4wODg2NjcgNS4yNzIyMjktNC4wODg2NjdIMy41ODY1NUw0LjM5OTUwMi03LjM1MjQyOFonLz4KPHBhdGggaWQ9J2c0NC05NycgZD0nTTMuNTk4NTA2LTEuNDIyNjY1QzMuNTM4NzMtMS4yMTk0MjcgMy41Mzg3My0xLjE5NTUxNyAzLjM3MTM1Ny0uOTY4MzY5QzMuMTA4MzQ0LS42MzM2MjQgMi41ODIzMTYtLjExOTU1MiAyLjAyMDQyMy0uMTE5NTUyQzEuNTMwMjYyLS4xMTk1NTIgMS4yNTUyOTMtLjU2MTg5MyAxLjI1NTI5My0xLjI2NzI0OEMxLjI1NTI5My0xLjkyNDc4MiAxLjYyNTkwMy0zLjI2Mzc2MSAxLjg1MzA1MS0zLjc2NTg3OEMyLjI1OTUyNy00LjYwMjc0IDIuODIxNDItNS4wMzMxMjYgMy4yODc2NzEtNS4wMzMxMjZDNC4wNzY3MTItNS4wMzMxMjYgNC4yMzIxMy00LjA1MjgwMiA0LjIzMjEzLTMuOTU3MTYxQzQuMjMyMTMtMy45NDUyMDUgNC4xOTYyNjQtMy43ODk3ODggNC4xODQzMDktMy43NjU4NzhMMy41OTg1MDYtMS40MjI2NjVaTTQuMzYzNjM2LTQuNDgzMTg4QzQuMjMyMTMtNC43OTQwMjIgMy45MDkzNC01LjI3MjIyOSAzLjI4NzY3MS01LjI3MjIyOUMxLjkzNjczNy01LjI3MjIyOSAuNDc4MjA3LTMuNTI2Nzc1IC40NzgyMDctMS43NTc0MUMuNDc4MjA3LS41NzM4NDggMS4xNzE2MDYgLjExOTU1MiAxLjk4NDU1OCAuMTE5NTUyQzIuNjQyMDkyIC4xMTk1NTIgMy4yMDM5ODUtLjM5NDUyMSAzLjUzODczLS43ODkwNDFDMy42NTgyODEtLjA4MzY4NiA0LjIyMDE3NCAuMTE5NTUyIDQuNTc4ODI5IC4xMTk1NTJTNS4yMjQ0MDgtLjA5NTY0MSA1LjQzOTYwMS0uNTI2MDI3QzUuNjMwODg0LS45MzI1MDMgNS43OTgyNTctMS42NjE3NjggNS43OTgyNTctMS43MDk1ODlDNS43OTgyNTctMS43NjkzNjUgNS43NTA0MzYtMS44MTcxODYgNS42Nzg3MDUtMS44MTcxODZDNS41NzExMDgtMS44MTcxODYgNS41NTkxNTMtMS43NTc0MSA1LjUxMTMzMy0xLjU3ODA4MkM1LjMzMjAwNS0uODcyNzI3IDUuMTA0ODU3LS4xMTk1NTIgNC42MTQ2OTUtLjExOTU1MkM0LjI2Nzk5NS0uMTE5NTUyIDQuMjQ0MDg1LS40MzAzODYgNC4yNDQwODUtLjY2OTQ4OUM0LjI0NDA4NS0uOTQ0NDU4IDQuMjc5OTUtMS4wNzU5NjUgNC4zODc1NDctMS41NDIyMTdDNC40NzEyMzMtMS44NDEwOTYgNC41MzEwMDktMi4xMDQxMSA0LjYyNjY1LTIuNDUwODA5QzUuMDY4OTkxLTQuMjQ0MDg1IDUuMTc2NTg4LTQuNjc0NDcxIDUuMTc2NTg4LTQuNzQ2MjAyQzUuMTc2NTg4LTQuOTEzNTc0IDUuMDQ1MDgxLTUuMDQ1MDgxIDQuODY1NzUzLTUuMDQ1MDgxQzQuNDgzMTg4LTUuMDQ1MDgxIDQuMzg3NTQ3LTQuNjI2NjUgNC4zNjM2MzYtNC40ODMxODhaJy8+CjxwYXRoIGlkPSdnNDQtOTgnIGQ9J00yLjc2MTY0NC03Ljk5ODAwN0MyLjc3MzU5OS04LjA0NTgyOCAyLjc5NzUwOS04LjExNzU1OSAyLjc5NzUwOS04LjE3NzMzNUMyLjc5NzUwOS04LjI5Njg4NyAyLjY3Nzk1OC04LjI5Njg4NyAyLjY1NDA0Ny04LjI5Njg4N0MyLjY0MjA5Mi04LjI5Njg4NyAyLjIxMTcwNi04LjI2MTAyMSAxLjk5NjUxMy04LjIzNzExMUMxLjc5MzI3NS04LjIyNTE1NiAxLjYxMzk0OC04LjIwMTI0NSAxLjM5ODc1NS04LjE4OTI5QzEuMTExODMxLTguMTY1MzggMS4wMjgxNDQtOC4xNTM0MjUgMS4wMjgxNDQtNy45MzgyMzJDMS4wMjgxNDQtNy44MTg2OCAxLjE0NzY5Ni03LjgxODY4IDEuMjY3MjQ4LTcuODE4NjhDMS44NzY5NjEtNy44MTg2OCAxLjg3Njk2MS03LjcxMTA4MyAxLjg3Njk2MS03LjU5MTUzMkMxLjg3Njk2MS03LjUwNzg0NiAxLjc4MTMyLTcuMTYxMTQ2IDEuNzMzNDk5LTYuOTQ1OTUzTDEuNDQ2NTc1LTUuNzk4MjU3QzEuMzI3MDI0LTUuMzIwMDUgLjY0NTU3OS0yLjYwNjIyNyAuNTk3NzU4LTIuMzkxMDM0Qy41Mzc5ODMtMi4wOTIxNTQgLjUzNzk4My0xLjg4ODkxNyAuNTM3OTgzLTEuNzMzNDk5Qy41Mzc5ODMtLjUxNDA3MiAxLjIxOTQyNyAuMTE5NTUyIDEuOTk2NTEzIC4xMTk1NTJDMy4zODMzMTMgLjExOTU1MiA0LjgxNzkzMy0xLjY2MTc2OCA0LjgxNzkzMy0zLjM5NTI2OEM0LjgxNzkzMy00LjQ5NTE0MyA0LjE5NjI2NC01LjI3MjIyOSAzLjI5OTYyNi01LjI3MjIyOUMyLjY3Nzk1OC01LjI3MjIyOSAyLjExNjA2NS00Ljc1ODE1NyAxLjg4ODkxNy00LjUxOTA1NEwyLjc2MTY0NC03Ljk5ODAwN1pNMi4wMDg0NjgtLjExOTU1MkMxLjYyNTkwMy0uMTE5NTUyIDEuMjA3NDcyLS40MDY0NzYgMS4yMDc0NzItMS4zMzg5NzlDMS4yMDc0NzItMS43MzM0OTkgMS4yNDMzMzctMS45NjA2NDggMS40NTg1MzEtMi43OTc1MDlDMS40OTQzOTYtMi45NTI5MjcgMS42ODU2NzktMy43MTgwNTcgMS43MzM0OTktMy44NzM0NzRDMS43NTc0MS0zLjk2OTExNiAyLjQ2Mjc2NS01LjAzMzEyNiAzLjI3NTcxNi01LjAzMzEyNkMzLjgwMTc0My01LjAzMzEyNiA0LjA0MDg0Ny00LjUwNzA5OCA0LjA0MDg0Ny0zLjg4NTQzQzQuMDQwODQ3LTMuMzExNTgyIDMuNzA2MTAyLTEuOTYwNjQ4IDMuNDA3MjIzLTEuMzM4OTc5QzMuMTA4MzQ0LS42OTM0IDIuNTU4NDA2LS4xMTk1NTIgMi4wMDg0NjgtLjExOTU1MlonLz4KPHBhdGggaWQ9J2c0NC05OScgZD0nTTQuNjc0NDcxLTQuNDk1MTQzQzQuNDQ3MzIzLTQuNDk1MTQzIDQuMzM5NzI2LTQuNDk1MTQzIDQuMTcyMzU0LTQuMzUxNjgxQzQuMTAwNjIzLTQuMjkxOTA1IDMuOTY5MTE2LTQuMTEyNTc4IDMuOTY5MTE2LTMuOTIxMjk1QzMuOTY5MTE2LTMuNjgyMTkyIDQuMTQ4NDQzLTMuNTM4NzMgNC4zNzU1OTItMy41Mzg3M0M0LjY2MjUxNi0zLjUzODczIDQuOTg1MzA1LTMuNzc3ODMzIDQuOTg1MzA1LTQuMjU2MDRDNC45ODUzMDUtNC44Mjk4ODggNC40MzUzNjctNS4yNzIyMjkgMy42MTA0NjEtNS4yNzIyMjlDMi4wNDQzMzQtNS4yNzIyMjkgLjQ3ODIwNy0zLjU2MjY0IC40NzgyMDctMS44NjUwMDZDLjQ3ODIwNy0uODI0OTA3IDEuMTIzNzg2IC4xMTk1NTIgMi4zNDMyMTMgLjExOTU1MkMzLjk2OTExNiAuMTE5NTUyIDQuOTk3MjYtMS4xNDc2OTYgNC45OTcyNi0xLjMwMzExM0M0Ljk5NzI2LTEuMzc0ODQ0IDQuOTI1NTI5LTEuNDM0NjIgNC44Nzc3MDktMS40MzQ2MkM0Ljg0MTg0My0xLjQzNDYyIDQuODI5ODg4LTEuNDIyNjY1IDQuNzIyMjkxLTEuMzE1MDY4QzMuOTU3MTYxLS4yOTg4NzkgMi44MjE0Mi0uMTE5NTUyIDIuMzY3MTIzLS4xMTk1NTJDMS41NDIyMTctLjExOTU1MiAxLjI3OTIwMy0uODM2ODYyIDEuMjc5MjAzLTEuNDM0NjJDMS4yNzkyMDMtMS44NTMwNTEgMS40ODI0NDEtMy4wMTI3MDIgMS45MTI4MjctMy44MjU2NTRDMi4yMjM2NjEtNC4zODc1NDcgMi44NjkyNC01LjAzMzEyNiAzLjYyMjQxNi01LjAzMzEyNkMzLjc3NzgzMy01LjAzMzEyNiA0LjQzNTM2Ny01LjAwOTIxNSA0LjY3NDQ3MS00LjQ5NTE0M1onLz4KPHBhdGggaWQ9J2c0NC0xMDAnIGQ9J002LjAxMzQ1LTcuOTk4MDA3QzYuMDI1NDA1LTguMDQ1ODI4IDYuMDQ5MzE1LTguMTE3NTU5IDYuMDQ5MzE1LTguMTc3MzM1QzYuMDQ5MzE1LTguMjk2ODg3IDUuOTI5NzYzLTguMjk2ODg3IDUuOTA1ODUzLTguMjk2ODg3QzUuODkzODk4LTguMjk2ODg3IDUuMzA4MDk1LTguMjQ5MDY2IDUuMjQ4MzE5LTguMjM3MTExQzUuMDQ1MDgxLTguMjI1MTU2IDQuODY1NzUzLTguMjAxMjQ1IDQuNjUwNTYtOC4xODkyOUM0LjM1MTY4MS04LjE2NTM4IDQuMjY3OTk1LTguMTUzNDI1IDQuMjY3OTk1LTcuOTM4MjMyQzQuMjY3OTk1LTcuODE4NjggNC4zNjM2MzYtNy44MTg2OCA0LjUzMTAwOS03LjgxODY4QzUuMTE2ODEyLTcuODE4NjggNS4xMjg3NjctNy43MTEwODMgNS4xMjg3NjctNy41OTE1MzJDNS4xMjg3NjctNy41MTk4MDEgNS4xMDQ4NTctNy40MjQxNTkgNS4wOTI5MDItNy4zODgyOTRMNC4zNjM2MzYtNC40ODMxODhDNC4yMzIxMy00Ljc5NDAyMiAzLjkwOTM0LTUuMjcyMjI5IDMuMjg3NjcxLTUuMjcyMjI5QzEuOTM2NzM3LTUuMjcyMjI5IC40NzgyMDctMy41MjY3NzUgLjQ3ODIwNy0xLjc1NzQxQy40NzgyMDctLjU3Mzg0OCAxLjE3MTYwNiAuMTE5NTUyIDEuOTg0NTU4IC4xMTk1NTJDMi42NDIwOTIgLjExOTU1MiAzLjIwMzk4NS0uMzk0NTIxIDMuNTM4NzMtLjc4OTA0MUMzLjY1ODI4MS0uMDgzNjg2IDQuMjIwMTc0IC4xMTk1NTIgNC41Nzg4MjkgLjExOTU1MlM1LjIyNDQwOC0uMDk1NjQxIDUuNDM5NjAxLS41MjYwMjdDNS42MzA4ODQtLjkzMjUwMyA1Ljc5ODI1Ny0xLjY2MTc2OCA1Ljc5ODI1Ny0xLjcwOTU4OUM1Ljc5ODI1Ny0xLjc2OTM2NSA1Ljc1MDQzNi0xLjgxNzE4NiA1LjY3ODcwNS0xLjgxNzE4NkM1LjU3MTEwOC0xLjgxNzE4NiA1LjU1OTE1My0xLjc1NzQxIDUuNTExMzMzLTEuNTc4MDgyQzUuMzMyMDA1LS44NzI3MjcgNS4xMDQ4NTctLjExOTU1MiA0LjYxNDY5NS0uMTE5NTUyQzQuMjY3OTk1LS4xMTk1NTIgNC4yNDQwODUtLjQzMDM4NiA0LjI0NDA4NS0uNjY5NDg5QzQuMjQ0MDg1LS43MTczMSA0LjI0NDA4NS0uOTY4MzY5IDQuMzI3NzcxLTEuMzAzMTEzTDYuMDEzNDUtNy45OTgwMDdaTTMuNTk4NTA2LTEuNDIyNjY1QzMuNTM4NzMtMS4yMTk0MjcgMy41Mzg3My0xLjE5NTUxNyAzLjM3MTM1Ny0uOTY4MzY5QzMuMTA4MzQ0LS42MzM2MjQgMi41ODIzMTYtLjExOTU1MiAyLjAyMDQyMy0uMTE5NTUyQzEuNTMwMjYyLS4xMTk1NTIgMS4yNTUyOTMtLjU2MTg5MyAxLjI1NTI5My0xLjI2NzI0OEMxLjI1NTI5My0xLjkyNDc4MiAxLjYyNTkwMy0zLjI2Mzc2MSAxLjg1MzA1MS0zLjc2NTg3OEMyLjI1OTUyNy00LjYwMjc0IDIuODIxNDItNS4wMzMxMjYgMy4yODc2NzEtNS4wMzMxMjZDNC4wNzY3MTItNS4wMzMxMjYgNC4yMzIxMy00LjA1MjgwMiA0LjIzMjEzLTMuOTU3MTYxQzQuMjMyMTMtMy45NDUyMDUgNC4xOTYyNjQtMy43ODk3ODggNC4xODQzMDktMy43NjU4NzhMMy41OTg1MDYtMS40MjI2NjVaJy8+CjxwYXRoIGlkPSdnNDQtMTAxJyBkPSdNMi4xMzk5NzUtMi43NzM1OTlDMi40NjI3NjUtMi43NzM1OTkgMy4yNzU3MTYtMi43OTc1MDkgMy44NDk1NjQtMy4wMTI3MDJDNC43NTgxNTctMy4zNTk0MDIgNC44NDE4NDMtNC4wNTI4MDIgNC44NDE4NDMtNC4yNjc5OTVDNC44NDE4NDMtNC43OTQwMjIgNC4zODc1NDctNS4yNzIyMjkgMy41OTg1MDYtNS4yNzIyMjlDMi4zNDMyMTMtNS4yNzIyMjkgLjUzNzk4My00LjEzNjQ4OCAuNTM3OTgzLTIuMDA4NDY4Qy41Mzc5ODMtLjc1MzE3NiAxLjI1NTI5MyAuMTE5NTUyIDIuMzQzMjEzIC4xMTk1NTJDMy45NjkxMTYgLjExOTU1MiA0Ljk5NzI2LTEuMTQ3Njk2IDQuOTk3MjYtMS4zMDMxMTNDNC45OTcyNi0xLjM3NDg0NCA0LjkyNTUyOS0xLjQzNDYyIDQuODc3NzA5LTEuNDM0NjJDNC44NDE4NDMtMS40MzQ2MiA0LjgyOTg4OC0xLjQyMjY2NSA0LjcyMjI5MS0xLjMxNTA2OEMzLjk1NzE2MS0uMjk4ODc5IDIuODIxNDItLjExOTU1MiAyLjM2NzEyMy0uMTE5NTUyQzEuNjg1Njc5LS4xMTk1NTIgMS4zMjcwMjQtLjY1NzUzNCAxLjMyNzAyNC0xLjU0MjIxN0MxLjMyNzAyNC0xLjcwOTU4OSAxLjMyNzAyNC0yLjAwODQ2OCAxLjUwNjM1MS0yLjc3MzU5OUgyLjEzOTk3NVpNMS41NjYxMjctMy4wMTI3MDJDMi4wODAxOTktNC44NTM3OTggMy4yMTU5NC01LjAzMzEyNiAzLjU5ODUwNi01LjAzMzEyNkM0LjEyNDUzMy01LjAzMzEyNiA0LjQ4MzE4OC00LjcyMjI5MSA0LjQ4MzE4OC00LjI2Nzk5NUM0LjQ4MzE4OC0zLjAxMjcwMiAyLjU3MDM2MS0zLjAxMjcwMiAyLjA2ODI0NC0zLjAxMjcwMkgxLjU2NjEyN1onLz4KPHBhdGggaWQ9J2c0NC0xMDInIGQ9J001LjMzMjAwNS00LjgwNTk3OEM1LjU3MTEwOC00LjgwNTk3OCA1LjY2Njc1LTQuODA1OTc4IDUuNjY2NzUtNS4wMzMxMjZDNS42NjY3NS01LjE1MjY3NyA1LjU3MTEwOC01LjE1MjY3NyA1LjM1NTkxNS01LjE1MjY3N0g0LjM4NzU0N0M0LjYxNDY5NS02LjM4NDA2IDQuNzgyMDY3LTcuMjMyODc3IDQuODc3NzA5LTcuNjE1NDQyQzQuOTQ5NDQtNy45MDIzNjYgNS4yMDA0OTgtOC4xNzczMzUgNS41MTEzMzMtOC4xNzczMzVDNS43NjIzOTEtOC4xNzczMzUgNi4wMTM0NS04LjA2OTczOCA2LjEzMzAwMS03Ljk2MjE0MkM1LjY2Njc1LTcuOTE0MzIxIDUuNTIzMjg4LTcuNTY3NjIxIDUuNTIzMjg4LTcuMzY0Mzg0QzUuNTIzMjg4LTcuMTI1MjggNS43MDI2MTUtNi45ODE4MTggNS45Mjk3NjMtNi45ODE4MThDNi4xNjg4NjctNi45ODE4MTggNi41Mjc1MjItNy4xODUwNTYgNi41Mjc1MjItNy42MzkzNTJDNi41Mjc1MjItOC4xNDE0NjkgNi4wMjU0MDUtOC40MTY0MzggNS40OTkzNzctOC40MTY0MzhDNC45ODUzMDUtOC40MTY0MzggNC40ODMxODgtOC4wMzM4NzMgNC4yNDQwODUtNy41Njc2MjFDNC4wMjg4OTItNy4xNDkxOTEgMy45MDkzNC02LjcxODgwNCAzLjYzNDM3MS01LjE1MjY3N0gyLjgzMzM3NUMyLjYwNjIyNy01LjE1MjY3NyAyLjQ4NjY3NS01LjE1MjY3NyAyLjQ4NjY3NS00LjkzNzQ4NEMyLjQ4NjY3NS00LjgwNTk3OCAyLjU1ODQwNi00LjgwNTk3OCAyLjc5NzUwOS00LjgwNTk3OEgzLjU2MjY0QzMuMzQ3NDQ3LTMuNjk0MTQ3IDIuODU3Mjg1LS45OTIyNzkgMi41ODIzMTYgLjI4NjkyNEMyLjM3OTA3OCAxLjMyNzAyNCAyLjE5OTc1MSAyLjE5OTc1MSAxLjYwMTk5MyAyLjE5OTc1MUMxLjU2NjEyNyAyLjE5OTc1MSAxLjIxOTQyNyAyLjE5OTc1MSAxLjAwNDIzNCAxLjk3MjYwM0MxLjYxMzk0OCAxLjkyNDc4MiAxLjYxMzk0OCAxLjM5ODc1NSAxLjYxMzk0OCAxLjM4NjhDMS42MTM5NDggMS4xNDc2OTYgMS40MzQ2MiAxLjAwNDIzNCAxLjIwNzQ3MiAxLjAwNDIzNEMuOTY4MzY5IDEuMDA0MjM0IC42MDk3MTQgMS4yMDc0NzIgLjYwOTcxNCAxLjY2MTc2OEMuNjA5NzE0IDIuMTc1ODQxIDEuMTM1NzQxIDIuNDM4ODU0IDEuNjAxOTkzIDIuNDM4ODU0QzIuODIxNDIgMi40Mzg4NTQgMy4zMjM1MzcgLjI1MTA1OSAzLjQ1NTA0NC0uMzQ2N0MzLjY3MDIzNy0xLjI2NzI0OCA0LjI1NjA0LTQuNDQ3MzIzIDQuMzE1ODE2LTQuODA1OTc4SDUuMzMyMDA1WicvPgo8cGF0aCBpZD0nZzQ0LTEwMycgZD0nTTQuMDQwODQ3LTEuNTE4MzA2QzMuOTkzMDI2LTEuMzI3MDI0IDMuOTY5MTE2LTEuMjc5MjAzIDMuODEzNjk5LTEuMDk5ODc1QzMuMzIzNTM3LS40NjYyNTIgMi44MjE0Mi0uMjM5MTAzIDIuNDUwODA5LS4yMzkxMDNDMi4wNTYyODktLjIzOTEwMyAxLjY4NTY3OS0uNTQ5OTM4IDEuNjg1Njc5LTEuMzc0ODQ0QzEuNjg1Njc5LTIuMDA4NDY4IDIuMDQ0MzM0LTMuMzQ3NDQ3IDIuMzA3MzQ3LTMuODg1NDNDMi42NTQwNDctNC41NTQ5MTkgMy4xOTIwMy01LjAzMzEyNiAzLjY5NDE0Ny01LjAzMzEyNkM0LjQ4MzE4OC01LjAzMzEyNiA0LjYzODYwNS00LjA1MjgwMiA0LjYzODYwNS0zLjk4MTA3MUw0LjYwMjc0LTMuODEzNjk5TDQuMDQwODQ3LTEuNTE4MzA2Wk00Ljc4MjA2Ny00LjQ4MzE4OEM0LjYyNjY1LTQuODI5ODg4IDQuMjkxOTA1LTUuMjcyMjI5IDMuNjk0MTQ3LTUuMjcyMjI5QzIuMzkxMDM0LTUuMjcyMjI5IC45MDg1OTMtMy42MzQzNzEgLjkwODU5My0xLjg1MzA1MUMuOTA4NTkzLS42MDk3MTQgMS42NjE3NjggMCAyLjQyNjg5OSAwQzMuMDYwNTIzIDAgMy42MjI0MTYtLjUwMjExNyAzLjgzNzYwOS0uNzQxMjJMMy41NzQ1OTUgLjMzNDc0NUMzLjQwNzIyMyAuOTkyMjc5IDMuMzM1NDkyIDEuMjkxMTU4IDIuOTA1MTA2IDEuNzA5NTg5QzIuNDE0OTQ0IDIuMTk5NzUxIDEuOTYwNjQ4IDIuMTk5NzUxIDEuNjk3NjM0IDIuMTk5NzUxQzEuMzM4OTc5IDIuMTk5NzUxIDEuMDQwMSAyLjE3NTg0MSAuNzQxMjIgMi4wODAxOTlDMS4xMjM3ODYgMS45NzI2MDMgMS4yMTk0MjcgMS42Mzc4NTggMS4yMTk0MjcgMS41MDYzNTFDMS4yMTk0MjcgMS4zMTUwNjggMS4wNzU5NjUgMS4xMjM3ODYgLjgxMjk1MSAxLjEyMzc4NkMuNTI2MDI3IDEuMTIzNzg2IC4yMTUxOTMgMS4zNjI4ODkgLjIxNTE5MyAxLjc1NzQxQy4yMTUxOTMgMi4yNDc1NzIgLjcwNTM1NSAyLjQzODg1NCAxLjcyMTU0NCAyLjQzODg1NEMzLjI2Mzc2MSAyLjQzODg1NCA0LjA2NDc1NyAxLjQ0NjU3NSA0LjIyMDE3NCAuODAwOTk2TDUuNTQ3MTk4LTQuNTU0OTE5QzUuNTgzMDY0LTQuNjk4MzgxIDUuNTgzMDY0LTQuNzIyMjkxIDUuNTgzMDY0LTQuNzQ2MjAyQzUuNTgzMDY0LTQuOTEzNTc0IDUuNDUxNTU3LTUuMDQ1MDgxIDUuMjcyMjI5LTUuMDQ1MDgxQzQuOTg1MzA1LTUuMDQ1MDgxIDQuODE3OTMzLTQuODA1OTc4IDQuNzgyMDY3LTQuNDgzMTg4WicvPgo8cGF0aCBpZD0nZzQ0LTEwNCcgZD0nTTMuMzU5NDAyLTcuOTk4MDA3QzMuMzcxMzU3LTguMDQ1ODI4IDMuMzk1MjY4LTguMTE3NTU5IDMuMzk1MjY4LTguMTc3MzM1QzMuMzk1MjY4LTguMjk2ODg3IDMuMjc1NzE2LTguMjk2ODg3IDMuMjUxODA2LTguMjk2ODg3QzMuMjM5ODUxLTguMjk2ODg3IDIuNjU0MDQ3LTguMjQ5MDY2IDIuNTk0MjcxLTguMjM3MTExQzIuMzkxMDM0LTguMjI1MTU2IDIuMjExNzA2LTguMjAxMjQ1IDEuOTk2NTEzLTguMTg5MjlDMS42OTc2MzQtOC4xNjUzOCAxLjYxMzk0OC04LjE1MzQyNSAxLjYxMzk0OC03LjkzODIzMkMxLjYxMzk0OC03LjgxODY4IDEuNzA5NTg5LTcuODE4NjggMS44NzY5NjEtNy44MTg2OEMyLjQ2Mjc2NS03LjgxODY4IDIuNDc0NzItNy43MTEwODMgMi40NzQ3Mi03LjU5MTUzMkMyLjQ3NDcyLTcuNTE5ODAxIDIuNDUwODA5LTcuNDI0MTU5IDIuNDM4ODU0LTcuMzg4Mjk0TC43MDUzNTUtLjQ2NjI1MkMuNjU3NTM0LS4yODY5MjQgLjY1NzUzNC0uMjYzMDE0IC42NTc1MzQtLjE5MTI4M0MuNjU3NTM0IC4wNzE3MzEgLjg2MDc3MiAuMTE5NTUyIC45ODAzMjQgLjExOTU1MkMxLjE4MzU2MiAuMTE5NTUyIDEuMzM4OTc5LS4wMzU4NjYgMS4zOTg3NTUtLjE2NzM3MkwxLjkzNjczNy0yLjMzMTI1OEMxLjk5NjUxMy0yLjU5NDI3MSAyLjA2ODI0NC0yLjg0NTMzIDIuMTI4MDItMy4xMDgzNDRDMi4yNTk1MjctMy42MTA0NjEgMi4yNTk1MjctMy42MjI0MTYgMi40ODY2NzUtMy45NjkxMTZTMy4yNTE4MDYtNS4wMzMxMjYgNC4xNzIzNTQtNS4wMzMxMjZDNC42NTA1Ni01LjAzMzEyNiA0LjgxNzkzMy00LjY3NDQ3MSA0LjgxNzkzMy00LjE5NjI2NEM0LjgxNzkzMy0zLjUyNjc3NSA0LjM1MTY4MS0yLjIyMzY2MSA0LjA4ODY2Ny0xLjUwNjM1MUMzLjk4MTA3MS0xLjIxOTQyNyAzLjkyMTI5NS0xLjA2NDAxIDMuOTIxMjk1LS44NDg4MTdDMy45MjEyOTUtLjMxMDgzNCA0LjI5MTkwNSAuMTE5NTUyIDQuODY1NzUzIC4xMTk1NTJDNS45Nzc1ODQgLjExOTU1MiA2LjM5NjAxNS0xLjYzNzg1OCA2LjM5NjAxNS0xLjcwOTU4OUM2LjM5NjAxNS0xLjc2OTM2NSA2LjM0ODE5NC0xLjgxNzE4NiA2LjI3NjQ2My0xLjgxNzE4NkM2LjE2ODg2Ny0xLjgxNzE4NiA2LjE1NjkxMi0xLjc4MTMyIDYuMDk3MTM2LTEuNTc4MDgyQzUuODIyMTY3LS42MjE2NjkgNS4zNzk4MjYtLjExOTU1MiA0LjkwMTYxOS0uMTE5NTUyQzQuNzgyMDY3LS4xMTk1NTIgNC41OTA3ODUtLjEzMTUwNyA0LjU5MDc4NS0uNTE0MDcyQzQuNTkwNzg1LS44MjQ5MDcgNC43MzQyNDctMS4yMDc0NzIgNC43ODIwNjctMS4zMzg5NzlDNC45OTcyNi0xLjkxMjgyNyA1LjUzNTI0My0zLjMyMzUzNyA1LjUzNTI0My00LjAxNjkzNkM1LjUzNTI0My00LjczNDI0NyA1LjExNjgxMi01LjI3MjIyOSA0LjIwODIxOS01LjI3MjIyOUMzLjUyNjc3NS01LjI3MjIyOSAyLjkyOTAxNi00Ljk0OTQ0IDIuNDM4ODU0LTQuMzI3NzcxTDMuMzU5NDAyLTcuOTk4MDA3WicvPgo8cGF0aCBpZD0nZzQ0LTEwNScgZD0nTTMuMzgzMzEzLTEuNzA5NTg5QzMuMzgzMzEzLTEuNzY5MzY1IDMuMzM1NDkyLTEuODE3MTg2IDMuMjYzNzYxLTEuODE3MTg2QzMuMTU2MTY0LTEuODE3MTg2IDMuMTQ0MjA5LTEuNzgxMzIgMy4wODQ0MzMtMS41NzgwODJDMi43NzM1OTktLjQ5MDE2MiAyLjI4MzQzNy0uMTE5NTUyIDEuODg4OTE3LS4xMTk1NTJDMS43NDU0NTUtLjExOTU1MiAxLjU3ODA4Mi0uMTU1NDE3IDEuNTc4MDgyLS41MTQwNzJDMS41NzgwODItLjgzNjg2MiAxLjcyMTU0NC0xLjE5NTUxNyAxLjg1MzA1MS0xLjU1NDE3MkwyLjY4OTkxMy0zLjc3NzgzM0MyLjcyNTc3OC0zLjg3MzQ3NCAyLjgwOTQ2NS00LjA4ODY2NyAyLjgwOTQ2NS00LjMxNTgxNkMyLjgwOTQ2NS00LjgxNzkzMyAyLjQ1MDgwOS01LjI3MjIyOSAxLjg2NTAwNi01LjI3MjIyOUMuNzY1MTMxLTUuMjcyMjI5IC4zMjI3OS0zLjUzODczIC4zMjI3OS0zLjQ0MzA4OEMuMzIyNzktMy4zOTUyNjggLjM3MDYxLTMuMzM1NDkyIC40NTQyOTYtMy4zMzU0OTJDLjU2MTg5My0zLjMzNTQ5MiAuNTczODQ4LTMuMzgzMzEzIC42MjE2NjktMy41NTA2ODVDLjkwODU5My00LjU1NDkxOSAxLjM2Mjg4OS01LjAzMzEyNiAxLjgyOTE0MS01LjAzMzEyNkMxLjkzNjczNy01LjAzMzEyNiAyLjEzOTk3NS01LjAyMTE3MSAyLjEzOTk3NS00LjYzODYwNUMyLjEzOTk3NS00LjMyNzc3MSAxLjk4NDU1OC0zLjkzMzI1IDEuODg4OTE3LTMuNjcwMjM3TDEuMDUyMDU1LTEuNDQ2NTc1Qy45ODAzMjQtMS4yNTUyOTMgLjkwODU5My0xLjA2NDAxIC45MDg1OTMtLjg0ODgxN0MuOTA4NTkzLS4zMTA4MzQgMS4yNzkyMDMgLjExOTU1MiAxLjg1MzA1MSAuMTE5NTUyQzIuOTUyOTI3IC4xMTk1NTIgMy4zODMzMTMtMS42MjU5MDMgMy4zODMzMTMtMS43MDk1ODlaTTMuMjg3NjcxLTcuNDYwMDI1QzMuMjg3NjcxLTcuNjM5MzUyIDMuMTQ0MjA5LTcuODU0NTQ1IDIuODgxMTk2LTcuODU0NTQ1QzIuNjA2MjI3LTcuODU0NTQ1IDIuMjk1MzkyLTcuNTkxNTMyIDIuMjk1MzkyLTcuMjgwNjk3QzIuMjk1MzkyLTYuOTgxODE4IDIuNTQ2NDUxLTYuODg2MTc3IDIuNjg5OTEzLTYuODg2MTc3QzMuMDEyNzAyLTYuODg2MTc3IDMuMjg3NjcxLTcuMTk3MDExIDMuMjg3NjcxLTcuNDYwMDI1WicvPgo8cGF0aCBpZD0nZzQ0LTEwNicgZD0nTTQuMTg0MzA5LTMuNzg5Nzg4QzQuMjMyMTMtMy45ODEwNzEgNC4yMzIxMy00LjE0ODQ0MyA0LjIzMjEzLTQuMTk2MjY0QzQuMjMyMTMtNC44ODk2NjQgMy43MTgwNTctNS4yNzIyMjkgMy4xODAwNzUtNS4yNzIyMjlDMS45NzI2MDMtNS4yNzIyMjkgMS4zMjcwMjQtMy41MjY3NzUgMS4zMjcwMjQtMy40NDMwODhDMS4zMjcwMjQtMy4zODMzMTMgMS4zNzQ4NDQtMy4zMzU0OTIgMS40NDY1NzUtMy4zMzU0OTJDMS41NDIyMTctMy4zMzU0OTIgMS41NTQxNzItMy4zODMzMTMgMS42MTM5NDgtMy41MDI4NjRDMi4wOTIxNTQtNC42NjI1MTYgMi42ODk5MTMtNS4wMzMxMjYgMy4xNDQyMDktNS4wMzMxMjZDMy4zOTUyNjgtNS4wMzMxMjYgMy41MjY3NzUtNC45MDE2MTkgMy41MjY3NzUtNC40ODMxODhDMy41MjY3NzUtNC4xOTYyNjQgMy40OTA5MDktNC4wNzY3MTIgMy40NDMwODgtMy44NjE1MTlMMi4zMDczNDcgLjY0NTU3OUMyLjA4MDE5OSAxLjUzMDI2MiAxLjUxODMwNiAyLjE5OTc1MSAuODYwNzcyIDIuMTk5NzUxQy44MTI5NTEgMi4xOTk3NTEgLjU2MTg5MyAyLjE5OTc1MSAuMzM0NzQ1IDIuMDgwMTk5Qy42MjE2NjkgMi4wMjA0MjMgLjg0ODgxNyAxLjc5MzI3NSAuODQ4ODE3IDEuNTA2MzUxQy44NDg4MTcgMS4zMTUwNjggLjcwNTM1NSAxLjEyMzc4NiAuNDQyMzQxIDEuMTIzNzg2Qy4xMzE1MDcgMS4xMjM3ODYtLjE1NTQxNyAxLjM4NjgtLjE1NTQxNyAxLjc0NTQ1NUMtLjE1NTQxNyAyLjIzNTYxNiAuMzcwNjEgMi40Mzg4NTQgLjg2MDc3MiAyLjQzODg1NEMxLjY4NTY3OSAyLjQzODg1NCAyLjc3MzU5OSAxLjgyOTE0MSAzLjA3MjQ3OCAuNjMzNjI0TDQuMTg0MzA5LTMuNzg5Nzg4Wk00LjY3NDQ3MS03LjQ2MDAyNUM0LjY3NDQ3MS03Ljc1ODkwNCA0LjQyMzQxMi03Ljg1NDU0NSA0LjI3OTk1LTcuODU0NTQ1QzMuOTU3MTYxLTcuODU0NTQ1IDMuNjgyMTkyLTcuNTQzNzExIDMuNjgyMTkyLTcuMjgwNjk3QzMuNjgyMTkyLTcuMTAxMzcgMy44MjU2NTQtNi44ODYxNzcgNC4wODg2NjctNi44ODYxNzdDNC4zNjM2MzYtNi44ODYxNzcgNC42NzQ0NzEtNy4xNDkxOTEgNC42NzQ0NzEtNy40NjAwMjVaJy8+CjxwYXRoIGlkPSdnNDQtMTA4JyBkPSdNMy4wMzY2MTMtNy45OTgwMDdDMy4wNDg1NjgtOC4wNDU4MjggMy4wNzI0NzgtOC4xMTc1NTkgMy4wNzI0NzgtOC4xNzczMzVDMy4wNzI0NzgtOC4yOTY4ODcgMi45NTI5MjctOC4yOTY4ODcgMi45MjkwMTYtOC4yOTY4ODdDMi45MTcwNjEtOC4yOTY4ODcgMi40ODY2NzUtOC4yNjEwMjEgMi4yNzE0ODItOC4yMzcxMTFDMi4wNjgyNDQtOC4yMjUxNTYgMS44ODg5MTctOC4yMDEyNDUgMS42NzM3MjQtOC4xODkyOUMxLjM4NjgtOC4xNjUzOCAxLjMwMzExMy04LjE1MzQyNSAxLjMwMzExMy03LjkzODIzMkMxLjMwMzExMy03LjgxODY4IDEuNDIyNjY1LTcuODE4NjggMS41NDIyMTctNy44MTg2OEMyLjE1MTkzLTcuODE4NjggMi4xNTE5My03LjcxMTA4MyAyLjE1MTkzLTcuNTkxNTMyQzIuMTUxOTMtNy41NDM3MTEgMi4xNTE5My03LjUxOTgwMSAyLjA5MjE1NC03LjMwNDYwOEwuNjA5NzE0LTEuMzc0ODQ0Qy41NzM4NDgtMS4yNDMzMzcgLjU0OTkzOC0xLjE0NzY5NiAuNTQ5OTM4LS45NTY0MTNDLjU0OTkzOC0uMzU4NjU1IC45OTIyNzkgLjExOTU1MiAxLjYwMTk5MyAuMTE5NTUyQzEuOTk2NTEzIC4xMTk1NTIgMi4yNTk1MjctLjE0MzQ2MiAyLjQ1MDgwOS0uNTE0MDcyQzIuNjU0MDQ3LS45MDg1OTMgMi44MjE0Mi0xLjY2MTc2OCAyLjgyMTQyLTEuNzA5NTg5QzIuODIxNDItMS43NjkzNjUgMi43NzM1OTktMS44MTcxODYgMi43MDE4NjgtMS44MTcxODZDMi41OTQyNzEtMS44MTcxODYgMi41ODIzMTYtMS43NTc0MSAyLjUzNDQ5Ni0xLjU3ODA4MkMyLjMxOTMwMy0uNzUzMTc2IDIuMTA0MTEtLjExOTU1MiAxLjYyNTkwMy0uMTE5NTUyQzEuMjY3MjQ4LS4xMTk1NTIgMS4yNjcyNDgtLjUwMjExNyAxLjI2NzI0OC0uNjY5NDg5QzEuMjY3MjQ4LS43MTczMSAxLjI2NzI0OC0uOTY4MzY5IDEuMzUwOTM0LTEuMzAzMTEzTDMuMDM2NjEzLTcuOTk4MDA3WicvPgo8cGF0aCBpZD0nZzQ0LTEwOScgZD0nTTIuNDYyNzY1LTMuNTAyODY0QzIuNDg2Njc1LTMuNTc0NTk1IDIuNzg1NTU0LTQuMTcyMzU0IDMuMjI3ODk1LTQuNTU0OTE5QzMuNTM4NzMtNC44NDE4NDMgMy45NDUyMDUtNS4wMzMxMjYgNC40MTE0NTctNS4wMzMxMjZDNC44ODk2NjQtNS4wMzMxMjYgNS4wNTcwMzYtNC42NzQ0NzEgNS4wNTcwMzYtNC4xOTYyNjRDNS4wNTcwMzYtNC4xMjQ1MzMgNS4wNTcwMzYtMy44ODU0MyA0LjkxMzU3NC0zLjMyMzUzN0w0LjYxNDY5NS0yLjA5MjE1NEM0LjUxOTA1NC0xLjczMzQ5OSA0LjI5MTkwNS0uODQ4ODE3IDQuMjY3OTk1LS43MTczMUM0LjIyMDE3NC0uNTM3OTgzIDQuMTQ4NDQzLS4yMjcxNDggNC4xNDg0NDMtLjE3OTMyOEM0LjE0ODQ0My0uMDExOTU1IDQuMjc5OTUgLjExOTU1MiA0LjQ1OTI3OCAuMTE5NTUyQzQuODE3OTMzIC4xMTk1NTIgNC44Nzc3MDktLjE1NTQxNyA0Ljk4NTMwNS0uNTg1ODAzTDUuNzAyNjE1LTMuNDQzMDg4QzUuNzI2NTI2LTMuNTM4NzMgNi4zNDgxOTQtNS4wMzMxMjYgNy42NjMyNjMtNS4wMzMxMjZDOC4xNDE0NjktNS4wMzMxMjYgOC4zMDg4NDItNC42NzQ0NzEgOC4zMDg4NDItNC4xOTYyNjRDOC4zMDg4NDItMy41MjY3NzUgNy44NDI1OS0yLjIyMzY2MSA3LjU3OTU3Ny0xLjUwNjM1MUM3LjQ3MTk4LTEuMjE5NDI3IDcuNDEyMjA0LTEuMDY0MDEgNy40MTIyMDQtLjg0ODgxN0M3LjQxMjIwNC0uMzEwODM0IDcuNzgyODE0IC4xMTk1NTIgOC4zNTY2NjMgLjExOTU1MkM5LjQ2ODQ5MyAuMTE5NTUyIDkuODg2OTI0LTEuNjM3ODU4IDkuODg2OTI0LTEuNzA5NTg5QzkuODg2OTI0LTEuNzY5MzY1IDkuODM5MTAzLTEuODE3MTg2IDkuNzY3MzcyLTEuODE3MTg2QzkuNjU5Nzc2LTEuODE3MTg2IDkuNjQ3ODIxLTEuNzgxMzIgOS41ODgwNDUtMS41NzgwODJDOS4zMTMwNzYtLjYyMTY2OSA4Ljg3MDczNS0uMTE5NTUyIDguMzkyNTI4LS4xMTk1NTJDOC4yNzI5NzYtLjExOTU1MiA4LjA4MTY5NC0uMTMxNTA3IDguMDgxNjk0LS41MTQwNzJDOC4wODE2OTQtLjgyNDkwNyA4LjIyNTE1Ni0xLjIwNzQ3MiA4LjI3Mjk3Ni0xLjMzODk3OUM4LjQ4ODE2OS0xLjkxMjgyNyA5LjAyNjE1Mi0zLjMyMzUzNyA5LjAyNjE1Mi00LjAxNjkzNkM5LjAyNjE1Mi00LjczNDI0NyA4LjYwNzcyMS01LjI3MjIyOSA3LjY5OTEyOC01LjI3MjIyOUM2Ljg5ODEzMi01LjI3MjIyOSA2LjI1MjU1My00LjgxNzkzMyA1Ljc3NDM0Ni00LjExMjU3OEM1LjczODQ4MS00Ljc1ODE1NyA1LjM0Mzk2LTUuMjcyMjI5IDQuNDQ3MzIzLTUuMjcyMjI5QzMuMzgzMzEzLTUuMjcyMjI5IDIuODIxNDItNC41MTkwNTQgMi42MDYyMjctNC4yMjAxNzRDMi41NzAzNjEtNC45MDE2MTkgMi4wODAxOTktNS4yNzIyMjkgMS41NTQxNzItNS4yNzIyMjlDMS4yMDc0NzItNS4yNzIyMjkgLjkzMjUwMy01LjEwNDg1NyAuNzA1MzU1LTQuNjUwNTZDLjQ5MDE2Mi00LjIyMDE3NCAuMzIyNzktMy40OTA5MDkgLjMyMjc5LTMuNDQzMDg4Uy4zNzA2MS0zLjMzNTQ5MiAuNDU0Mjk2LTMuMzM1NDkyQy41NDk5MzgtMy4zMzU0OTIgLjU2MTg5My0zLjM0NzQ0NyAuNjMzNjI0LTMuNjIyNDE2Qy44MTI5NTEtNC4zMjc3NzEgMS4wNDAxLTUuMDMzMTI2IDEuNTE4MzA2LTUuMDMzMTI2QzEuNzkzMjc1LTUuMDMzMTI2IDEuODg4OTE3LTQuODQxODQzIDEuODg4OTE3LTQuNDgzMTg4QzEuODg4OTE3LTQuMjIwMTc0IDEuNzY5MzY1LTMuNzUzOTIzIDEuNjg1Njc5LTMuMzgzMzEzTDEuMzUwOTM0LTIuMDkyMTU0QzEuMzAzMTEzLTEuODY1MDA2IDEuMTcxNjA2LTEuMzI3MDI0IDEuMTExODMxLTEuMTExODMxQzEuMDI4MTQ0LS44MDA5OTYgLjg5NjYzOC0uMjM5MTAzIC44OTY2MzgtLjE3OTMyOEMuODk2NjM4LS4wMTE5NTUgMS4wMjgxNDQgLjExOTU1MiAxLjIwNzQ3MiAuMTE5NTUyQzEuMzUwOTM0IC4xMTk1NTIgMS41MTgzMDYgLjA0NzgyMSAxLjYxMzk0OC0uMTMxNTA3QzEuNjM3ODU4LS4xOTEyODMgMS43NDU0NTUtLjYwOTcxNCAxLjgwNTIzLS44NDg4MTdMMi4wNjgyNDQtMS45MjQ3ODJMMi40NjI3NjUtMy41MDI4NjRaJy8+CjxwYXRoIGlkPSdnNDQtMTEwJyBkPSdNMi40NjI3NjUtMy41MDI4NjRDMi40ODY2NzUtMy41NzQ1OTUgMi43ODU1NTQtNC4xNzIzNTQgMy4yMjc4OTUtNC41NTQ5MTlDMy41Mzg3My00Ljg0MTg0MyAzLjk0NTIwNS01LjAzMzEyNiA0LjQxMTQ1Ny01LjAzMzEyNkM0Ljg4OTY2NC01LjAzMzEyNiA1LjA1NzAzNi00LjY3NDQ3MSA1LjA1NzAzNi00LjE5NjI2NEM1LjA1NzAzNi0zLjUxNDgxOSA0LjU2Njg3NC0yLjE1MTkzIDQuMzI3NzcxLTEuNTA2MzUxQzQuMjIwMTc0LTEuMjE5NDI3IDQuMTYwMzk5LTEuMDY0MDEgNC4xNjAzOTktLjg0ODgxN0M0LjE2MDM5OS0uMzEwODM0IDQuNTMxMDA5IC4xMTk1NTIgNS4xMDQ4NTcgLjExOTU1MkM2LjIxNjY4NyAuMTE5NTUyIDYuNjM1MTE4LTEuNjM3ODU4IDYuNjM1MTE4LTEuNzA5NTg5QzYuNjM1MTE4LTEuNzY5MzY1IDYuNTg3Mjk4LTEuODE3MTg2IDYuNTE1NTY3LTEuODE3MTg2QzYuNDA3OTctMS44MTcxODYgNi4zOTYwMTUtMS43ODEzMiA2LjMzNjIzOS0xLjU3ODA4MkM2LjA2MTI3LS41OTc3NTggNS42MDY5NzQtLjExOTU1MiA1LjE0MDcyMi0uMTE5NTUyQzUuMDIxMTcxLS4xMTk1NTIgNC44Mjk4ODgtLjEzMTUwNyA0LjgyOTg4OC0uNTE0MDcyQzQuODI5ODg4LS44MTI5NTEgNC45NjEzOTUtMS4xNzE2MDYgNS4wMzMxMjYtMS4zMzg5NzlDNS4yNzIyMjktMS45OTY1MTMgNS43NzQzNDYtMy4zMzU0OTIgNS43NzQzNDYtNC4wMTY5MzZDNS43NzQzNDYtNC43MzQyNDcgNS4zNTU5MTUtNS4yNzIyMjkgNC40NDczMjMtNS4yNzIyMjlDMy4zODMzMTMtNS4yNzIyMjkgMi44MjE0Mi00LjUxOTA1NCAyLjYwNjIyNy00LjIyMDE3NEMyLjU3MDM2MS00LjkwMTYxOSAyLjA4MDE5OS01LjI3MjIyOSAxLjU1NDE3Mi01LjI3MjIyOUMxLjE3MTYwNi01LjI3MjIyOSAuOTA4NTkzLTUuMDQ1MDgxIC43MDUzNTUtNC42Mzg2MDVDLjQ5MDE2Mi00LjIwODIxOSAuMzIyNzktMy40OTA5MDkgLjMyMjc5LTMuNDQzMDg4Uy4zNzA2MS0zLjMzNTQ5MiAuNDU0Mjk2LTMuMzM1NDkyQy41NDk5MzgtMy4zMzU0OTIgLjU2MTg5My0zLjM0NzQ0NyAuNjMzNjI0LTMuNjIyNDE2Qy44MjQ5MDctNC4zNTE2ODEgMS4wNDAxLTUuMDMzMTI2IDEuNTE4MzA2LTUuMDMzMTI2QzEuNzkzMjc1LTUuMDMzMTI2IDEuODg4OTE3LTQuODQxODQzIDEuODg4OTE3LTQuNDgzMTg4QzEuODg4OTE3LTQuMjIwMTc0IDEuNzY5MzY1LTMuNzUzOTIzIDEuNjg1Njc5LTMuMzgzMzEzTDEuMzUwOTM0LTIuMDkyMTU0QzEuMzAzMTEzLTEuODY1MDA2IDEuMTcxNjA2LTEuMzI3MDI0IDEuMTExODMxLTEuMTExODMxQzEuMDI4MTQ0LS44MDA5OTYgLjg5NjYzOC0uMjM5MTAzIC44OTY2MzgtLjE3OTMyOEMuODk2NjM4LS4wMTE5NTUgMS4wMjgxNDQgLjExOTU1MiAxLjIwNzQ3MiAuMTE5NTUyQzEuMzUwOTM0IC4xMTk1NTIgMS41MTgzMDYgLjA0NzgyMSAxLjYxMzk0OC0uMTMxNTA3QzEuNjM3ODU4LS4xOTEyODMgMS43NDU0NTUtLjYwOTcxNCAxLjgwNTIzLS44NDg4MTdMMi4wNjgyNDQtMS45MjQ3ODJMMi40NjI3NjUtMy41MDI4NjRaJy8+CjxwYXRoIGlkPSdnNDQtMTExJyBkPSdNNS40NTE1NTctMy4yODc2NzFDNS40NTE1NTctNC40MjM0MTIgNC43MTAzMzYtNS4yNzIyMjkgMy42MjI0MTYtNS4yNzIyMjlDMi4wNDQzMzQtNS4yNzIyMjkgLjQ5MDE2Mi0zLjU1MDY4NSAuNDkwMTYyLTEuODY1MDA2Qy40OTAxNjItLjcyOTI2NSAxLjIzMTM4MiAuMTE5NTUyIDIuMzE5MzAzIC4xMTk1NTJDMy45MDkzNCAuMTE5NTUyIDUuNDUxNTU3LTEuNjAxOTkzIDUuNDUxNTU3LTMuMjg3NjcxWk0yLjMzMTI1OC0uMTE5NTUyQzEuNzMzNDk5LS4xMTk1NTIgMS4yOTExNTgtLjU5Nzc1OCAxLjI5MTE1OC0xLjQzNDYyQzEuMjkxMTU4LTEuOTg0NTU4IDEuNTc4MDgyLTMuMjAzOTg1IDEuOTEyODI3LTMuODAxNzQzQzIuNDUwODA5LTQuNzIyMjkxIDMuMTIwMjk5LTUuMDMzMTI2IDMuNjEwNDYxLTUuMDMzMTI2QzQuMTk2MjY0LTUuMDMzMTI2IDQuNjUwNTYtNC41NTQ5MTkgNC42NTA1Ni0zLjcxODA1N0M0LjY1MDU2LTMuMjM5ODUxIDQuMzk5NTAyLTEuOTYwNjQ4IDMuOTQ1MjA1LTEuMjMxMzgyQzMuNDU1MDQ0LS40MzAzODYgMi43OTc1MDktLjExOTU1MiAyLjMzMTI1OC0uMTE5NTUyWicvPgo8cGF0aCBpZD0nZzQ0LTExMicgZD0nTS41MTQwNzIgMS41MTgzMDZDLjQzMDM4NiAxLjg3Njk2MSAuMzgyNTY1IDEuOTcyNjAzLS4xMDc1OTcgMS45NzI2MDNDLS4yNTEwNTkgMS45NzI2MDMtLjM3MDYxIDEuOTcyNjAzLS4zNzA2MSAyLjE5OTc1MUMtLjM3MDYxIDIuMjIzNjYxLS4zNTg2NTUgMi4zMTkzMDMtLjIyNzE0OCAyLjMxOTMwM0MtLjA3MTczMSAyLjMxOTMwMyAuMDk1NjQxIDIuMjk1MzkyIC4yNTEwNTkgMi4yOTUzOTJILjc2NTEzMUMxLjAxNjE4OSAyLjI5NTM5MiAxLjYyNTkwMyAyLjMxOTMwMyAxLjg3Njk2MSAyLjMxOTMwM0MxLjk0ODY5MiAyLjMxOTMwMyAyLjA5MjE1NCAyLjMxOTMwMyAyLjA5MjE1NCAyLjEwNDExQzIuMDkyMTU0IDEuOTcyNjAzIDIuMDA4NDY4IDEuOTcyNjAzIDEuODA1MjMgMS45NzI2MDNDMS4yNTUyOTMgMS45NzI2MDMgMS4yMTk0MjcgMS44ODg5MTcgMS4yMTk0MjcgMS43OTMyNzVDMS4yMTk0MjcgMS42NDk4MTMgMS43NTc0MS0uNDA2NDc2IDEuODI5MTQxLS42ODE0NDVDMS45NjA2NDgtLjM0NjcgMi4yODM0MzcgLjExOTU1MiAyLjkwNTEwNiAuMTE5NTUyQzQuMjU2MDQgLjExOTU1MiA1LjcxNDU3LTEuNjM3ODU4IDUuNzE0NTctMy4zOTUyNjhDNS43MTQ1Ny00LjQ5NTE0MyA1LjA5MjkwMi01LjI3MjIyOSA0LjE5NjI2NC01LjI3MjIyOUMzLjQzMTEzMy01LjI3MjIyOSAyLjc4NTU1NC00LjUzMTAwOSAyLjY1NDA0Ny00LjM2MzYzNkMyLjU1ODQwNi00Ljk2MTM5NSAyLjA5MjE1NC01LjI3MjIyOSAxLjYxMzk0OC01LjI3MjIyOUMxLjI2NzI0OC01LjI3MjIyOSAuOTkyMjc5LTUuMTA0ODU3IC43NjUxMzEtNC42NTA1NkMuNTQ5OTM4LTQuMjIwMTc0IC4zODI1NjUtMy40OTA5MDkgLjM4MjU2NS0zLjQ0MzA4OFMuNDMwMzg2LTMuMzM1NDkyIC41MTQwNzItMy4zMzU0OTJDLjYwOTcxNC0zLjMzNTQ5MiAuNjIxNjY5LTMuMzQ3NDQ3IC42OTM0LTMuNjIyNDE2Qy44NzI3MjctNC4zMjc3NzEgMS4wOTk4NzUtNS4wMzMxMjYgMS41NzgwODItNS4wMzMxMjZDMS44NTMwNTEtNS4wMzMxMjYgMS45NDg2OTItNC44NDE4NDMgMS45NDg2OTItNC40ODMxODhDMS45NDg2OTItNC4xOTYyNjQgMS45MTI4MjctNC4wNzY3MTIgMS44NjUwMDYtMy44NjE1MTlMLjUxNDA3MiAxLjUxODMwNlpNMi41ODIzMTYtMy43MzAwMTJDMi42NjYwMDItNC4wNjQ3NTcgMy4wMDA3NDctNC40MTE0NTcgMy4xOTIwMy00LjU3ODgyOUMzLjMyMzUzNy00LjY5ODM4MSAzLjcxODA1Ny01LjAzMzEyNiA0LjE3MjM1NC01LjAzMzEyNkM0LjY5ODM4MS01LjAzMzEyNiA0LjkzNzQ4NC00LjUwNzA5OCA0LjkzNzQ4NC0zLjg4NTQzQzQuOTM3NDg0LTMuMzExNTgyIDQuNjAyNzQtMS45NjA2NDggNC4zMDM4NjEtMS4zMzg5NzlDNC4wMDQ5ODEtLjY5MzQgMy40NTUwNDQtLjExOTU1MiAyLjkwNTEwNi0uMTE5NTUyQzIuMDkyMTU0LS4xMTk1NTIgMS45NjA2NDgtMS4xNDc2OTYgMS45NjA2NDgtMS4xOTU1MTdDMS45NjA2NDgtMS4yMzEzODIgMS45ODQ1NTgtMS4zMjcwMjQgMS45OTY1MTMtMS4zODY4TDIuNTgyMzE2LTMuNzMwMDEyWicvPgo8cGF0aCBpZD0nZzQ0LTExNCcgZD0nTTQuNjUwNTYtNC44ODk2NjRDNC4yNzk5NS00LjgxNzkzMyA0LjA4ODY2Ny00LjU1NDkxOSA0LjA4ODY2Ny00LjI5MTkwNUM0LjA4ODY2Ny00LjAwNDk4MSA0LjMxNTgxNi0zLjkwOTM0IDQuNDgzMTg4LTMuOTA5MzRDNC44MTc5MzMtMy45MDkzNCA1LjA5MjkwMi00LjE5NjI2NCA1LjA5MjkwMi00LjU1NDkxOUM1LjA5MjkwMi00LjkzNzQ4NCA0LjcyMjI5MS01LjI3MjIyOSA0LjEyNDUzMy01LjI3MjIyOUMzLjY0NjMyNi01LjI3MjIyOSAzLjA5NjM4OS01LjA1NzAzNiAyLjU5NDI3MS00LjMyNzc3MUMyLjUxMDU4NS00Ljk2MTM5NSAyLjAzMjM3OS01LjI3MjIyOSAxLjU1NDE3Mi01LjI3MjIyOUMxLjA4NzkyLTUuMjcyMjI5IC44NDg4MTctNC45MTM1NzQgLjcwNTM1NS00LjY1MDU2Qy41MDIxMTctNC4yMjAxNzQgLjMyMjc5LTMuNTAyODY0IC4zMjI3OS0zLjQ0MzA4OEMuMzIyNzktMy4zOTUyNjggLjM3MDYxLTMuMzM1NDkyIC40NTQyOTYtMy4zMzU0OTJDLjU0OTkzOC0zLjMzNTQ5MiAuNTYxODkzLTMuMzQ3NDQ3IC42MzM2MjQtMy42MjI0MTZDLjgxMjk1MS00LjMzOTcyNiAxLjA0MDEtNS4wMzMxMjYgMS41MTgzMDYtNS4wMzMxMjZDMS44MDUyMy01LjAzMzEyNiAxLjg4ODkxNy00LjgyOTg4OCAxLjg4ODkxNy00LjQ4MzE4OEMxLjg4ODkxNy00LjIyMDE3NCAxLjc2OTM2NS0zLjc1MzkyMyAxLjY4NTY3OS0zLjM4MzMxM0wxLjM1MDkzNC0yLjA5MjE1NEMxLjMwMzExMy0xLjg2NTAwNiAxLjE3MTYwNi0xLjMyNzAyNCAxLjExMTgzMS0xLjExMTgzMUMxLjAyODE0NC0uODAwOTk2IC44OTY2MzgtLjIzOTEwMyAuODk2NjM4LS4xNzkzMjhDLjg5NjYzOC0uMDExOTU1IDEuMDI4MTQ0IC4xMTk1NTIgMS4yMDc0NzIgLjExOTU1MkMxLjMzODk3OSAuMTE5NTUyIDEuNTY2MTI3IC4wMzU4NjYgMS42Mzc4NTgtLjIwMzIzOEMxLjY3MzcyNC0uMjk4ODc5IDIuMTE2MDY1LTIuMTA0MTEgMi4xODc3OTYtMi4zNzkwNzhDMi4yNDc1NzItMi42NDIwOTIgMi4zMTkzMDMtMi44OTMxNTEgMi4zNzkwNzgtMy4xNTYxNjRDMi40MjY4OTktMy4zMjM1MzcgMi40NzQ3Mi0zLjUxNDgxOSAyLjUxMDU4NS0zLjY3MDIzN0MyLjU0NjQ1MS0zLjc3NzgzMyAyLjg2OTI0LTQuMzYzNjM2IDMuMTY4MTItNC42MjY2NUMzLjMxMTU4Mi00Ljc1ODE1NyAzLjYyMjQxNi01LjAzMzEyNiA0LjExMjU3OC01LjAzMzEyNkM0LjMwMzg2MS01LjAzMzEyNiA0LjQ5NTE0My00Ljk5NzI2IDQuNjUwNTYtNC44ODk2NjRaJy8+CjxwYXRoIGlkPSdnNDQtMTE1JyBkPSdNMi43MjU3NzgtMi4zOTEwMzRDMi45MjkwMTYtMi4zNTUxNjggMy4yNTE4MDYtMi4yODM0MzcgMy4zMjM1MzctMi4yNzE0ODJDMy40Nzg5NTQtMi4yMjM2NjEgNC4wMTY5MzYtMi4wMzIzNzkgNC4wMTY5MzYtMS40NTg1MzFDNC4wMTY5MzYtMS4wODc5MiAzLjY4MjE5Mi0uMTE5NTUyIDIuMjk1MzkyLS4xMTk1NTJDMi4wNDQzMzQtLjExOTU1MiAxLjE0NzY5Ni0uMTU1NDE3IC45MDg1OTMtLjgxMjk1MUMxLjM4NjgtLjc1MzE3NiAxLjYyNTkwMy0xLjEyMzc4NiAxLjYyNTkwMy0xLjM4NjhDMS42MjU5MDMtMS42Mzc4NTggMS40NTg1MzEtMS43NjkzNjUgMS4yMTk0MjctMS43NjkzNjVDLjk1NjQxMy0xLjc2OTM2NSAuNjA5NzE0LTEuNTY2MTI3IC42MDk3MTQtMS4wMjgxNDRDLjYwOTcxNC0uMzIyNzkgMS4zMjcwMjQgLjExOTU1MiAyLjI4MzQzNyAuMTE5NTUyQzQuMTAwNjIzIC4xMTk1NTIgNC42Mzg2MDUtMS4yMTk0MjcgNC42Mzg2MDUtMS44NDEwOTZDNC42Mzg2MDUtMi4wMjA0MjMgNC42Mzg2MDUtMi4zNTUxNjggNC4yNTYwNC0yLjczNzczM0MzLjk1NzE2MS0zLjAyNDY1OCAzLjY3MDIzNy0zLjA4NDQzMyAzLjAyNDY1OC0zLjIxNTk0QzIuNzAxODY4LTMuMjg3NjcxIDIuMTg3Nzk2LTMuMzk1MjY4IDIuMTg3Nzk2LTMuOTMzMjVDMi4xODc3OTYtNC4xNzIzNTQgMi40MDI5ODktNS4wMzMxMjYgMy41Mzg3My01LjAzMzEyNkM0LjA0MDg0Ny01LjAzMzEyNiA0LjUzMTAwOS00Ljg0MTg0MyA0LjY1MDU2LTQuNDExNDU3QzQuMTI0NTMzLTQuNDExNDU3IDQuMTAwNjIzLTMuOTU3MTYxIDQuMTAwNjIzLTMuOTQ1MjA1QzQuMTAwNjIzLTMuNjk0MTQ3IDQuMzI3NzcxLTMuNjIyNDE2IDQuNDM1MzY3LTMuNjIyNDE2QzQuNjAyNzQtMy42MjI0MTYgNC45Mzc0ODQtMy43NTM5MjMgNC45Mzc0ODQtNC4yNTYwNFM0LjQ4MzE4OC01LjI3MjIyOSAzLjU1MDY4NS01LjI3MjIyOUMxLjk4NDU1OC01LjI3MjIyOSAxLjU2NjEyNy00LjA0MDg0NyAxLjU2NjEyNy0zLjU1MDY4NUMxLjU2NjEyNy0yLjY0MjA5MiAyLjQ1MDgwOS0yLjQ1MDgwOSAyLjcyNTc3OC0yLjM5MTAzNFonLz4KPHBhdGggaWQ9J2c0NC0xMTYnIGQ9J00yLjQwMjk4OS00LjgwNTk3OEgzLjUwMjg2NEMzLjczMDAxMi00LjgwNTk3OCAzLjg0OTU2NC00LjgwNTk3OCAzLjg0OTU2NC01LjAyMTE3MUMzLjg0OTU2NC01LjE1MjY3NyAzLjc3NzgzMy01LjE1MjY3NyAzLjUzODczLTUuMTUyNjc3SDIuNDg2Njc1TDIuOTI5MDE2LTYuODk4MTMyQzIuOTc2ODM3LTcuMDY1NTA0IDIuOTc2ODM3LTcuMDg5NDE1IDIuOTc2ODM3LTcuMTczMTAxQzIuOTc2ODM3LTcuMzY0Mzg0IDIuODIxNDItNy40NzE5OCAyLjY2NjAwMi03LjQ3MTk4QzIuNTcwMzYxLTcuNDcxOTggMi4yOTUzOTItNy40MzYxMTUgMi4xOTk3NTEtNy4wNTM1NDlMMS43MzM0OTktNS4xNTI2NzdILjYwOTcxNEMuMzcwNjEtNS4xNTI2NzcgLjI2MzAxNC01LjE1MjY3NyAuMjYzMDE0LTQuOTI1NTI5Qy4yNjMwMTQtNC44MDU5NzggLjM0NjctNC44MDU5NzggLjU3Mzg0OC00LjgwNTk3OEgxLjYzNzg1OEwuODQ4ODE3LTEuNjQ5ODEzQy43NTMxNzYtMS4yMzEzODIgLjcxNzMxLTEuMTExODMxIC43MTczMS0uOTU2NDEzQy43MTczMS0uMzk0NTIxIDEuMTExODMxIC4xMTk1NTIgMS43ODEzMiAuMTE5NTUyQzIuOTg4NzkyIC4xMTk1NTIgMy42MzQzNzEtMS42MjU5MDMgMy42MzQzNzEtMS43MDk1ODlDMy42MzQzNzEtMS43ODEzMiAzLjU4NjU1LTEuODE3MTg2IDMuNTE0ODE5LTEuODE3MTg2QzMuNDkwOTA5LTEuODE3MTg2IDMuNDQzMDg4LTEuODE3MTg2IDMuNDE5MTc4LTEuNzY5MzY1QzMuNDA3MjIzLTEuNzU3NDEgMy4zOTUyNjgtMS43NDU0NTUgMy4zMTE1ODItMS41NTQxNzJDMy4wNjA1MjMtLjk1NjQxMyAyLjUxMDU4NS0uMTE5NTUyIDEuODE3MTg2LS4xMTk1NTJDMS40NTg1MzEtLjExOTU1MiAxLjQzNDYyLS40MTg0MzEgMS40MzQ2Mi0uNjgxNDQ1QzEuNDM0NjItLjY5MzQgMS40MzQ2Mi0uOTIwNTQ4IDEuNDcwNDg2LTEuMDY0MDFMMi40MDI5ODktNC44MDU5NzhaJy8+CjxwYXRoIGlkPSdnNDQtMTE3JyBkPSdNNC4wNzY3MTItLjY5MzRDNC4yMzIxMy0uMDIzOTEgNC44MDU5NzggLjExOTU1MiA1LjA5MjkwMiAuMTE5NTUyQzUuNDc1NDY3IC4xMTk1NTIgNS43NjIzOTEtLjEzMTUwNyA1Ljk1MzY3NC0uNTM3OTgzQzYuMTU2OTEyLS45NjgzNjkgNi4zMTIzMjktMS42NzM3MjQgNi4zMTIzMjktMS43MDk1ODlDNi4zMTIzMjktMS43NjkzNjUgNi4yNjQ1MDgtMS44MTcxODYgNi4xOTI3NzctMS44MTcxODZDNi4wODUxODEtMS44MTcxODYgNi4wNzMyMjUtMS43NTc0MSA2LjAyNTQwNS0xLjU3ODA4MkM1LjgxMDIxMi0uNzUzMTc2IDUuNTk1MDE5LS4xMTk1NTIgNS4xMTY4MTItLjExOTU1MkM0Ljc1ODE1Ny0uMTE5NTUyIDQuNzU4MTU3LS41MTQwNzIgNC43NTgxNTctLjY2OTQ4OUM0Ljc1ODE1Ny0uOTQ0NDU4IDQuNzk0MDIyLTEuMDY0MDEgNC45MTM1NzQtMS41NjYxMjdDNC45OTcyNi0xLjg4ODkxNyA1LjA4MDk0Ni0yLjIxMTcwNiA1LjE1MjY3Ny0yLjU0NjQ1MUw1LjY0MjgzOS00LjQ5NTE0M0M1LjcyNjUyNi00Ljc5NDAyMiA1LjcyNjUyNi00LjgxNzkzMyA1LjcyNjUyNi00Ljg1Mzc5OEM1LjcyNjUyNi01LjAzMzEyNiA1LjU4MzA2NC01LjE1MjY3NyA1LjQwMzczNi01LjE1MjY3N0M1LjA1NzAzNi01LjE1MjY3NyA0Ljk3MzM1LTQuODUzNzk4IDQuOTAxNjE5LTQuNTU0OTE5QzQuNzgyMDY3LTQuMDg4NjY3IDQuMTM2NDg4LTEuNTE4MzA2IDQuMDUyODAyLTEuMDk5ODc1QzQuMDQwODQ3LTEuMDk5ODc1IDMuNTc0NTk1LS4xMTk1NTIgMi43MDE4NjgtLjExOTU1MkMyLjA4MDE5OS0uMTE5NTUyIDEuOTYwNjQ4LS42NTc1MzQgMS45NjA2NDgtMS4wOTk4NzVDMS45NjA2NDgtMS43ODEzMiAyLjI5NTM5Mi0yLjczNzczMyAyLjYwNjIyNy0zLjUzODczQzIuNzQ5Njg5LTMuOTIxMjk1IDIuODA5NDY1LTQuMDc2NzEyIDIuODA5NDY1LTQuMzE1ODE2QzIuODA5NDY1LTQuODI5ODg4IDIuNDM4ODU0LTUuMjcyMjI5IDEuODY1MDA2LTUuMjcyMjI5Qy43NjUxMzEtNS4yNzIyMjkgLjMyMjc5LTMuNTM4NzMgLjMyMjc5LTMuNDQzMDg4Qy4zMjI3OS0zLjM5NTI2OCAuMzcwNjEtMy4zMzU0OTIgLjQ1NDI5Ni0zLjMzNTQ5MkMuNTYxODkzLTMuMzM1NDkyIC41NzM4NDgtMy4zODMzMTMgLjYyMTY2OS0zLjU1MDY4NUMuOTA4NTkzLTQuNTc4ODI5IDEuMzc0ODQ0LTUuMDMzMTI2IDEuODI5MTQxLTUuMDMzMTI2QzEuOTQ4NjkyLTUuMDMzMTI2IDIuMTM5OTc1LTUuMDIxMTcxIDIuMTM5OTc1LTQuNjM4NjA1QzIuMTM5OTc1LTQuMzI3NzcxIDIuMDA4NDY4LTMuOTgxMDcxIDEuODI5MTQxLTMuNTI2Nzc1QzEuMzAzMTEzLTIuMTA0MTEgMS4yNDMzMzctMS42NDk4MTMgMS4yNDMzMzctMS4yOTExNThDMS4yNDMzMzctLjA3MTczMSAyLjE2Mzg4NSAuMTE5NTUyIDIuNjU0MDQ3IC4xMTk1NTJDMy40MTkxNzggLjExOTU1MiAzLjgzNzYwOS0uNDA2NDc2IDQuMDc2NzEyLS42OTM0WicvPgo8cGF0aCBpZD0nZzQ0LTExOCcgZD0nTTUuNDYzNTEyLTQuNDcxMjMzQzUuNDYzNTEyLTUuMjI0NDA4IDUuMDgwOTQ2LTUuMjcyMjI5IDQuOTg1MzA1LTUuMjcyMjI5QzQuNjk4MzgxLTUuMjcyMjI5IDQuNDM1MzY3LTQuOTg1MzA1IDQuNDM1MzY3LTQuNzQ2MjAyQzQuNDM1MzY3LTQuNjAyNzQgNC41MTkwNTQtNC41MTkwNTQgNC41NjY4NzQtNC40NzEyMzNDNC42ODY0MjYtNC4zNjM2MzYgNC45OTcyNi00LjA0MDg0NyA0Ljk5NzI2LTMuNDE5MTc4QzQuOTk3MjYtMi45MTcwNjEgNC4yNzk5NS0uMTE5NTUyIDIuODQ1MzMtLjExOTU1MkMyLjExNjA2NS0uMTE5NTUyIDEuOTcyNjAzLS43MjkyNjUgMS45NzI2MDMtMS4xNzE2MDZDMS45NzI2MDMtMS43NjkzNjUgMi4yNDc1NzItMi42MDYyMjcgMi41NzAzNjEtMy40NjY5OTlDMi43NjE2NDQtMy45NTcxNjEgMi44MDk0NjUtNC4wNzY3MTIgMi44MDk0NjUtNC4zMTU4MTZDMi44MDk0NjUtNC44MTc5MzMgMi40NTA4MDktNS4yNzIyMjkgMS44NjUwMDYtNS4yNzIyMjlDLjc2NTEzMS01LjI3MjIyOSAuMzIyNzktMy41Mzg3MyAuMzIyNzktMy40NDMwODhDLjMyMjc5LTMuMzk1MjY4IC4zNzA2MS0zLjMzNTQ5MiAuNDU0Mjk2LTMuMzM1NDkyQy41NjE4OTMtMy4zMzU0OTIgLjU3Mzg0OC0zLjM4MzMxMyAuNjIxNjY5LTMuNTUwNjg1Qy45MDg1OTMtNC41Nzg4MjkgMS4zNzQ4NDQtNS4wMzMxMjYgMS44MjkxNDEtNS4wMzMxMjZDMS45MzY3MzctNS4wMzMxMjYgMi4xMzk5NzUtNS4wMzMxMjYgMi4xMzk5NzUtNC42Mzg2MDVDMi4xMzk5NzUtNC4zMjc3NzEgMi4wMDg0NjgtMy45ODEwNzEgMS44MjkxNDEtMy41MjY3NzVDMS4yNTUyOTMtMS45OTY1MTMgMS4yNTUyOTMtMS42MjU5MDMgMS4yNTUyOTMtMS4zMzg5NzlDMS4yNTUyOTMtMS4wNzU5NjUgMS4yOTExNTgtLjU4NTgwMyAxLjY2MTc2OC0uMjUxMDU5QzIuMDkyMTU0IC4xMTk1NTIgMi42ODk5MTMgLjExOTU1MiAyLjc5NzUwOSAuMTE5NTUyQzQuNzgyMDY3IC4xMTk1NTIgNS40NjM1MTItMy43ODk3ODggNS40NjM1MTItNC40NzEyMzNaJy8+CjxwYXRoIGlkPSdnNDQtMTIwJyBkPSdNNS42NjY3NS00Ljg3NzcwOUM1LjI4NDE4NC00LjgwNTk3OCA1LjE0MDcyMi00LjUxOTA1NCA1LjE0MDcyMi00LjI5MTkwNUM1LjE0MDcyMi00LjAwNDk4MSA1LjM2Nzg3LTMuOTA5MzQgNS41MzUyNDMtMy45MDkzNEM1Ljg5Mzg5OC0zLjkwOTM0IDYuMTQ0OTU2LTQuMjIwMTc0IDYuMTQ0OTU2LTQuNTQyOTY0QzYuMTQ0OTU2LTUuMDQ1MDgxIDUuNTcxMTA4LTUuMjcyMjI5IDUuMDY4OTkxLTUuMjcyMjI5QzQuMzM5NzI2LTUuMjcyMjI5IDMuOTMzMjUtNC41NTQ5MTkgMy44MjU2NTQtNC4zMjc3NzFDMy41NTA2ODUtNS4yMjQ0MDggMi44MDk0NjUtNS4yNzIyMjkgMi41OTQyNzEtNS4yNzIyMjlDMS4zNzQ4NDQtNS4yNzIyMjkgLjcyOTI2NS0zLjcwNjEwMiAuNzI5MjY1LTMuNDQzMDg4Qy43MjkyNjUtMy4zOTUyNjggLjc3NzA4Ni0zLjMzNTQ5MiAuODYwNzcyLTMuMzM1NDkyQy45NTY0MTMtMy4zMzU0OTIgLjk4MDMyNC0zLjQwNzIyMyAxLjAwNDIzNC0zLjQ1NTA0NEMxLjQxMDcxLTQuNzgyMDY3IDIuMjExNzA2LTUuMDMzMTI2IDIuNTU4NDA2LTUuMDMzMTI2QzMuMDk2Mzg5LTUuMDMzMTI2IDMuMjAzOTg1LTQuNTMxMDA5IDMuMjAzOTg1LTQuMjQ0MDg1QzMuMjAzOTg1LTMuOTgxMDcxIDMuMTMyMjU0LTMuNzA2MTAyIDIuOTg4NzkyLTMuMTMyMjU0TDIuNTgyMzE2LTEuNDk0Mzk2QzIuNDAyOTg5LS43NzcwODYgMi4wNTYyODktLjExOTU1MiAxLjQyMjY2NS0uMTE5NTUyQzEuMzYyODg5LS4xMTk1NTIgMS4wNjQwMS0uMTE5NTUyIC44MTI5NTEtLjI3NDk2OUMxLjI0MzMzNy0uMzU4NjU1IDEuMzM4OTc5LS43MTczMSAxLjMzODk3OS0uODYwNzcyQzEuMzM4OTc5LTEuMDk5ODc1IDEuMTU5NjUxLTEuMjQzMzM3IC45MzI1MDMtMS4yNDMzMzdDLjY0NTU3OS0xLjI0MzMzNyAuMzM0NzQ1LS45OTIyNzkgLjMzNDc0NS0uNjA5NzE0Qy4zMzQ3NDUtLjEwNzU5NyAuODk2NjM4IC4xMTk1NTIgMS40MTA3MSAuMTE5NTUyQzEuOTg0NTU4IC4xMTk1NTIgMi4zOTEwMzQtLjMzNDc0NSAyLjY0MjA5Mi0uODI0OTA3QzIuODMzMzc1LS4xMTk1NTIgMy40MzExMzMgLjExOTU1MiAzLjg3MzQ3NCAuMTE5NTUyQzUuMDkyOTAyIC4xMTk1NTIgNS43Mzg0ODEtMS40NDY1NzUgNS43Mzg0ODEtMS43MDk1ODlDNS43Mzg0ODEtMS43NjkzNjUgNS42OTA2Ni0xLjgxNzE4NiA1LjYxODkyOS0xLjgxNzE4NkM1LjUxMTMzMy0xLjgxNzE4NiA1LjQ5OTM3Ny0xLjc1NzQxIDUuNDYzNTEyLTEuNjYxNzY4QzUuMTQwNzIyLS42MDk3MTQgNC40NDczMjMtLjExOTU1MiAzLjkwOTM0LS4xMTk1NTJDMy40OTA5MDktLjExOTU1MiAzLjI2Mzc2MS0uNDMwMzg2IDMuMjYzNzYxLS45MjA1NDhDMy4yNjM3NjEtMS4xODM1NjIgMy4zMTE1ODItMS4zNzQ4NDQgMy41MDI4NjQtMi4xNjM4ODVMMy45MjEyOTUtMy43ODk3ODhDNC4xMDA2MjMtNC41MDcwOTggNC41MDcwOTgtNS4wMzMxMjYgNS4wNTcwMzYtNS4wMzMxMjZDNS4wODA5NDYtNS4wMzMxMjYgNS40MTU2OTEtNS4wMzMxMjYgNS42NjY3NS00Ljg3NzcwOVonLz4KPHBhdGggaWQ9J2c0MC0xNicgZD0nTTYuMTU2OTEyIDIwLjg5NzYzNEM2LjE4MDgyMiAyMC45MDk1ODkgNi4yODg0MTggMjEuMDI5MTQxIDYuMzAwMzc0IDIxLjAyOTE0MUg2LjU2MzM4N0M2LjU5OTI1MyAyMS4wMjkxNDEgNi42OTQ4OTQgMjEuMDE3MTg2IDYuNjk0ODk0IDIwLjkwOTU4OUM2LjY5NDg5NCAyMC44NjE3NjggNi42NzA5ODQgMjAuODM3ODU4IDYuNjQ3MDczIDIwLjgwMTk5M0M2LjIxNjY4NyAyMC4zNzE2MDYgNS41NzExMDggMTkuNzE0MDcyIDQuODI5ODg4IDE4LjM5OTAwNEMzLjUzODczIDE2LjEwMzYxMSAzLjA2MDUyMyAxMy4xNTA2ODUgMy4wNjA1MjMgMTAuMjgxNDQ1QzMuMDYwNTIzIDQuOTczMzUgNC41NjY4NzQgMS44NTMwNTEgNi42NTkwMjktLjI2MzAxNEM2LjY5NDg5NC0uMjk4ODc5IDYuNjk0ODk0LS4zMzQ3NDUgNi42OTQ4OTQtLjM1ODY1NUM2LjY5NDg5NC0uNDc4MjA3IDYuNjExMjA4LS40NzgyMDcgNi40Njc3NDYtLjQ3ODIwN0M2LjMxMjMyOS0uNDc4MjA3IDYuMjg4NDE4LS40NzgyMDcgNi4xODA4MjItLjM4MjU2NUM1LjA0NTA4MSAuNTk3NzU4IDMuNzY1ODc4IDIuMjU5NTI3IDIuOTQwOTcxIDQuNzgyMDY3QzIuNDI2ODk5IDYuMzYwMTQ5IDIuMTUxOTMgOC4yODQ5MzIgMi4xNTE5MyAxMC4yNjk0ODlDMi4xNTE5MyAxMy4xMDI4NjQgMi42NjYwMDIgMTYuMzA2ODQ5IDQuNTQyOTY0IDE5LjA4MDQ0OEM0Ljg2NTc1MyAxOS41NDY3IDUuMzA4MDk1IDIwLjAzNjg2MiA1LjMwODA5NSAyMC4wNDg4MTdDNS40Mjc2NDYgMjAuMTkyMjc5IDUuNTk1MDE5IDIwLjM4MzU2MiA1LjY5MDY2IDIwLjQ2NzI0OEw2LjE1NjkxMiAyMC44OTc2MzRaJy8+CjxwYXRoIGlkPSdnNDAtMTcnIGQ9J000Ljk3MzM1IDEwLjI2OTQ4OUM0Ljk3MzM1IDYuODM4MzU2IDQuMTcyMzU0IDMuMTkyMDMgMS44MTcxODYgLjUwMjExN0MxLjY0OTgxMyAuMzEwODM0IDEuMjA3NDcyLS4xNTU0MTcgLjkyMDU0OC0uNDA2NDc2Qy44MzY4NjItLjQ3ODIwNyAuODEyOTUxLS40NzgyMDcgLjY1NzUzNC0uNDc4MjA3Qy41Mzc5ODMtLjQ3ODIwNyAuNDMwMzg2LS40NzgyMDcgLjQzMDM4Ni0uMzU4NjU1Qy40MzAzODYtLjMxMDgzNCAuNDc4MjA3LS4yNjMwMTQgLjUwMjExNy0uMjM5MTAzQy45MDg1OTMgLjE3OTMyOCAxLjU1NDE3MiAuODM2ODYyIDIuMjk1MzkyIDIuMTUxOTNDMy41ODY1NSA0LjQ0NzMyMyA0LjA2NDc1NyA3LjQwMDI0OSA0LjA2NDc1NyAxMC4yNjk0ODlDNC4wNjQ3NTcgMTUuNDU4MDMyIDIuNjMwMTM3IDE4LjYyNjE1MiAuNDc4MjA3IDIwLjgxMzk0OEMuNDU0Mjk2IDIwLjgzNzg1OCAuNDMwMzg2IDIwLjg3MzcyNCAuNDMwMzg2IDIwLjkwOTU4OUMuNDMwMzg2IDIxLjAyOTE0MSAuNTM3OTgzIDIxLjAyOTE0MSAuNjU3NTM0IDIxLjAyOTE0MUMuODEyOTUxIDIxLjAyOTE0MSAuODM2ODYyIDIxLjAyOTE0MSAuOTQ0NDU4IDIwLjkzMzQ5OUMyLjA4MDE5OSAxOS45NTMxNzYgMy4zNTk0MDIgMTguMjkxNDA3IDQuMTg0MzA5IDE1Ljc2ODg2N0M0LjcxMDMzNiAxNC4xMzEwMDkgNC45NzMzNSAxMi4xOTQyNzEgNC45NzMzNSAxMC4yNjk0ODlaJy8+Cjx1c2UgaWQ9J2cxOS00OCcgeGxpbms6aHJlZj0nI2cxLTQ4JyB0cmFuc2Zvcm09J3NjYWxlKDEuMTQxNTUzKScvPgo8dXNlIGlkPSdnMTktNDknIHhsaW5rOmhyZWY9JyNnMS00OScgdHJhbnNmb3JtPSdzY2FsZSgxLjE0MTU1MyknLz4KPHVzZSBpZD0nZzE5LTUwJyB4bGluazpocmVmPScjZzEtNTAnIHRyYW5zZm9ybT0nc2NhbGUoMS4xNDE1NTMpJy8+Cjx1c2UgaWQ9J2cxOS01MScgeGxpbms6aHJlZj0nI2cxLTUxJyB0cmFuc2Zvcm09J3NjYWxlKDEuMTQxNTUzKScvPgo8dXNlIGlkPSdnMTktNTInIHhsaW5rOmhyZWY9JyNnMS01MicgdHJhbnNmb3JtPSdzY2FsZSgxLjE0MTU1MyknLz4KPHVzZSBpZD0nZzE5LTUzJyB4bGluazpocmVmPScjZzEtNTMnIHRyYW5zZm9ybT0nc2NhbGUoMS4xNDE1NTMpJy8+Cjx1c2UgaWQ9J2cxOS01NCcgeGxpbms6aHJlZj0nI2cxLTU0JyB0cmFuc2Zvcm09J3NjYWxlKDEuMTQxNTUzKScvPgo8dXNlIGlkPSdnMTktNTUnIHhsaW5rOmhyZWY9JyNnMS01NScgdHJhbnNmb3JtPSdzY2FsZSgxLjE0MTU1MyknLz4KPHVzZSBpZD0nZzE5LTU2JyB4bGluazpocmVmPScjZzEtNTYnIHRyYW5zZm9ybT0nc2NhbGUoMS4xNDE1NTMpJy8+Cjx1c2UgaWQ9J2cxOS01NycgeGxpbms6aHJlZj0nI2cxLTU3JyB0cmFuc2Zvcm09J3NjYWxlKDEuMTQxNTUzKScvPgo8dXNlIGlkPSdnMTktNTgnIHhsaW5rOmhyZWY9JyNnMS01OCcgdHJhbnNmb3JtPSdzY2FsZSgxLjE0MTU1MyknLz4KPHBhdGggaWQ9J2c1My00MCcgZD0nTTMuODg1NDMgMi45MDUxMDZDMy44ODU0MyAyLjg2OTI0IDMuODg1NDMgMi44NDUzMyAzLjY4MjE5MiAyLjY0MjA5MkMyLjQ4NjY3NSAxLjQzNDYyIDEuODE3MTg2LS41Mzc5ODMgMS44MTcxODYtMi45NzY4MzdDMS44MTcxODYtNS4yOTYxMzkgMi4zNzkwNzgtNy4yOTI2NTMgMy43NjU4NzgtOC43MDMzNjJDMy44ODU0My04LjgxMDk1OSAzLjg4NTQzLTguODM0ODY5IDMuODg1NDMtOC44NzA3MzVDMy44ODU0My04Ljk0MjQ2NiAzLjgyNTY1NC04Ljk2NjM3NiAzLjc3NzgzMy04Ljk2NjM3NkMzLjYyMjQxNi04Ljk2NjM3NiAyLjY0MjA5Mi04LjEwNTYwNCAyLjA1NjI4OS02LjkzMzk5OEMxLjQ0NjU3NS01LjcyNjUyNiAxLjE3MTYwNi00LjQ0NzMyMyAxLjE3MTYwNi0yLjk3NjgzN0MxLjE3MTYwNi0xLjkxMjgyNyAxLjMzODk3OS0uNDkwMTYyIDEuOTYwNjQ4IC43ODkwNDFDMi42NjYwMDIgMi4yMjM2NjEgMy42NDYzMjYgMy4wMDA3NDcgMy43Nzc4MzMgMy4wMDA3NDdDMy44MjU2NTQgMy4wMDA3NDcgMy44ODU0MyAyLjk3NjgzNyAzLjg4NTQzIDIuOTA1MTA2WicvPgo8cGF0aCBpZD0nZzUzLTQxJyBkPSdNMy4zNzEzNTctMi45NzY4MzdDMy4zNzEzNTctMy44ODU0MyAzLjI1MTgwNi01LjM2Nzg3IDIuNTgyMzE2LTYuNzU0NjdDMS44NzY5NjEtOC4xODkyOSAuODk2NjM4LTguOTY2Mzc2IC43NjUxMzEtOC45NjYzNzZDLjcxNzMxLTguOTY2Mzc2IC42NTc1MzQtOC45NDI0NjYgLjY1NzUzNC04Ljg3MDczNUMuNjU3NTM0LTguODM0ODY5IC42NTc1MzQtOC44MTA5NTkgLjg2MDc3Mi04LjYwNzcyMUMyLjA1NjI4OS03LjQwMDI0OSAyLjcyNTc3OC01LjQyNzY0NiAyLjcyNTc3OC0yLjk4ODc5MkMyLjcyNTc3OC0uNjY5NDg5IDIuMTYzODg1IDEuMzI3MDI0IC43NzcwODYgMi43Mzc3MzNDLjY1NzUzNCAyLjg0NTMzIC42NTc1MzQgMi44NjkyNCAuNjU3NTM0IDIuOTA1MTA2Qy42NTc1MzQgMi45NzY4MzcgLjcxNzMxIDMuMDAwNzQ3IC43NjUxMzEgMy4wMDA3NDdDLjkyMDU0OCAzLjAwMDc0NyAxLjkwMDg3MiAyLjEzOTk3NSAyLjQ4NjY3NSAuOTY4MzY5QzMuMDk2Mzg5LS4yNTEwNTkgMy4zNzEzNTctMS41NDIyMTcgMy4zNzEzNTctMi45NzY4MzdaJy8+CjxwYXRoIGlkPSdnNTMtNDMnIGQ9J000Ljc3MDExMi0yLjc2MTY0NEg4LjA2OTczOEM4LjIzNzExMS0yLjc2MTY0NCA4LjQ1MjMwNC0yLjc2MTY0NCA4LjQ1MjMwNC0yLjk3NjgzN0M4LjQ1MjMwNC0zLjIwMzk4NSA4LjI0OTA2Ni0zLjIwMzk4NSA4LjA2OTczOC0zLjIwMzk4NUg0Ljc3MDExMlYtNi41MDM2MTFDNC43NzAxMTItNi42NzA5ODQgNC43NzAxMTItNi44ODYxNzcgNC41NTQ5MTktNi44ODYxNzdDNC4zMjc3NzEtNi44ODYxNzcgNC4zMjc3NzEtNi42ODI5MzkgNC4zMjc3NzEtNi41MDM2MTFWLTMuMjAzOTg1SDEuMDI4MTQ0Qy44NjA3NzItMy4yMDM5ODUgLjY0NTU3OS0zLjIwMzk4NSAuNjQ1NTc5LTIuOTg4NzkyQy42NDU1NzktMi43NjE2NDQgLjg0ODgxNy0yLjc2MTY0NCAxLjAyODE0NC0yLjc2MTY0NEg0LjMyNzc3MVYuNTM3OTgzQzQuMzI3NzcxIC43MDUzNTUgNC4zMjc3NzEgLjkyMDU0OCA0LjU0Mjk2NCAuOTIwNTQ4QzQuNzcwMTEyIC45MjA1NDggNC43NzAxMTIgLjcxNzMxIDQuNzcwMTEyIC41Mzc5ODNWLTIuNzYxNjQ0WicvPgo8cGF0aCBpZD0nZzUzLTQ4JyBkPSdNNS4zNTU5MTUtMy44MjU2NTRDNS4zNTU5MTUtNC44MTc5MzMgNS4yOTYxMzktNS43ODYzMDEgNC44NjU3NTMtNi42OTQ4OTRDNC4zNzU1OTItNy42ODcxNzMgMy41MTQ4MTktNy45NTAxODcgMi45MjkwMTYtNy45NTAxODdDMi4yMzU2MTYtNy45NTAxODcgMS4zODY4LTcuNjAzNDg3IC45NDQ0NTgtNi42MTEyMDhDLjYwOTcxNC01Ljg1ODAzMiAuNDkwMTYyLTUuMTE2ODEyIC40OTAxNjItMy44MjU2NTRDLjQ5MDE2Mi0yLjY2NjAwMiAuNTczODQ4LTEuNzkzMjc1IDEuMDA0MjM0LS45NDQ0NThDMS40NzA0ODYtLjAzNTg2NiAyLjI5NTM5MiAuMjUxMDU5IDIuOTE3MDYxIC4yNTEwNTlDMy45NTcxNjEgLjI1MTA1OSA0LjU1NDkxOS0uMzcwNjEgNC45MDE2MTktMS4wNjQwMUM1LjMzMjAwNS0xLjk2MDY0OCA1LjM1NTkxNS0zLjEzMjI1NCA1LjM1NTkxNS0zLjgyNTY1NFpNMi45MTcwNjEgLjAxMTk1NUMyLjUzNDQ5NiAuMDExOTU1IDEuNzU3NDEtLjIwMzIzOCAxLjUzMDI2Mi0xLjUwNjM1MUMxLjM5ODc1NS0yLjIyMzY2MSAxLjM5ODc1NS0zLjEzMjI1NCAxLjM5ODc1NS0zLjk2OTExNkMxLjM5ODc1NS00Ljk0OTQ0IDEuMzk4NzU1LTUuODM0MTIyIDEuNTkwMDM3LTYuNTM5NDc3QzEuNzkzMjc1LTcuMzQwNDczIDIuNDAyOTg5LTcuNzExMDgzIDIuOTE3MDYxLTcuNzExMDgzQzMuMzcxMzU3LTcuNzExMDgzIDQuMDY0NzU3LTcuNDM2MTE1IDQuMjkxOTA1LTYuNDA3OTdDNC40NDczMjMtNS43MjY1MjYgNC40NDczMjMtNC43ODIwNjcgNC40NDczMjMtMy45NjkxMTZDNC40NDczMjMtMy4xNjgxMiA0LjQ0NzMyMy0yLjI1OTUyNyA0LjMxNTgxNi0xLjUzMDI2MkM0LjA4ODY2Ny0uMjE1MTkzIDMuMzM1NDkyIC4wMTE5NTUgMi45MTcwNjEgLjAxMTk1NVonLz4KPHBhdGggaWQ9J2c1My00OScgZD0nTTMuNDQzMDg4LTcuNjYzMjYzQzMuNDQzMDg4LTcuOTM4MjMyIDMuNDQzMDg4LTcuOTUwMTg3IDMuMjAzOTg1LTcuOTUwMTg3QzIuOTE3MDYxLTcuNjI3Mzk3IDIuMzE5MzAzLTcuMTg1MDU2IDEuMDg3OTItNy4xODUwNTZWLTYuODM4MzU2QzEuMzYyODg5LTYuODM4MzU2IDEuOTYwNjQ4LTYuODM4MzU2IDIuNjE4MTgyLTcuMTQ5MTkxVi0uOTIwNTQ4QzIuNjE4MTgyLS40OTAxNjIgMi41ODIzMTYtLjM0NjcgMS41MzAyNjItLjM0NjdIMS4xNTk2NTFWMEMxLjQ4MjQ0MS0uMDIzOTEgMi42NDIwOTItLjAyMzkxIDMuMDM2NjEzLS4wMjM5MVM0LjU3ODgyOS0uMDIzOTEgNC45MDE2MTkgMFYtLjM0NjdINC41MzEwMDlDMy40Nzg5NTQtLjM0NjcgMy40NDMwODgtLjQ5MDE2MiAzLjQ0MzA4OC0uOTIwNTQ4Vi03LjY2MzI2M1onLz4KPHBhdGggaWQ9J2c1My01MicgZD0nTTQuMzE1ODE2LTcuNzgyODE0QzQuMzE1ODE2LTguMDA5OTYzIDQuMzE1ODE2LTguMDY5NzM4IDQuMTQ4NDQzLTguMDY5NzM4QzQuMDUyODAyLTguMDY5NzM4IDQuMDE2OTM2LTguMDY5NzM4IDMuOTIxMjk1LTcuOTI2Mjc2TC4zMjI3OS0yLjM0MzIxM1YtMS45OTY1MTNIMy40NjY5OTlWLS45MDg1OTNDMy40NjY5OTktLjQ2NjI1MiAzLjQ0MzA4OC0uMzQ2NyAyLjU3MDM2MS0uMzQ2N0gyLjMzMTI1OFYwQzIuNjA2MjI3LS4wMjM5MSAzLjU1MDY4NS0uMDIzOTEgMy44ODU0My0uMDIzOTFTNS4xNzY1ODgtLjAyMzkxIDUuNDUxNTU3IDBWLS4zNDY3SDUuMjEyNDUzQzQuMzUxNjgxLS4zNDY3IDQuMzE1ODE2LS40NjYyNTIgNC4zMTU4MTYtLjkwODU5M1YtMS45OTY1MTNINS41MjMyODhWLTIuMzQzMjEzSDQuMzE1ODE2Vi03Ljc4MjgxNFpNMy41MjY3NzUtNi44NTAzMTFWLTIuMzQzMjEzSC42MjE2NjlMMy41MjY3NzUtNi44NTAzMTFaJy8+CjxwYXRoIGlkPSdnNTMtNTMnIGQ9J00xLjUzMDI2Mi02Ljg1MDMxMUMyLjA0NDMzNC02LjY4MjkzOSAyLjQ2Mjc2NS02LjY3MDk4NCAyLjU5NDI3MS02LjY3MDk4NEMzLjk0NTIwNS02LjY3MDk4NCA0LjgwNTk3OC03LjY2MzI2MyA0LjgwNTk3OC03LjgzMDYzNUM0LjgwNTk3OC03Ljg3ODQ1NiA0Ljc4MjA2Ny03LjkzODIzMiA0LjcxMDMzNi03LjkzODIzMkM0LjY4NjQyNi03LjkzODIzMiA0LjY2MjUxNi03LjkzODIzMiA0LjU1NDkxOS03Ljg5MDQxMUMzLjg4NTQzLTcuNjAzNDg3IDMuMzExNTgyLTcuNTY3NjIxIDMuMDAwNzQ3LTcuNTY3NjIxQzIuMjExNzA2LTcuNTY3NjIxIDEuNjQ5ODEzLTcuODA2NzI1IDEuNDIyNjY1LTcuOTAyMzY2QzEuMzM4OTc5LTcuOTM4MjMyIDEuMzE1MDY4LTcuOTM4MjMyIDEuMzAzMTEzLTcuOTM4MjMyQzEuMjA3NDcyLTcuOTM4MjMyIDEuMjA3NDcyLTcuODY2NTAxIDEuMjA3NDcyLTcuNjc1MjE4Vi00LjEyNDUzM0MxLjIwNzQ3Mi0zLjkwOTM0IDEuMjA3NDcyLTMuODM3NjA5IDEuMzUwOTM0LTMuODM3NjA5QzEuNDEwNzEtMy44Mzc2MDkgMS40MjI2NjUtMy44NDk1NjQgMS41NDIyMTctMy45OTMwMjZDMS44NzY5NjEtNC40ODMxODggMi40Mzg4NTQtNC43NzAxMTIgMy4wMzY2MTMtNC43NzAxMTJDMy42NzAyMzctNC43NzAxMTIgMy45ODEwNzEtNC4xODQzMDkgNC4wNzY3MTItMy45ODEwNzFDNC4yNzk5NS0zLjUxNDgxOSA0LjI5MTkwNS0yLjkyOTAxNiA0LjI5MTkwNS0yLjQ3NDcyUzQuMjkxOTA1LTEuMzM4OTc5IDMuOTU3MTYxLS44MDA5OTZDMy42OTQxNDctLjM3MDYxIDMuMjI3ODk1LS4wNzE3MzEgMi43MDE4NjgtLjA3MTczMUMxLjkxMjgyNy0uMDcxNzMxIDEuMTM1NzQxLS42MDk3MTQgLjkyMDU0OC0xLjQ4MjQ0MUMuOTgwMzI0LTEuNDU4NTMxIDEuMDUyMDU1LTEuNDQ2NTc1IDEuMTExODMxLTEuNDQ2NTc1QzEuMzE1MDY4LTEuNDQ2NTc1IDEuNjM3ODU4LTEuNTY2MTI3IDEuNjM3ODU4LTEuOTcyNjAzQzEuNjM3ODU4LTIuMzA3MzQ3IDEuNDEwNzEtMi40OTg2MyAxLjExMTgzMS0yLjQ5ODYzQy44OTY2MzgtMi40OTg2MyAuNTg1ODAzLTIuMzkxMDM0IC41ODU4MDMtMS45MjQ3ODJDLjU4NTgwMy0uOTA4NTkzIDEuMzk4NzU1IC4yNTEwNTkgMi43MjU3NzggLjI1MTA1OUM0LjA3NjcxMiAuMjUxMDU5IDUuMjYwMjc0LS44ODQ2ODIgNS4yNjAyNzQtMi40MDI5ODlDNS4yNjAyNzQtMy44MjU2NTQgNC4zMDM4NjEtNS4wMDkyMTUgMy4wNDg1NjgtNS4wMDkyMTVDMi4zNjcxMjMtNS4wMDkyMTUgMS44NDEwOTYtNC43MTAzMzYgMS41MzAyNjItNC4zNzU1OTJWLTYuODUwMzExWicvPgo8cGF0aCBpZD0nZzUzLTYxJyBkPSdNOC4wNjk3MzgtMy44NzM0NzRDOC4yMzcxMTEtMy44NzM0NzQgOC40NTIzMDQtMy44NzM0NzQgOC40NTIzMDQtNC4wODg2NjdDOC40NTIzMDQtNC4zMTU4MTYgOC4yNDkwNjYtNC4zMTU4MTYgOC4wNjk3MzgtNC4zMTU4MTZIMS4wMjgxNDRDLjg2MDc3Mi00LjMxNTgxNiAuNjQ1NTc5LTQuMzE1ODE2IC42NDU1NzktNC4xMDA2MjNDLjY0NTU3OS0zLjg3MzQ3NCAuODQ4ODE3LTMuODczNDc0IDEuMDI4MTQ0LTMuODczNDc0SDguMDY5NzM4Wk04LjA2OTczOC0xLjY0OTgxM0M4LjIzNzExMS0xLjY0OTgxMyA4LjQ1MjMwNC0xLjY0OTgxMyA4LjQ1MjMwNC0xLjg2NTAwNkM4LjQ1MjMwNC0yLjA5MjE1NCA4LjI0OTA2Ni0yLjA5MjE1NCA4LjA2OTczOC0yLjA5MjE1NEgxLjAyODE0NEMuODYwNzcyLTIuMDkyMTU0IC42NDU1NzktMi4wOTIxNTQgLjY0NTU3OS0xLjg3Njk2MUMuNjQ1NTc5LTEuNjQ5ODEzIC44NDg4MTctMS42NDk4MTMgMS4wMjgxNDQtMS42NDk4MTNIOC4wNjk3MzhaJy8+CjxwYXRoIGlkPSdnNTMtOTEnIGQ9J00yLjk4ODc5MiAyLjk4ODc5MlYyLjU0NjQ1MUgxLjgyOTE0MVYtOC41MjQwMzVIMi45ODg3OTJWLTguOTY2Mzc2SDEuMzg2OFYyLjk4ODc5MkgyLjk4ODc5MlonLz4KPHBhdGggaWQ9J2c1My05MycgZD0nTTEuODUzMDUxLTguOTY2Mzc2SC4yNTEwNTlWLTguNTI0MDM1SDEuNDEwNzFWMi41NDY0NTFILjI1MTA1OVYyLjk4ODc5MkgxLjg1MzA1MVYtOC45NjYzNzZaJy8+CjxwYXRoIGlkPSdnOC00OScgZD0nTTMuNzc1NjMtOC4xOTQ0MjdMLjc3NDE4My02Ljg5NjE4MlYtNi41ODY1MDlDLjg4MTM3Ny02LjYyMjI0IC45NzY2NjEtNi42NTc5NzIgMS4wMTIzOTMtNi42ODE3OTNDMS4zMzM5NzYtNi44MDA4OTggMS42MzE3MzktNi44ODQyNzEgMS43ODY1NzYtNi44ODQyNzFDMi4wODQzMzgtNi44ODQyNzEgMi4yMTUzNTQtNi42MjIyNCAyLjIxNTM1NC02LjA2MjQ0NlYtMS40NzY5MDJDMi4yMTUzNTQtLjUwMDI0MSAxLjk3NzE0NC0uMjk3NzYzIC43OTgwMDQtLjI4NTg1MlYwSDUuMjY0NDQzVi0uMjg1ODUyQzQuMTgwNTg3LS4zMDk2NzMgMy45NzgxMDgtLjQ4ODMzMSAzLjk3ODEwOC0xLjQwNTQzOVYtOC4xOTQ0MjdIMy43NzU2M1onLz4KPHBhdGggaWQ9J2c4LTU4JyBkPSdNMS45NzcxNDQtMS44NTgwMzlDMS40MjkyNi0xLjg1ODAzOSAuOTc2NjYxLTEuMzkzNTI5IC45NzY2NjEtLjg1NzU1NkMuOTc2NjYxLS4yODU4NTIgMS40MDU0MzkgLjE1NDgzNyAxLjk2NTIzMyAuMTU0ODM3QzIuNTM2OTM3IC4xNTQ4MzcgMi45ODk1MzYtLjI4NTg1MiAyLjk4OTUzNi0uODMzNzM1QzIuOTg5NTM2LTEuMzkzNTI5IDIuNTM2OTM3LTEuODU4MDM5IDEuOTc3MTQ0LTEuODU4MDM5Wk0xLjk3NzE0NC01LjYyMTc1OEMxLjQyOTI2LTUuNjIxNzU4IC45NzY2NjEtNS4xNjkxNTkgLjk3NjY2MS00LjYzMzE4NkMuOTc2NjYxLTQuMDQ5NTcxIDEuNDA1NDM5LTMuNjA4ODgzIDEuOTc3MTQ0LTMuNjA4ODgzQzIuNTM2OTM3LTMuNjA4ODgzIDIuOTg5NTM2LTQuMDYxNDgyIDIuOTg5NTM2LTQuNjA5MzY1QzIuOTg5NTM2LTUuMTY5MTU5IDIuNTM2OTM3LTUuNjIxNzU4IDEuOTc3MTQ0LTUuNjIxNzU4WicvPgo8cGF0aCBpZD0nZzgtNjUnIGQ9J004LjIwNjMzNy0uMjk3NzYzSDguMTU4Njk1QzcuNjk0MTg1LS4yOTc3NjMgNy41MDM2MTctLjU0Nzg4MyA2LjkwODA5Mi0xLjk1MzMyM0w0LjI1MjA1LTguMjE4MjQ4SDMuOTE4NTU2TDEuMjc0NDI0LTEuNjkxMjkyQy44MjE4MjUtLjU4MzYxNSAuNjc4ODk5LS40MDQ5NTcgLjEwNzE5NS0uMjk3NzYzVjBIMi41MjUwMjdWLS4yOTc3NjNDMS44MjIzMDctLjM0NTQwNSAxLjU0ODM2NS0uNDc2NDIgMS41NDgzNjUtLjc4NjA5M0MxLjU0ODM2NS0uOTQwOTMgMS42NDM2NS0xLjIzODY5MiAxLjg5Mzc3LTEuODgxODZMMi4wNzI0MjgtMi4zNDYzNjlINC43NTIyOTFDNS4xNTcyNDgtMS40MTczNSA1LjMwMDE3NC0uOTg4NTcyIDUuMzAwMTc0LS43MjY1NDFDNS4zMDAxNzQtLjQ3NjQyIDUuMTQ1MzM4LS4zNTczMTUgNC43Mjg0Ny0uMzMzNDk0QzQuNjY4OTE3LS4zMzM0OTQgNC41MTQwODEtLjMyMTU4NCA0LjM0NzMzNC0uMjk3NzYzVjBIOC4yMDYzMzdWLS4yOTc3NjNaTTIuMjUxMDg1LTIuODEwODc5TDMuMzcwNjczLTUuNzA1MTMxTDQuNTczNjMzLTIuODEwODc5SDIuMjUxMDg1WicvPgo8cGF0aCBpZD0nZzgtNzMnIGQ9J00xLjM0NTg4Ny0xLjE0MzQwOEMxLjM0NTg4Ny0uNTQ3ODgzIDEuMTMxNDk4LS4zODExMzYgLjIzODIxLS4yOTc3NjNWMEg0LjQwNjg4NlYtLjI5Nzc2M0MzLjUwMTY4OC0uMzU3MzE1IDMuMjc1Mzg5LS41MjQwNjIgMy4yNzUzODktMS4xNDM0MDhWLTYuOTA4MDkyQzMuMjc1Mzg5LTcuNTI3NDM4IDMuNTI1NTA5LTcuNzE4MDA2IDQuNDA2ODg2LTcuNzUzNzM4Vi04LjA1MTUwMUguMjM4MjFWLTcuNzUzNzM4QzEuMDk1NzY2LTcuNjk0MTg1IDEuMzQ1ODg3LTcuNTE1NTI4IDEuMzQ1ODg3LTYuOTA4MDkyVi0xLjE0MzQwOFonLz4KPHBhdGggaWQ9J2c4LTc5JyBkPSdNNC42ODA4MjgtOC4yMzAxNThDMi4xOTE1MzMtOC4yMzAxNTggLjQxNjg2OC02LjQ2NzQwNCAuNDE2ODY4LTMuOTkwMDE5Qy40MTY4NjgtMS41MjQ1NDQgMi4xNjc3MTIgLjIyNjMgNC42MzMxODYgLjIyNjNTOC44NDk1MDQtMS41MzY0NTUgOC44NDk1MDQtNC4wMDE5MjlDOC44NDk1MDQtNi40MzE2NzIgNy4wNzQ4MzktOC4yMzAxNTggNC42ODA4MjgtOC4yMzAxNThaTTQuNjY4OTE3LTcuODM3MTExQzUuOTc5MDczLTcuODM3MTExIDYuNzQxMzQ1LTYuMzk1OTQxIDYuNzQxMzQ1LTMuOTE4NTU2QzYuNzQxMzQ1LTEuNDc2OTAyIDYuMDAyODk0LS4xNjY3NDcgNC42MzMxODYtLjE2Njc0N1MyLjUyNTAyNy0xLjQ3NjkwMiAyLjUyNTAyNy0zLjg4MjgyNEMyLjUyNTAyNy02LjQ1NTQ5MyAzLjI3NTM4OS03LjgzNzExMSA0LjY2ODkxNy03LjgzNzExMVonLz4KPHBhdGggaWQ9J2c4LTgzJyBkPSdNNS43NjQ2ODQtNS42NTc0ODlWLTguMjQyMDY5SDUuNDA3MzY5QzUuMzIzOTk1LTcuOTMyMzk1IDUuMjI4NzExLTcuODM3MTExIDUuMDI2MjMzLTcuODM3MTExQzQuOTE5MDM4LTcuODM3MTExIDQuNzg4MDIyLTcuODcyODQzIDQuNTI1OTkxLTcuOTY4MTI3QzMuOTY2MTk4LTguMTU4Njk1IDMuNTg1MDYyLTguMjMwMTU4IDMuMTMyNDYyLTguMjMwMTU4QzEuNTEyNjM0LTguMjMwMTU4IC41MjQwNjItNy4zMTMwNDkgLjUyNDA2Mi01LjgxMjMyNkMuNTI0MDYyLTQuNzY0MjAxIDEuMTQzNDA4LTQuMDEzODQgMi41NjA3NTgtMy4zMzQ5NDFMMy4zNTg3NjItMi45NTM4MDVDNC40MDY4ODYtMi40NTM1NjQgNC42OTI3MzgtMi4xNDM4OTEgNC42OTI3MzgtMS41MjQ1NDRDNC42OTI3MzgtLjcwMjcyIDQuMTA5MTI0LS4xNjY3NDcgMy4xOTIwMTUtLjE2Njc0N0MyLjUwMTIwNi0uMTY2NzQ3IDEuOTA1NjgxLS40NjQ1MSAxLjQ1MzA4MS0xLjA0ODEyNEMxLjEzMTQ5OC0xLjQ4ODgxMyAuOTY0NzUxLTEuODgxODYgLjc2MjI3Mi0yLjcxNTU5NUguNDE2ODY4Vi4yMjYzSC43NjIyNzJDLjgzMzczNS0uMDcxNDYzIC45MjkwMTktLjE3ODY1OCAxLjExOTU4Ny0uMTc4NjU4QzEuMjE0ODcxLS4xNzg2NTggMS4zNDU4ODctLjE0MjkyNiAxLjYwNzkxOC0uMDU5NTUzQzIuMjAzNDQzIC4xNDI5MjYgMi42NDQxMzIgLjIyNjMgMy4xNTYyODMgLjIyNjNDNC45MTkwMzggLjIyNjMgNi4xMTAwODgtLjc4NjA5MyA2LjExMDA4OC0yLjI4NjgxN0M2LjExMDA4OC0zLjE4MDEwNCA1LjU2MjIwNS00LjA3MzM5MiA0Ljc5OTkzMy00LjQ1NDUyOEwzLjA0OTA4OS01LjMyMzk5NUMyLjA4NDMzOC01LjgwMDQxNSAxLjgyMjMwNy02LjA5ODE3OCAxLjgyMjMwNy02LjY2OTg4MkMxLjgyMjMwNy03LjQwODMzMyAyLjMyMjU0OC03Ljg2MDkzMiAzLjEzMjQ2Mi03Ljg2MDkzMkMzLjY2ODQzNS03Ljg2MDkzMiA0LjE2ODY3Ni03LjYzNDYzMyA0LjU5NzQ1NC03LjE5Mzk0NEM1LjAwMjQxMi02Ljc3NzA3NyA1LjE5Mjk4LTYuNDMxNjcyIDUuNDMxMTktNS42NTc0ODlINS43NjQ2ODRaJy8+CjxwYXRoIGlkPSdnOC05NycgZD0nTTUuNjMzNjY4LS43NjIyNzJMNS41MTQ1NjMtLjY0MzE2N0M1LjQ3ODgzMi0uNjA3NDM2IDUuNDQzMS0uNTk1NTI1IDUuMzgzNTQ4LS41OTU1MjVDNS4yMTY4MDEtLjU5NTUyNSA1LjEzMzQyNy0uNzAyNzIgNS4xMzM0MjctLjg5MzI4OFYtNC4wMDE5MjlDNS4xMzM0MjctNS4wMDI0MTIgNC4yMjgyMjktNS42MzM2NjggMi43NzUxNDctNS42MzM2NjhDMS40MjkyNi01LjYzMzY2OCAuNTI0MDYyLTUuMDI2MjMzIC41MjQwNjItNC4xMzI5NDVDLjUyNDA2Mi0zLjY0NDYxNCAuODA5OTE0LTMuMzQ2ODUyIDEuMjk4MjQ1LTMuMzQ2ODUyQzEuNzc0NjY1LTMuMzQ2ODUyIDIuMTA4MTU5LTMuNjMyNzA0IDIuMTA4MTU5LTQuMDM3NjYxQzIuMTA4MTU5LTQuMjA0NDA4IDIuMDM2Njk2LTQuMzU5MjQ0IDEuODkzNzctNC41NDk4MTJDMS43ODY1NzYtNC42Njg5MTcgMS43NTA4NDQtNC43NDAzOCAxLjc1MDg0NC00LjgxMTg0NEMxLjc1MDg0NC01LjA2MTk2NCAyLjA4NDMzOC01LjI1MjUzMiAyLjUwMTIwNi01LjI1MjUzMkMzLjE5MjAxNS01LjI1MjUzMiAzLjUwMTY4OC00LjkzMDk0OSAzLjUwMTY4OC00LjIwNDQwOFYtMy4zMzQ5NDFDMi4wODQzMzgtMi45MDYxNjMgMS41MDA3MjMtMi42Njc5NTMgMS4wNjAwMzUtMi4zNzAxOUMuNTQ3ODgzLTIuMDEyODc1IC4yOTc3NjMtMS42MDc5MTggLjI5Nzc2My0xLjA5NTc2NkMuMjk3NzYzLS4zNjkyMjYgLjg1NzU1NiAuMTY2NzQ3IDEuNjE5ODI5IC4xNjY3NDdDMi4yOTg3MjcgLjE2Njc0NyAyLjg0NjYxLS4wNzE0NjMgMy41MDE2ODgtLjY2Njk4OEMzLjYzMjcwNC0uMDU5NTUzIDMuODk0NzM1IC4xNjY3NDcgNC40NzgzNDkgLjE2Njc0N0M0Ljk5MDUwMSAuMTY2NzQ3IDUuMzU5NzI3LS4wMjM4MjEgNS44MTIzMjYtLjUxMjE1Mkw1LjYzMzY2OC0uNzYyMjcyWk0zLjQ4OTc3OC0xLjE5MTA1QzMuMTY4MTk0LS44MjE4MjUgMi45Mjk5ODQtLjY3ODg5OSAyLjY0NDEzMi0uNjc4ODk5QzIuMjg2ODE3LS42Nzg4OTkgMi4wMzY2OTYtMS4wMDA0ODIgMi4wMzY2OTYtMS40NzY5MDJDMi4wMzY2OTYtMi4xNjc3MTIgMi41MzY5MzctMi42Njc5NTMgMy40ODk3NzgtMi45MTgwNzNWLTEuMTkxMDVaJy8+CjxwYXRoIGlkPSdnOC05OCcgZD0nTTIuNTEzMTE2LTguMDUxNTAxSC4yMDI0NzlWLTcuNzY1NjQ4Qy43NTAzNjItNy42NTg0NTQgLjg1NzU1Ni03LjU1MTI1OSAuODU3NTU2LTcuMDc0ODM5Vi4xNTQ4MzdIMS4wMDA0ODJMMS45NDE0MTItLjUxMjE1MkMyLjQ4OTI5NS0uMDIzODIxIDIuOTE4MDczIC4xNjY3NDcgMy41MTM1OTkgLjE2Njc0N0M1LjA5NzY5NiAuMTY2NzQ3IDYuMjA1MzcyLTEuMDcxOTQ1IDYuMjA1MzcyLTIuODQ2NjFDNi4yMDUzNzItNC40OTAyNiA1LjI4ODI2NC01LjYzMzY2OCAzLjk2NjE5OC01LjYzMzY2OEMzLjM5NDQ5NC01LjYzMzY2OCAyLjk1MzgwNS01LjQzMTE5IDIuNTEzMTE2LTQuOTY2NjhWLTguMDUxNTAxWk0yLjUxMzExNi00LjI4Nzc4MUMyLjcxNTU5NS00Ljc5OTkzMyAyLjk1MzgwNS00Ljk5MDUwMSAzLjM0Njg1Mi00Ljk5MDUwMUM0LjA4NTMwMy00Ljk5MDUwMSA0LjQ1NDUyOC00LjE5MjQ5NyA0LjQ1NDUyOC0yLjYzMjIyMUM0LjQ1NDUyOC0uOTg4NTcyIDQuMDk3MjEzLS4yMTQzODkgMy4zMzQ5NDEtLjIxNDM4OUMyLjgzNDctLjIxNDM4OSAyLjUxMzExNi0uNTgzNjE1IDIuNTEzMTE2LTEuMTU1MzE5Vi00LjI4Nzc4MVonLz4KPHBhdGggaWQ9J2c4LTk5JyBkPSdNNC45MDcxMjgtMS4yOTgyNDVDNC40NjY0MzktLjc5ODAwNCA0LjE1Njc2Ni0uNjMxMjU3IDMuNjY4NDM1LS42MzEyNTdDMi42MzIyMjEtLjYzMTI1NyAxLjk3NzE0NC0xLjY2NzQ3MSAxLjk3NzE0NC0zLjI4NzI5OUMxLjk3NzE0NC00LjUxNDA4MSAyLjM1ODI4LTUuMjY0NDQzIDIuOTc3NjI2LTUuMjY0NDQzQzMuMTY4MTk0LTUuMjY0NDQzIDMuMzQ2ODUyLTUuMTY5MTU5IDMuNDE4MzE1LTUuMDM4MTQzQzMuNDc3ODY3LTQuOTMwOTQ5IDMuNDc3ODY3LTQuOTMwOTQ5IDMuNDc3ODY3LTQuNDMwNzA3QzMuNDg5Nzc4LTMuODQ3MDkzIDMuNzA0MTY3LTMuNTczMTUxIDQuMTQ0ODU1LTMuNTczMTUxQzQuNjQ1MDk2LTMuNTczMTUxIDQuOTU0NzctMy44NTkwMDMgNC45NTQ3Ny00LjMyMzUxM0M0Ljk1NDc3LTUuMDYxOTY0IDQuMTU2NzY2LTUuNjMzNjY4IDMuMTA4NjQxLTUuNjMzNjY4QzEuNDg4ODEzLTUuNjMzNjY4IC4yOTc3NjMtNC4zNzExNTUgLjI5Nzc2My0yLjY1NjA0MkMuMjk3NzYzLTEuMDEyMzkzIDEuMzY5NzA4IC4xNjY3NDcgMi44NDY2MSAuMTY2NzQ3QzMuNzYzNzE5IC4xNjY3NDcgNC40MzA3MDctLjIwMjQ3OSA1LjEyMTUxNy0xLjA4Mzg1Nkw0LjkwNzEyOC0xLjI5ODI0NVonLz4KPHBhdGggaWQ9J2c4LTEwMCcgZD0nTTQuMDM3NjYxIC4xNTQ4MzdDNC41ODU1NDQgMCA0Ljg4MzMwNy0uMDU5NTUzIDUuNjIxNzU4LS4xNDI5MjZMNi4zNjAyMDktLjIzODIxVi0uNTEyMTUyQzUuODEyMzI2LS41NDc4ODMgNS42NTc0ODktLjcwMjcyIDUuNjU3NDg5LTEuMjAyOTYxVi04LjA1MTUwMUgzLjA5NjczMVYtNy43NjU2NDhDMy44OTQ3MzUtNy43MDYwOTYgNC4wMDE5MjktNy42MjI3MjIgNC4wMDE5MjktNy4wNzQ4MzlWLTQuODk1MjE3QzMuNDg5Nzc4LTUuNDQzMSAzLjEzMjQ2Mi01LjYzMzY2OCAyLjU4NDU3OS01LjYzMzY2OEMxLjI3NDQyNC01LjYzMzY2OCAuMjk3NzYzLTQuMzU5MjQ0IC4yOTc3NjMtMi42MzIyMjFDLjI5Nzc2My0xLjAxMjM5MyAxLjIwMjk2MSAuMTY2NzQ3IDIuNDUzNTY0IC4xNjY3NDdDMy4wODQ4MiAuMTY2NzQ3IDMuNDc3ODY3LS4wMjM4MjEgNC4wMzc2NjEtLjYxOTM0NlYuMTU0ODM3Wk00LjAwMTkyOS0xLjMzMzk3NkM0LjAwMTkyOS0xLjI2MjUxMyAzLjg4MjgyNC0xLjA2MDAzNSAzLjczOTg5OC0uOTA1MTk4QzMuNTAxNjg4LS42MzEyNTcgMy4yNTE1NjgtLjUwMDI0MSAyLjk4OTUzNi0uNTAwMjQxQzIuMzU4MjgtLjUwMDI0MSAyLjA2MDUxNy0xLjIxNDg3MSAyLjA2MDUxNy0yLjcyNzUwNUMyLjA2MDUxNy00LjI2Mzk2IDIuMzgyMTAxLTQuOTY2NjggMy4wNzI5MS00Ljk2NjY4QzMuNDY1OTU3LTQuOTY2NjggMy44MzUxODItNC42ODA4MjggNC4wMDE5MjktNC4yMjgyMjlWLTEuMzMzOTc2WicvPgo8cGF0aCBpZD0nZzgtMTAxJyBkPSdNNC43ODgwMjItMS40ODg4MTNDNC4zMTE2MDItLjkwNTE5OCAzLjk0MjM3Ny0uNjkwODA5IDMuNDMwMjI1LS42OTA4MDlDMi45NjU3MTUtLjY5MDgwOSAyLjYyMDMxMS0uOTA1MTk4IDIuMzcwMTktMS4zMjIwNjZDMi4xNTU4MDEtMS43MDMyMDIgMi4wNjA1MTctMi4wOTYyNDkgMi4wMTI4NzUtMi45MTgwNzNINS4wMTQzMjJDNC45NDI4NTktMy45MTg1NTYgNC43NjQyMDEtNC40NzgzNDkgNC4zODMwNjUtNC45MzA5NDlDMy45OTAwMTktNS4zOTU0NTggMy40NDIxMzYtNS42MzM2NjggMi43ODcwNTgtNS42MzM2NjhDMS4yOTgyNDUtNS42MzM2NjggLjI5Nzc2My00LjQ1NDUyOCAuMjk3NzYzLTIuNzE1NTk1UzEuMjc0NDI0IC4xNjY3NDcgMi43NTEzMjYgLjE2Njc0N0MzLjcxNjA3NyAuMTY2NzQ3IDQuMjk5NjkyLS4yMTQzODkgNS4wNzM4NzUtMS4zMjIwNjZMNC43ODgwMjItMS40ODg4MTNaTTEuOTUzMzIzLTMuMzU4NzYyQzEuOTg5MDU0LTQuNzg4MDIyIDIuMjAzNDQzLTUuMjY0NDQzIDIuNzg3MDU4LTUuMjY0NDQzQzMuMTIwNTUyLTUuMjY0NDQzIDMuMzQ2ODUyLTUuMDczODc1IDMuNDQyMTM2LTQuNzA0NjQ5QzMuNTAxNjg4LTQuNDc4MzQ5IDMuNTI1NTA5LTQuMTQ0ODU1IDMuNTQ5MzMtMy41Mzc0MlYtMy4zNTg3NjJIMS45NTMzMjNaJy8+CjxwYXRoIGlkPSdnOC0xMDInIGQ9J00uODQ1NjQ2LTQuOTY2NjhWLTEuMDAwNDgyQy44NDU2NDYtLjQ4ODMzMSAuNzE0NjMtLjM0NTQwNSAuMTY2NzQ3LS4yODU4NTJWMEgzLjQ3Nzg2N1YtLjI4NTg1MkMyLjY0NDEzMi0uMzA5NjczIDIuNTAxMjA2LS40NTI1OTkgMi41MDEyMDYtMS4yMjY3ODJWLTQuOTY2NjhIMy41Mzc0MlYtNS40OTA3NDJIMi41MDEyMDZWLTYuOTQzODI0QzIuNTAxMjA2LTcuNTk4OTAxIDIuNjc5ODYzLTcuODYwOTMyIDMuMDk2NzMxLTcuODYwOTMyQzMuMzExMTItNy44NjA5MzIgMy40NDIxMzYtNy43Nzc1NTkgMy40NDIxMzYtNy42MzQ2MzNDMy40NDIxMzYtNy41ODY5OTEgMy40MDY0MDQtNy41MDM2MTcgMy4zMzQ5NDEtNy4zODQ1MTJDMy4yMjc3NDctNy4yMDU4NTUgMy4xODAxMDQtNy4wNzQ4MzkgMy4xODAxMDQtNi45NTU3MzRDMy4xODAxMDQtNi41ODY1MDkgMy40ODk3NzgtNi4zMDA2NTYgMy44OTQ3MzUtNi4zMDA2NTZDNC4zMzU0MjMtNi4zMDA2NTYgNC42MzMxODYtNi41OTg0MTkgNC42MzMxODYtNy4wMzkxMDhDNC42MzMxODYtNy43NDE4MjcgMy45MzA0NjYtOC4yMzAxNTggMi45Mjk5ODQtOC4yMzAxNThDMi4xMzE5OC04LjIzMDE1OCAxLjUxMjYzNC03Ljk0NDMwNiAxLjE5MTA1LTcuNDIwMjQ0Qy45MjkwMTktNy4wMDMzNzYgLjg0NTY0Ni02LjUxNTA0NiAuODQ1NjQ2LTUuNDkwNzQySC4xNjY3NDdWLTQuOTY2NjhILjg0NTY0NlonLz4KPHBhdGggaWQ9J2c4LTEwMycgZD0nTTUuNzQwODYzLTQuNzQwMzhWLTUuMzcxNjM3SDQuMTkyNDk3QzMuNjY4NDM1LTUuNTYyMjA1IDMuMzM0OTQxLTUuNjMzNjY4IDIuODU4NTIxLTUuNjMzNjY4QzEuNDQxMTcxLTUuNjMzNjY4IC40NDA2ODktNC44NDc1NzUgLjQ0MDY4OS0zLjcxNjA3N0MuNDQwNjg5LTMuMzExMTIgLjU5NTUyNS0yLjkxODA3MyAuODY5NDY3LTIuNTg0NTc5QzEuMTMxNDk4LTIuMjk4NzI3IDEuMzU3Nzk3LTIuMTQzODkxIDEuOTE3NTkxLTEuOTA1NjgxQy45NzY2NjEtMS41ODQwOTcgLjUwMDI0MS0xLjEzMTQ5OCAuNTAwMjQxLS41MTIxNTJDLjUwMDI0MS0uMDIzODIxIC43MTQ2MyAuMTkwNTY4IDEuNDc2OTAyIC40NjQ1MUMuNzI2NTQxIC41NzE3MDQgLjMzMzQ5NCAuODY5NDY3IC4zMzM0OTQgMS4zNTc3OTdDLjMzMzQ5NCAyLjA0ODYwNyAxLjIyNjc4MiAyLjQ1MzU2NCAyLjcyNzUwNSAyLjQ1MzU2NEM0LjcwNDY0OSAyLjQ1MzU2NCA1Ljc1Mjc3MyAxLjgzNDIxOCA1Ljc1Mjc3MyAuNjU1MDc4QzUuNzUyNzczLS4yNjIwMzEgNS4wMTQzMjItLjgwOTkxNCAzLjc5OTQ1MS0uODA5OTE0SDMuMDI1MjY4QzIuMDcyNDI4LS44MDk5MTQgMS44MzQyMTgtLjg5MzI4OCAxLjgzNDIxOC0xLjIyNjc4MkMxLjgzNDIxOC0xLjU4NDA5NyAyLjE2NzcxMi0xLjg0NjEyOCAyLjY0NDEzMi0xLjg0NjEyOEwzLjE4MDEwNC0xLjgzNDIxOEMzLjczOTg5OC0xLjgzNDIxOCA0LjAzNzY2MS0xLjkwNTY4MSA0LjQ0MjYxOC0yLjE0Mzg5MUM0Ljk3ODU5MS0yLjQ1MzU2NCA1LjI1MjUzMi0yLjk0MTg5NCA1LjI1MjUzMi0zLjU3MzE1MUM1LjI1MjUzMi00LjA0OTU3MSA1LjEwOTYwNi00LjQwNjg4NiA0Ljc3NjExMi00Ljc0MDM4SDUuNzQwODYzWk0zLjg1OTAwMyAuNjE5MzQ2QzQuNTAyMTcgLjYxOTM0NiA0LjgxMTg0NCAuODIxODI1IDQuODExODQ0IDEuMjE0ODcxQzQuODExODQ0IDEuNzYyNzU1IDQuMTU2NzY2IDIuMDcyNDI4IDIuOTc3NjI2IDIuMDcyNDI4QzEuOTI5NTAyIDIuMDcyNDI4IDEuMzgxNjE4IDEuNzk4NDg2IDEuMzgxNjE4IDEuMjc0NDI0QzEuMzgxNjE4IDEuMDI0MzAzIDEuNDY0OTkyIC44OTMyODggMS43OTg0ODYgLjYxOTM0NkgzLjg1OTAwM1pNMi44NTg1MjEtNS4yNjQ0NDNDMy40MTgzMTUtNS4yNjQ0NDMgMy42NDQ2MTQtNC44MTE4NDQgMy42NDQ2MTQtMy43MDQxNjdTMy40MTgzMTUtMi4xNjc3MTIgMi44NTg1MjEtMi4xNjc3MTJDMi4yODY4MTctMi4xNjc3MTIgMi4wNzI0MjgtMi41OTY0OSAyLjA3MjQyOC0zLjcwNDE2N0MyLjA3MjQyOC00LjgyMzc1NCAyLjI5ODcyNy01LjI2NDQ0MyAyLjg1ODUyMS01LjI2NDQ0M1onLz4KPHBhdGggaWQ9J2c4LTEwNCcgZD0nTTIuNDc3Mzg1LTguMDUxNTAxSC4xOTA1NjhWLTcuNzY1NjQ4Qy43Mzg0NTEtNy42NTg0NTQgLjgyMTgyNS03LjU2MzE3IC44MjE4MjUtNy4wNzQ4MzlWLTEuMDAwNDgyQy44MjE4MjUtLjUwMDI0MSAuNzI2NTQxLS4zOTMwNDcgLjE5MDU2OC0uMjg1ODUyVjBIMy4wNjA5OTlWLS4yODU4NTJDMi42MjAzMTEtLjM0NTQwNSAyLjQ3NzM4NS0uNTI0MDYyIDIuNDc3Mzg1LS45NjQ3NTFWLTQuMTQ0ODU1QzIuNDc3Mzg1LTQuMTkyNDk3IDIuNTYwNzU4LTQuMzExNjAyIDIuNjc5ODYzLTQuNDE4Nzk3QzIuOTQxODk0LTQuNjkyNzM4IDMuMjI3NzQ3LTQuODM1NjY1IDMuNTAxNjg4LTQuODM1NjY1QzMuOTE4NTU2LTQuODM1NjY1IDQuMTIxMDM0LTQuNTE0MDgxIDQuMTIxMDM0LTMuODQ3MDkzVi0uOTY0NzUxQzQuMTIxMDM0LS41MjQwNjIgMy45NjYxOTgtLjMzMzQ5NCAzLjU2MTI0MS0uMjg1ODUyVjBINi4zNjAyMDlWLS4yODU4NTJDNS45MzE0MzEtLjMyMTU4NCA1Ljc3NjU5NC0uNTAwMjQxIDUuNzc2NTk0LTEuMDAwNDgyVi0zLjk1NDI4N0M1Ljc3NjU5NC00Ljk3ODU5MSA1LjE0NTMzOC01LjYzMzY2OCA0LjE2ODY3Ni01LjYzMzY2OEMzLjUzNzQyLTUuNjMzNjY4IDMuMDk2NzMxLTUuMzk1NDU4IDIuNDc3Mzg1LTQuNzA0NjQ5Vi04LjA1MTUwMVonLz4KPHBhdGggaWQ9J2c4LTEwNScgZD0nTTIuNDc3Mzg1LTUuNDkwNzQySC4xOTA1NjhWLTUuMjA0ODlDLjcxNDYzLTUuMDk3Njk2IC44MjE4MjUtNC45OTA1MDEgLjgyMTgyNS00LjUwMjE3Vi0xLjAwMDQ4MkMuODIxODI1LS41MTIxNTIgLjczODQ1MS0uNDE2ODY4IC4xOTA1NjgtLjI4NTg1MlYwSDMuMDM3MTc4Vi0uMjg1ODUyQzIuNjIwMzExLS4zNDU0MDUgMi40NzczODUtLjUxMjE1MiAyLjQ3NzM4NS0uOTY0NzUxVi01LjQ5MDc0MlpNMS42NDM2NS04LjIzMDE1OEMxLjEzMTQ5OC04LjIzMDE1OCAuNzE0NjMtNy44MTMyOSAuNzE0NjMtNy4zMTMwNDlDLjcxNDYzLTYuNzc3MDc3IDEuMTA3Njc3LTYuMzg0MDMgMS42MzE3MzktNi4zODQwM1MyLjU2MDc1OC02Ljc3NzA3NyAyLjU2MDc1OC03LjMwMTEzOUMyLjU2MDc1OC03LjgxMzI5IDIuMTU1ODAxLTguMjMwMTU4IDEuNjQzNjUtOC4yMzAxNThaJy8+CjxwYXRoIGlkPSdnOC0xMDcnIGQ9J002LjExMDA4OC01LjQ5MDc0MkgzLjU2MTI0MVYtNS4yMTY4MDFDMy42OTIyNTYtNS4xOTI5OCAzLjgxMTM2MS01LjE4MTA2OSAzLjg0NzA5My01LjE2OTE1OUM0LjEzMjk0NS01LjEzMzQyNyA0LjI2Mzk2LTUuMDUwMDU0IDQuMjYzOTYtNC44OTUyMTdDNC4yNjM5Ni00Ljc4ODAyMiA0LjE0NDg1NS00LjU3MzYzMyA0LjAxMzg0LTQuNDQyNjE4TDIuNDg5Mjk1LTIuOTE4MDczVi04LjA1MTUwMUguMjYyMDMxVi03Ljc2NTY0OEMuNjY2OTg4LTcuNzI5OTE3IC44MzM3MzUtNy41Mjc0MzggLjgzMzczNS03LjA3NDgzOVYtMS4wMDA0ODJDLjgzMzczNS0uNTM1OTczIC42NTUwNzgtLjMyMTU4NCAuMjYyMDMxLS4yODU4NTJWMEgzLjEwODY0MVYtLjI4NTg1MkMyLjU0ODg0OC0uMzY5MjI2IDIuNDg5Mjk1LS40NDA2ODkgMi40ODkyOTUtMS4wMDA0ODJWLTIuMzU4MjhMMi43NjMyMzctMi42NDQxMzJMMy44OTQ3MzUtMS4wNDgxMjRDNC4wOTcyMTMtLjc1MDM2MiA0LjE4MDU4Ny0uNjA3NDM2IDQuMTgwNTg3LS41MTIxNTJDNC4xODA1ODctLjM2OTIyNiA0LjAxMzg0LS4yOTc3NjMgMy42ODAzNDYtLjI4NTg1MlYwSDYuNDY3NDA0Vi0uMjg1ODUyQzYuMzM2Mzg4LS4yODU4NTIgNi4yNzY4MzUtLjMyMTU4NCA2LjE2OTY0MS0uNDY0NTFMMy44NTkwMDMtMy42NTY1MjVDNS4wNTAwNTQtNC45MDcxMjggNS4zNTk3MjctNS4xMjE1MTcgNi4xMTAwODgtNS4yMTY4MDFWLTUuNDkwNzQyWicvPgo8cGF0aCBpZD0nZzgtMTA4JyBkPSdNMi40NTM1NjQtOC4wNTE1MDFILjE5MDU2OFYtNy43NjU2NDhDLjYwNzQzNi03LjcyOTkxNyAuNzk4MDA0LTcuNTE1NTI4IC43OTgwMDQtNy4wNzQ4MzlWLTEuMDAwNDgyQy43OTgwMDQtLjU1OTc5NCAuNTk1NTI1LS4zMjE1ODQgLjE5MDU2OC0uMjg1ODUyVjBIMy4wMzcxNzhWLS4yODU4NTJDMi42NDQxMzItLjI5Nzc2MyAyLjQ1MzU2NC0uNTI0MDYyIDIuNDUzNTY0LTEuMDAwNDgyVi04LjA1MTUwMVonLz4KPHBhdGggaWQ9J2c4LTEwOScgZD0nTTIuNDY1NDc0LTUuNDkwNzQySC4xOTA1NjhWLTUuMjA0ODlDLjcxNDYzLTUuMTMzNDI3IC44NDU2NDYtNC45OTA1MDEgLjg0NTY0Ni00LjUwMjE3Vi0xLjAwMDQ4MkMuODQ1NjQ2LS41MTIxNTIgLjcxNDYzLS4zODExMzYgLjE5MDU2OC0uMjg1ODUyVjBIMy4wNDkwODlWLS4yODU4NTJDMi42MzIyMjEtLjM0NTQwNSAyLjUwMTIwNi0uNTEyMTUyIDIuNTAxMjA2LS45NjQ3NTFWLTQuMTQ0ODU1QzIuNTAxMjA2LTQuMjE2MzE4IDIuNjkxNzc0LTQuNDQyNjE4IDIuODQ2NjEtNC41NjE3MjNDMy4wOTY3MzEtNC43NTIyOTEgMy4yOTkyMS00LjgzNTY2NSAzLjUwMTY4OC00LjgzNTY2NUMzLjk2NjE5OC00LjgzNTY2NSA0LjE0NDg1NS00LjU2MTcyMyA0LjE0NDg1NS0zLjg0NzA5M1YtLjk2NDc1MUM0LjE0NDg1NS0uNDc2NDIgNC4wMTM4NC0uMzIxNTg0IDMuNTczMTUxLS4yODU4NTJWMEg2LjM2MDIwOVYtLjI4NTg1MkM1Ljk0MzM0MS0uMzMzNDk0IDUuODAwNDE1LS41MTIxNTIgNS44MDA0MTUtLjk2NDc1MVYtNC4xNDQ4NTVDNS44MDA0MTUtNC4yMDQ0MDggNS45OTA5ODMtNC40MzA3MDcgNi4xNDU4Mi00LjU0OTgxMkM2LjQwNzg1MS00Ljc1MjI5MSA2LjYxMDMzLTQuODM1NjY1IDYuODEyODA4LTQuODM1NjY1QzcuMjY1NDA3LTQuODM1NjY1IDcuNDQ0MDY1LTQuNTQ5ODEyIDcuNDQ0MDY1LTMuODQ3MDkzVi0uOTY0NzUxQzcuNDQ0MDY1LS40NjQ1MSA3LjMxMzA0OS0uMzIxNTg0IDYuODYwNDUtLjI4NTg1MlYwSDkuNjk1MTVWLS4yODU4NTJDOS4yMzA2NC0uMzA5NjczIDkuMDk5NjI1LS40NTI1OTkgOS4wOTk2MjUtLjk2NDc1MVYtMy45NTQyODdDOS4wOTk2MjUtNC45Nzg1OTEgOC40NjgzNjgtNS42MzM2NjggNy40OTE3MDctNS42MzM2NjhDNi44MTI4MDgtNS42MzM2NjggNi4zNjAyMDktNS4zNTk3MjcgNS43NDA4NjMtNC41OTc0NTRDNS4zODM1NDgtNS4zNDc4MTYgNC45NjY2OC01LjYzMzY2OCA0LjIxNjMxOC01LjYzMzY2OFMyLjkxODA3My01LjMxMjA4NSAyLjQ2NTQ3NC00LjU5NzQ1NFYtNS40OTA3NDJaJy8+CjxwYXRoIGlkPSdnOC0xMTAnIGQ9J00yLjUyNTAyNy01LjQ5MDc0MkguMjUwMTIxVi01LjIwNDg5Qy43NzQxODMtNS4xMjE1MTcgLjg4MTM3Ny01LjAwMjQxMiAuODgxMzc3LTQuNTAyMTdWLTEuMDAwNDgyQy44ODEzNzctLjUwMDI0MSAuNzg2MDkzLS4zOTMwNDcgLjI1MDEyMS0uMjg1ODUyVjBIMy4xMjA1NTJWLS4yODU4NTJDMi42Nzk4NjMtLjM0NTQwNSAyLjUzNjkzNy0uNTI0MDYyIDIuNTM2OTM3LS45NjQ3NTFWLTQuMTQ0ODU1QzIuNTM2OTM3LTQuMTkyNDk3IDIuNjIwMzExLTQuMzExNjAyIDIuNzM5NDE2LTQuNDE4Nzk3QzMuMDAxNDQ3LTQuNjkyNzM4IDMuMjg3Mjk5LTQuODM1NjY1IDMuNTYxMjQxLTQuODM1NjY1QzMuOTc4MTA4LTQuODM1NjY1IDQuMTgwNTg3LTQuNTE0MDgxIDQuMTgwNTg3LTMuODQ3MDkzVi0uOTY0NzUxQzQuMTgwNTg3LS41MjQwNjIgNC4wMjU3NS0uMzMzNDk0IDMuNjIwNzkzLS4yODU4NTJWMEg2LjQxOTc2MlYtLjI4NTg1MkM1Ljk1NTI1Mi0uMzIxNTg0IDUuODM2MTQ3LS40NjQ1MSA1LjgzNjE0Ny0uOTY0NzUxVi0zLjk1NDI4N0M1LjgzNjE0Ny00Ljk3ODU5MSA1LjIwNDg5LTUuNjMzNjY4IDQuMjI4MjI5LTUuNjMzNjY4QzMuNTEzNTk5LTUuNjMzNjY4IDIuOTY1NzE1LTUuMzAwMTc0IDIuNTI1MDI3LTQuNTk3NDU0Vi01LjQ5MDc0MlonLz4KPHBhdGggaWQ9J2c4LTExMScgZD0nTTIuOTg5NTM2LTUuNjMzNjY4QzEuNDc2OTAyLTUuNjMzNjY4IC4yOTc3NjMtNC4zODMwNjUgLjI5Nzc2My0yLjc2MzIzN0MuMjk3NzYzLTEuMDYwMDM1IDEuNDI5MjYgLjE2Njc0NyAyLjk4OTUzNiAuMTY2NzQ3QzQuNTI1OTkxIC4xNjY3NDcgNS42Njk0LTEuMDcxOTQ1IDUuNjY5NC0yLjcyNzUwNUM1LjY2OTQtNC4zOTQ5NzYgNC41MjU5OTEtNS42MzM2NjggMi45ODk1MzYtNS42MzM2NjhaTTMuMDAxNDQ3LTUuMjY0NDQzQzMuNjkyMjU2LTUuMjY0NDQzIDMuOTE4NTU2LTQuNjA5MzY1IDMuOTE4NTU2LTIuNjU2MDQyQzMuOTE4NTU2LS44MjE4MjUgMy42ODAzNDYtLjIwMjQ3OSAyLjk4OTUzNi0uMjAyNDc5QzIuMjg2ODE3LS4yMDI0NzkgMi4wNDg2MDctLjgwOTkxNCAyLjA0ODYwNy0yLjU0ODg0OEMyLjA0ODYwNy00LjY0NTA5NiAyLjI2Mjk5Ni01LjI2NDQ0MyAzLjAwMTQ0Ny01LjI2NDQ0M1onLz4KPHBhdGggaWQ9J2c4LTExMicgZD0nTTIuNTI1MDI3LTUuNDkwNzQySC4yNTAxMjFWLTUuMjA0ODlDLjc3NDE4My01LjEyMTUxNyAuODkzMjg4LTUuMDAyNDEyIC44OTMyODgtNC41MDIxN1YxLjQ2NDk5MkMuODkzMjg4IDEuOTUzMzIzIC43OTgwMDQgMi4wNjA1MTcgLjIyNjMgMi4xNTU4MDFWMi40NDE2NTNIMy40Nzc4NjdWMi4xOTE1MzNDMi43NTEzMjYgMi4xNTU4MDEgMi41NDg4NDggMS45MTc1OTEgMi41NDg4NDggMS4xMTk1ODdWLS41NTk3OTRDMy4xMjA1NTIgMCAzLjQzMDIyNSAuMTU0ODM3IDMuOTU0Mjg3IC4xNTQ4MzdDNS4yODgyNjQgLjE1NDgzNyA2LjI0MTEwNC0xLjA4Mzg1NiA2LjI0MTEwNC0yLjg0NjYxQzYuMjQxMTA0LTQuNTAyMTcgNS4zNDc4MTYtNS42MzM2NjggNC4wMjU3NS01LjYzMzY2OEMzLjMyMzAzMS01LjYzMzY2OCAyLjg5NDI1Mi01LjM1OTcyNyAyLjUyNTAyNy00LjY2ODkxN1YtNS40OTA3NDJaTTIuNTQ4ODQ4LTQuMTIxMDM0QzIuNTQ4ODQ4LTQuMjA0NDA4IDIuNjU2MDQyLTQuMzk0OTc2IDIuNzk4OTY4LTQuNTQ5ODEyQzMuMDM3MTc4LTQuODExODQ0IDMuMzExMTItNC45NTQ3NyAzLjU3MzE1MS00Ljk1NDc3QzQuMTkyNDk3LTQuOTU0NzcgNC40NzgzNDktNC4yNDAxMzkgNC40NzgzNDktMi42Nzk4NjNDNC40NzgzNDktMS4yMDI5NjEgNC4xNDQ4NTUtLjUwMDI0MSAzLjQ2NTk1Ny0uNTAwMjQxQzMuMDcyOTEtLjUwMDI0MSAyLjcyNzUwNS0uNzc0MTgzIDIuNTQ4ODQ4LTEuMjI2NzgyVi00LjEyMTAzNFonLz4KPHBhdGggaWQ9J2c4LTExNCcgZD0nTTIuNTk2NDktNS40OTA3NDJILjM0NTQwNVYtNS4yMDQ4OUMuODU3NTU2LTUuMTMzNDI3IC45ODg1NzItNC45Nzg1OTEgLjk4ODU3Mi00LjUwMjE3Vi0xLjAwMDQ4MkMuOTg4NTcyLS41MTIxNTIgLjg2OTQ2Ny0uMzgxMTM2IC4zNDU0MDUtLjI4NTg1MlYwSDMuNTEzNTk5Vi0uMjg1ODUyQzIuNzg3MDU4LS4zMzM0OTQgMi42NDQxMzItLjQ4ODMzMSAyLjY0NDEzMi0xLjIyNjc4MlYtMy40Nzc4NjdDMi42NDQxMzItNC4wOTcyMTMgMi45Nzc2MjYtNC42MDkzNjUgMy4zNzA2NzMtNC42MDkzNjVDMy40NjU5NTctNC42MDkzNjUgMy41NzMxNTEtNC41MjU5OTEgMy43MDQxNjctNC4zMzU0MjNDMy45MzA0NjYtNC4wMTM4NCA0LjEwOTEyNC0zLjkwNjY0NSA0LjQxODc5Ny0zLjkwNjY0NUM0Ljg1OTQ4Ni0zLjkwNjY0NSA1LjE2OTE1OS00LjI0MDEzOSA1LjE2OTE1OS00LjcwNDY0OUM1LjE2OTE1OS01LjI0MDYyMiA0Ljc2NDIwMS01LjYzMzY2OCA0LjIwNDQwOC01LjYzMzY2OEMzLjYwODg4My01LjYzMzY2OCAzLjE1NjI4My01LjMxMjA4NSAyLjU5NjQ5LTQuNTE0MDgxVi01LjQ5MDc0MlonLz4KPHBhdGggaWQ9J2c4LTExNicgZD0nTTMuNjMyNzA0LTUuNDkwNzQySDIuNTEzMTE2Vi03LjUwMzYxN0gyLjIxNTM1NEMxLjQ4ODgxMy02LjQ3OTMxNCAxLjAxMjM5My01Ljk0MzM0MSAuMjM4MjEtNS4yODgyNjRWLTQuOTY2NjhILjg1NzU1NlYtMS4xMDc2NzdDLjg1NzU1Ni0uMzMzNDk0IDEuMzY5NzA4IC4xNDI5MjYgMi4xOTE1MzMgLjE0MjkyNkMyLjk4OTUzNiAuMTQyOTI2IDMuNDY1OTU3LS4yMTQzODkgMy45NTQyODctMS4xOTEwNUwzLjY1NjUyNS0xLjMyMjA2NkMzLjQxODMxNS0uODY5NDY3IDMuMjI3NzQ3LS43MDI3MiAyLjk3NzYyNi0uNzAyNzJDMi42NDQxMzItLjcwMjcyIDIuNTEzMTE2LS45MDUxOTggMi41MTMxMTYtMS4zODE2MThWLTQuOTY2NjhIMy42MzI3MDRWLTUuNDkwNzQyWicvPgo8cGF0aCBpZD0nZzgtMTE3JyBkPSdNNC4wODUzMDMgLjE1NDgzN0M0LjU5NzQ1NC0uMDIzODIxIDQuODgzMzA3LS4wNzE0NjMgNS42NTc0ODktLjE1NDgzN0w2LjM5NTk0MS0uMjM4MjFWLS41MTIxNTJDNS44NzE4NzgtLjUzNTk3MyA1LjcyODk1Mi0uNjkwODA5IDUuNzI4OTUyLTEuMjAyOTYxVi01LjQ5MDc0MkgzLjMzNDk0MVYtNS4yMDQ4OUMzLjkzMDQ2Ni01LjE1NzI0OCA0LjA3MzM5Mi01LjAxNDMyMiA0LjA3MzM5Mi00LjUwMjE3Vi0xLjEzMTQ5OEMzLjY4MDM0Ni0uNzM4NDUxIDMuNDMwMjI1LS42MDc0MzYgMy4wOTY3MzEtLjYwNzQzNkMyLjYwODQtLjYwNzQzNiAyLjQyOTc0My0uODQ1NjQ2IDIuNDI5NzQzLTEuNDUzMDgxVi01LjQ5MDc0MkguMTkwNTY4Vi01LjIwNDg5Qy42Nzg4OTktNS4xMDk2MDYgLjc3NDE4My01LjAwMjQxMiAuNzc0MTgzLTQuNTAyMTdWLTEuNTAwNzIzQy43NzQxODMtLjQ1MjU5OSAxLjM2OTcwOCAuMTY2NzQ3IDIuMzU4MjggLjE2Njc0N0MyLjk3NzYyNiAuMTY2NzQ3IDMuMzk0NDk0LS4wMjM4MjEgNC4wODUzMDMtLjYxOTM0NlYuMTU0ODM3WicvPgo8cGF0aCBpZD0nZzgtMTE4JyBkPSdNNS43NzY1OTQtNS40OTA3NDJIMy45NzgxMDhWLTUuMjA0ODlDNC40OTAyNi01LjE4MTA2OSA0LjYzMzE4Ni01LjA5NzY5NiA0LjYzMzE4Ni00LjgxMTg0NEM0LjYzMzE4Ni00LjY4MDgyOCA0LjU4NTU0NC00LjQ5MDI2IDQuNTAyMTctNC4yNzU4NzFMMy42NDQ2MTQtMi4xMDgxNTlMMi43MDM2ODQtNC41MjU5OTFDMi42MjAzMTEtNC43NTIyOTEgMi41OTY0OS00LjgyMzc1NCAyLjU5NjQ5LTQuODk1MjE3QzIuNTk2NDktNS4wNzM4NzUgMi43MTU1OTUtNS4xNTcyNDggMy4wMTMzNTctNS4xODEwNjlDMy4wMzcxNzgtNS4xODEwNjkgMy4xMzI0NjItNS4xOTI5OCAzLjIyNzc0Ny01LjIwNDg5Vi01LjQ5MDc0MkguMjUwMTIxVi01LjIwNDg5Qy41MjQwNjItNS4xNjkxNTkgLjU5NTUyNS01LjEzMzQyNyAuNjY2OTg4LTUuMDI2MjMzQy42OTA4MDktNS4wMzgxNDMgMS4yNTA2MDMtMy44NDcwOTMgMS40NDExNzEtMy4zNTg3NjJMMi44NzA0MzEgLjE2Njc0N0gzLjE4MDEwNEw1LjA4NTc4NS00LjU0OTgxMkM1LjMxMjA4NS01LjA3Mzg3NSA1LjQwNzM2OS01LjE2OTE1OSA1Ljc3NjU5NC01LjIwNDg5Vi01LjQ5MDc0MlonLz4KPHBhdGggaWQ9J2c4LTExOScgZD0nTTguNDIwNzI2LTUuNDkwNzQySDYuODEyODA4Vi01LjIwNDg5QzcuMjUzNDk3LTUuMTU3MjQ4IDcuMzg0NTEyLTUuMDYxOTY0IDcuMzg0NTEyLTQuNzg4MDIyQzcuMzg0NTEyLTQuNjQ1MDk2IDcuMjI5Njc2LTQuMjA0NDA4IDYuODYwNDUtMy4yNjM0NzhDNi42ODE3OTMtMi43OTg5NjggNi41ODY1MDktMi41NDg4NDggNi40NDM1ODMtMi4xNDM4OTFDNi4zMjQ0NzctMi42MzIyMjEgNi4yODg3NDYtMi43NzUxNDcgNi4wMzg2MjUtMy42NTY1MjVDNS44MDA0MTUtNC40NzgzNDkgNS43MTcwNDItNC44MTE4NDQgNS43MTcwNDItNC45MTkwMzhDNS43MTcwNDItNS4xMDk2MDYgNS44MzYxNDctNS4xNjkxNTkgNi4yODg3NDYtNS4yMDQ4OVYtNS40OTA3NDJIMy41MDE2ODhWLTUuMjA0ODlDMy45NjYxOTgtNS4xNTcyNDggMy45NzgxMDgtNS4xNDUzMzggNC4yMDQ0MDgtNC4zNTkyNDRMNC4yNzU4NzEtNC4xMzI5NDVMMy40NjU5NTctMi4wOTYyNDlMMy4xODAxMDQtMi44NTg1MjFDMy4wNzI5MS0zLjEwODY0MSAyLjk4OTUzNi0zLjMzNDk0MSAyLjkyOTk4NC0zLjUwMTY4OEMyLjU5NjQ5LTQuMzM1NDIzIDIuNDY1NDc0LTQuNzE2NTU5IDIuNDY1NDc0LTQuODcxMzk2QzIuNDY1NDc0LTUuMDYxOTY0IDIuNTg0NTc5LTUuMTU3MjQ4IDIuOTE4MDczLTUuMjA0ODlWLTUuNDkwNzQySC4yNzM5NDJWLTUuMjA0ODlDLjU4MzYxNS01LjE0NTMzOCAuNjMxMjU3LTUuMDczODc1IC45NTI4NC00LjI4Nzc4MUwyLjcxNTU5NSAuMTY2NzQ3SDMuMDAxNDQ3TDQuNDkwMjYtMy41MjU1MDlMNS43MDUxMzEgLjE2Njc0N0g1Ljk3OTA3M0w3LjgyNTIwMS00LjYwOTM2NUM4LjAxNTc2OS01LjA1MDA1NCA4LjExMTA1My01LjE0NTMzOCA4LjQyMDcyNi01LjIwNDg5Vi01LjQ5MDc0MlonLz4KPHBhdGggaWQ9J2c4LTEyMicgZD0nTTUuMDAyNDEyLTEuOTA1NjgxSDQuNjY4OTE3QzQuNTYxNzIzLTEuNTI0NTQ0IDQuNDY2NDM5LTEuMzEwMTU1IDQuMjc1ODcxLTEuMDYwMDM1QzMuODk0NzM1LS41MzU5NzMgMy41MDE2ODgtLjM4MTEzNiAyLjU0ODg0OC0uMzgxMTM2SDIuMjAzNDQzTDQuOTU0NzctNS4xODEwNjlWLTUuNDkwNzQySC41MzU5NzNMLjQ1MjU5OS0zLjc5OTQ1MUguNzYyMjcyQzEuMDYwMDM1LTQuOTMwOTQ5IDEuMzY5NzA4LTUuMTIxNTE3IDMuMDM3MTc4LTUuMTA5NjA2TC4yNTAxMjEtLjI5Nzc2M1YwSDQuODExODQ0TDUuMDAyNDEyLTEuOTA1NjgxWicvPgo8cGF0aCBpZD0nZzQ1LTQzJyBkPSdNMi40NDQ4MzItMS4zNzQ4NDRINC4xMTI1NzhDNC4xOTYyNjQtMS4zNzQ4NDQgNC4zMDk4MzgtMS4zNzQ4NDQgNC4zMDk4MzgtMS40OTQzOTZTNC4xOTYyNjQtMS42MTM5NDggNC4xMTI1NzgtMS42MTM5NDhIMi40NDQ4MzJWLTMuMjg3NjcxQzIuNDQ0ODMyLTMuMzcxMzU3IDIuNDQ0ODMyLTMuNDg0OTMyIDIuMzI1MjgtMy40ODQ5MzJTMi4yMDU3MjktMy4zNzEzNTcgMi4yMDU3MjktMy4yODc2NzFWLTEuNjEzOTQ4SC41MzIwMDVDLjQ0ODMxOS0xLjYxMzk0OCAuMzM0NzQ1LTEuNjEzOTQ4IC4zMzQ3NDUtMS40OTQzOTZTLjQ0ODMxOS0xLjM3NDg0NCAuNTMyMDA1LTEuMzc0ODQ0SDIuMjA1NzI5Vi4yOTg4NzlDMi4yMDU3MjkgLjM4MjU2NSAyLjIwNTcyOSAuNDk2MTM5IDIuMzI1MjggLjQ5NjEzOVMyLjQ0NDgzMiAuMzgyNTY1IDIuNDQ0ODMyIC4yOTg4NzlWLTEuMzc0ODQ0WicvPgo8cGF0aCBpZD0nZzQ1LTQ4JyBkPSdNMi43NDk2ODktMS45MTI4MjdDMi43NDk2ODktMi4zOTEwMzQgMi43MTk4MDEtMi44NjkyNCAyLjUxMDU4NS0zLjMxMTU4MkMyLjIzNTYxNi0zLjg4NTQzIDEuNzQ1NDU1LTMuOTgxMDcxIDEuNDk0Mzk2LTMuOTgxMDcxQzEuMTM1NzQxLTMuOTgxMDcxIC42OTkzNzctMy44MjU2NTQgLjQ1NDI5Ni0zLjI2OTczOEMuMjYzMDE0LTIuODU3Mjg1IC4yMzMxMjYtMi4zOTEwMzQgLjIzMzEyNi0xLjkxMjgyN0MuMjMzMTI2LTEuNDY0NTA4IC4yNTcwMzYtLjkyNjUyNiAuNTAyMTE3LS40NzIyMjlDLjc1OTE1MyAuMDExOTU1IDEuMTk1NTE3IC4xMzE1MDcgMS40ODg0MTggLjEzMTUwN0MxLjgxMTIwOCAuMTMxNTA3IDIuMjY1NTA0IC4wMDU5NzggMi41Mjg1MTgtLjU2MTg5M0MyLjcxOTgwMS0uOTc0MzQ2IDIuNzQ5Njg5LTEuNDQwNTk4IDIuNzQ5Njg5LTEuOTEyODI3Wk0xLjQ4ODQxOCAwQzEuMjU1MjkzIDAgLjkwMjYxNS0uMTQ5NDQgLjc5NTAxOS0uNzIzMjg4Qy43MjkyNjUtMS4wODE5NDMgLjcyOTI2NS0xLjYzMTg4IC43MjkyNjUtMS45ODQ1NThDLjcyOTI2NS0yLjM2NzEyMyAuNzI5MjY1LTIuNzYxNjQ0IC43NzcwODYtMy4wODQ0MzNDLjg5MDY2LTMuNzk1NzY2IDEuMzM4OTc5LTMuODQ5NTY0IDEuNDg4NDE4LTMuODQ5NTY0QzEuNjg1Njc5LTMuODQ5NTY0IDIuMDgwMTk5LTMuNzQxOTY4IDIuMTkzNzczLTMuMTUwMTg3QzIuMjUzNTQ5LTIuODE1NDQyIDIuMjUzNTQ5LTIuMzYxMTQ2IDIuMjUzNTQ5LTEuOTg0NTU4QzIuMjUzNTQ5LTEuNTM2MjM5IDIuMjUzNTQ5LTEuMTI5NzYzIDIuMTg3Nzk2LS43NDcxOThDMi4wOTgxMzItLjE3OTMyOCAxLjc1NzQxIDAgMS40ODg0MTggMFonLz4KPHBhdGggaWQ9J2c0NS00OScgZD0nTTEuNzU3NDEtMy44MjU2NTRDMS43NTc0MS0zLjk2OTExNiAxLjc1NzQxLTMuOTgxMDcxIDEuNjE5OTI1LTMuOTgxMDcxQzEuMjQ5MzE1LTMuNTk4NTA2IC43MjMyODgtMy41OTg1MDYgLjUzMjAwNS0zLjU5ODUwNlYtMy40MTMyQy42NTE1NTctMy40MTMyIDEuMDA0MjM0LTMuNDEzMiAxLjMxNTA2OC0zLjU2ODYxOFYtLjQ3MjIyOUMxLjMxNTA2OC0uMjU3MDM2IDEuMjk3MTM2LS4xODUzMDUgLjc1OTE1My0uMTg1MzA1SC41Njc4N1YwQy43NzcwODYtLjAxNzkzMyAxLjI5NzEzNi0uMDE3OTMzIDEuNTM2MjM5LS4wMTc5MzNTMi4yOTUzOTItLjAxNzkzMyAyLjUwNDYwOCAwVi0uMTg1MzA1SDIuMzEzMzI1QzEuNzc1MzQyLS4xODUzMDUgMS43NTc0MS0uMjUxMDU5IDEuNzU3NDEtLjQ3MjIyOVYtMy44MjU2NTRaJy8+CjxwYXRoIGlkPSdnNDUtNTAnIGQ9J00uNzU5MTUzLS40NjAyNzRMMS4zOTI3NzctMS4wNzU5NjVDMi4zMjUyOC0xLjkwMDg3MiAyLjY4MzkzNS0yLjIyMzY2MSAyLjY4MzkzNS0yLjgyMTQyQzIuNjgzOTM1LTMuNTAyODY0IDIuMTQ1OTUzLTMuOTgxMDcxIDEuNDE2Njg3LTMuOTgxMDcxQy43NDEyMi0zLjk4MTA3MSAuMjk4ODc5LTMuNDMxMTMzIC4yOTg4NzktMi44OTkxMjhDLjI5ODg3OS0yLjU2NDM4NCAuNTk3NzU4LTIuNTY0Mzg0IC42MTU2OTEtMi41NjQzODRDLjcxNzMxLTIuNTY0Mzg0IC45MjY1MjYtMi42MzYxMTUgLjkyNjUyNi0yLjg4MTE5NkMuOTI2NTI2LTMuMDM2NjEzIC44MTg5MjktMy4xOTIwMyAuNjA5NzE0LTMuMTkyMDNDLjU2MTg5My0zLjE5MjAzIC41NDk5MzgtMy4xOTIwMyAuNTMyMDA1LTMuMTg2MDUyQy42Njk0ODktMy41NzQ1OTUgLjk5MjI3OS0zLjc5NTc2NiAxLjMzODk3OS0zLjc5NTc2NkMxLjg4MjkzOS0zLjc5NTc2NiAyLjEzOTk3NS0zLjMxMTU4MiAyLjEzOTk3NS0yLjgyMTQyQzIuMTM5OTc1LTIuMzQzMjEzIDEuODQxMDk2LTEuODcwOTg0IDEuNTEyMzI5LTEuNTAwMzc0TC4zNjQ2MzMtLjIyMTE3MUMuMjk4ODc5LS4xNTU0MTcgLjI5ODg3OS0uMTQzNDYyIC4yOTg4NzkgMEgyLjUxNjU2M0wyLjY4MzkzNS0xLjA0MDFIMi41MzQ0OTZDMi41MDQ2MDgtLjg2MDc3MiAyLjQ2Mjc2NS0uNTk3NzU4IDIuNDAyOTg5LS41MDgwOTVDMi4zNjExNDYtLjQ2MDI3NCAxLjk2NjYyNS0uNDYwMjc0IDEuODM1MTE4LS40NjAyNzRILjc1OTE1M1onLz4KPHBhdGggaWQ9J2c0NS01MScgZD0nTTEuNzMzNDk5LTIuMTA0MTFDMi4yMjM2NjEtMi4yNjU1MDQgMi41NzAzNjEtMi42ODM5MzUgMi41NzAzNjEtMy4xNTYxNjRDMi41NzAzNjEtMy42NDYzMjYgMi4wNDQzMzQtMy45ODEwNzEgMS40NzA0ODYtMy45ODEwNzFDLjg2Njc1LTMuOTgxMDcxIC40MTI0NTMtMy42MjI0MTYgLjQxMjQ1My0zLjE2ODEyQy40MTI0NTMtMi45NzA4NTkgLjU0Mzk2LTIuODU3Mjg1IC43MTczMS0yLjg1NzI4NUMuOTAyNjE1LTIuODU3Mjg1IDEuMDIyMTY3LTIuOTg4NzkyIDEuMDIyMTY3LTMuMTYyMTQyQzEuMDIyMTY3LTMuNDYxMDIxIC43NDEyMi0zLjQ2MTAyMSAuNjUxNTU3LTMuNDYxMDIxQy44MzY4NjItMy43NTM5MjMgMS4yMzEzODItMy44MzE2MzEgMS40NDY1NzUtMy44MzE2MzFDMS42OTE2NTYtMy44MzE2MzEgMi4wMjA0MjMtMy43MDAxMjUgMi4wMjA0MjMtMy4xNjIxNDJDMi4wMjA0MjMtMy4wOTA0MTEgMi4wMDg0NjgtMi43NDM3MTEgMS44NTMwNTEtMi40ODA2OTdDMS42NzM3MjQtMi4xOTM3NzMgMS40NzA0ODYtMi4xNzU4NDEgMS4zMjEwNDYtMi4xNjk4NjNDMS4yNzMyMjUtMi4xNjM4ODUgMS4xMjk3NjMtMi4xNTE5MyAxLjA4NzkyLTIuMTUxOTNDMS4wNDAxLTIuMTQ1OTUzIC45OTgyNTctMi4xMzk5NzUgLjk5ODI1Ny0yLjA4MDE5OUMuOTk4MjU3LTIuMDE0NDQ2IDEuMDQwMS0yLjAxNDQ0NiAxLjE0MTcxOS0yLjAxNDQ0NkgxLjQwNDczMkMxLjg5NDg5NC0yLjAxNDQ0NiAyLjExNjA2NS0xLjYwNzk3IDIuMTE2MDY1LTEuMDIyMTY3QzIuMTE2MDY1LS4yMDkyMTUgMS43MDM2MTEtLjAzNTg2NiAxLjQ0MDU5OC0uMDM1ODY2QzEuMTgzNTYyLS4wMzU4NjYgLjczNTI0My0uMTM3NDg0IC41MjYwMjctLjQ5MDE2MkMuNzM1MjQzLS40NjAyNzQgLjkyMDU0OC0uNTkxNzgxIC45MjA1NDgtLjgxODkyOUMuOTIwNTQ4LTEuMDM0MTIyIC43NTkxNTMtMS4xNTM2NzQgLjU4NTgwMy0xLjE1MzY3NEMuNDQyMzQxLTEuMTUzNjc0IC4yNTEwNTktMS4wNjk5ODggLjI1MTA1OS0uODA2OTc0Qy4yNTEwNTktLjI2MzAxNCAuODA2OTc0IC4xMzE1MDcgMS40NTg1MzEgLjEzMTUwN0MyLjE4Nzc5NiAuMTMxNTA3IDIuNzMxNzU2LS40MTI0NTMgMi43MzE3NTYtMS4wMjIxNjdDMi43MzE3NTYtMS41MTIzMjkgMi4zNTUxNjgtMS45Nzg1OCAxLjczMzQ5OS0yLjEwNDExWicvPgo8cGF0aCBpZD0nZzQzLTExMCcgZD0nTTEuNTk0MDIyLTEuMzA3MDk4QzEuNjE3OTMzLTEuNDI2NjUgMS42OTc2MzQtMS43Mjk1MTQgMS43MjE1NDQtMS44NDkwNjZDMS44MzMxMjYtMi4yNzk0NTIgMS44MzMxMjYtMi4yODc0MjIgMi4wMTY0MzgtMi41NTA0MzZDMi4yNzk0NTItMi45NDA5NzEgMi42NTQwNDctMy4yOTE2NTYgMy4xODgwNDUtMy4yOTE2NTZDMy40NzQ5NjktMy4yOTE2NTYgMy42NDIzNDEtMy4xMjQyODQgMy42NDIzNDEtMi43NDk2ODlDMy42NDIzNDEtMi4zMTEzMzMgMy4zMDc1OTctMS40MDI3NCAzLjE1NjE2NC0xLjAxMjIwNEMzLjA1MjU1My0uNzQ5MTkxIDMuMDUyNTUzLS43MDEzNyAzLjA1MjU1My0uNTk3NzU4QzMuMDUyNTUzLS4xNDM0NjIgMy40MjcxNDggLjA3OTcwMSAzLjc2OTg2MyAuMDc5NzAxQzQuNTUwOTM0IC4wNzk3MDEgNC44Nzc3MDktMS4wMzYxMTUgNC44Nzc3MDktMS4xMzk3MjZDNC44Nzc3MDktMS4yMTk0MjcgNC44MTM5NDgtMS4yNDMzMzcgNC43NTgxNTctMS4yNDMzMzdDNC42NjI1MTYtMS4yNDMzMzcgNC42NDY1NzUtMS4xODc1NDcgNC42MjI2NjUtMS4xMDc4NDZDNC40MzEzODItLjQ1NDI5NiA0LjA5NjYzOC0uMTQzNDYyIDMuNzkzNzczLS4xNDM0NjJDMy42NjYyNTItLjE0MzQ2MiAzLjYwMjQ5MS0uMjIzMTYzIDMuNjAyNDkxLS40MDY0NzZTMy42NjYyNTItLjc2NTEzMSAzLjc0NTk1My0uOTY0Mzg0QzMuODY1NTA0LTEuMjY3MjQ4IDQuMjE2MTg5LTIuMTgzODExIDQuMjE2MTg5LTIuNjMwMTM3QzQuMjE2MTg5LTMuMjI3ODk1IDMuODAxNzQzLTMuNTE0ODE5IDMuMjI3ODk1LTMuNTE0ODE5QzIuNTgyMzE2LTMuNTE0ODE5IDIuMTY3ODctMy4xMjQyODQgMS45MzY3MzctMi44MjE0MkMxLjg4MDk0Ni0zLjI1OTc3NiAxLjUzMDI2Mi0zLjUxNDgxOSAxLjEyMzc4Ni0zLjUxNDgxOUMuODM2ODYyLTMuNTE0ODE5IC42Mzc2MDktMy4zMzE1MDcgLjUxMDA4Ny0zLjA4NDQzM0MuMzE4ODA0LTIuNzA5ODM4IC4yMzkxMDMtMi4zMTEzMzMgLjIzOTEwMy0yLjI5NTM5MkMuMjM5MTAzLTIuMjIzNjYxIC4yOTQ4OTQtMi4xOTE3ODEgLjM1ODY1NS0yLjE5MTc4MUMuNDYyMjY3LTIuMTkxNzgxIC40NzAyMzctMi4yMjM2NjEgLjUyNjAyNy0yLjQzMDg4NEMuNjIxNjY5LTIuODIxNDIgLjc2NTEzMS0zLjI5MTY1NiAxLjA5OTg3NS0zLjI5MTY1NkMxLjMwNzA5OC0zLjI5MTY1NiAxLjM1NDkxOS0zLjA5MjQwMyAxLjM1NDkxOS0yLjkxNzA2MUMxLjM1NDkxOS0yLjc3MzU5OSAxLjMxNTA2OC0yLjYyMjE2NyAxLjI1MTMwOC0yLjM1OTE1M0MxLjIzNTM2Ny0yLjI5NTM5MiAxLjExNTgxNi0xLjgyNTE1NiAxLjA4MzkzNS0xLjcxMzU3NEwuNzg5MDQxLS41MTgwNTdDLjc1NzE2MS0uMzk4NTA2IC43MDkzNC0uMTk5MjUzIC43MDkzNC0uMTY3MzcyQy43MDkzNCAuMDE1OTQgLjg2MDc3MiAuMDc5NzAxIC45NjQzODQgLjA3OTcwMUMxLjEwNzg0NiAuMDc5NzAxIDEuMjI3Mzk3LS4wMTU5NCAxLjI4MzE4OC0uMTExNTgyQzEuMzA3MDk4LS4xNTk0MDIgMS4zNzA4NTktLjQzMDM4NiAxLjQxMDcxLS41OTc3NThMMS41OTQwMjItMS4zMDcwOThaJy8+CjxwYXRoIGlkPSdnMS0yJyBkPSdNLjI2OTUzNS0zLjYyNTY3NkguODYwNzcyVi0uODE3Mjk5Qy44NjA3NzItLjI2MDg0IC43NjUxMzEtLjE0NzgwOSAuMjc4MjI5LS4xMzA0MlYwSDIuMTkxMDU2Vi0uMTMwNDJDMS43MDQxNTUtLjE2NTE5OSAxLjU5MTEyNC0uMjg2OTI0IDEuNTkxMTI0LS43NjUxMzFWLTMuNjI1Njc2SDIuMzM4ODY2QzMuMTczNTU0LTMuNjI1Njc2IDMuMjE3MDI3LTMuNTk5NTkyIDMuMjE3MDI3LTMuMTM4Nzc1Vi0uODQzMzgzQzMuMjE3MDI3LS4yNTIxNDUgMy4xNTYxNjQtLjE3Mzg5MyAyLjYxNzA5NS0uMTMwNDJWMEg0LjUyOTkyMlYtLjEzMDQyQzQuMDQzMDItLjE3Mzg5MyAzLjk0NzM3OS0uMjg2OTI0IDMuOTQ3Mzc5LS44NDMzODNWLTMuMTIxMzg2QzMuOTQ3Mzc5LTMuMzEyNjY4IDMuOTQ3Mzc5LTMuNTEyNjQ2IDMuOTY0NzY4LTMuOTczNDYzTDMuOTI5OTktMy45OTk1NDdDMy41NDc0MjQtMy45Mzg2ODQgMy4yOTUyNzktMy45MTI2IDIuOTQ3NDkyLTMuOTEyNkgxLjU4MjQyOVYtNC4yODY0NzFDMS41ODI0MjktNC42NjkwMzYgMS42MDg1MTMtNC45Mzg1NzEgMS42NTE5ODctNS4wODYzOEMxLjc3MzcxMi01LjQ2MDI1MSAyLjExMjgwNC01LjcyMTA5MSAyLjUwNDA2NC01LjcyMTA5MUMyLjc0NzUxNS01LjcyMTA5MSAyLjkxMjcxNC01LjYwODA2IDMuMTIxMzg2LTUuMzEyNDQyQzMuMjg2NTg0LTUuMDc3Njg2IDMuMzk5NjE1LTQuOTkwNzM5IDMuNTQ3NDI0LTQuOTkwNzM5QzMuNzMwMDEyLTQuOTkwNzM5IDMuODYwNDMyLTUuMTM4NTQ4IDMuODYwNDMyLTUuMzI5ODMxQzMuODYwNDMyLTUuNjk1MDA3IDMuNDI1Njk5LTUuOTM4NDU4IDIuNzU2MjEtNS45Mzg0NThDMi4wOTU0MTUtNS45Mzg0NTggMS41OTExMjQtNS43MTIzOTYgMS4yNzgxMTYtNS4yODYzNThDMS4wMTcyNzYtNC45Mjk4NzYgLjkyMTYzNS00LjYwODE3NCAuODY5NDY3LTMuOTEyNkguMjY5NTM1Vi0zLjYyNTY3NlonLz4KPHBhdGggaWQ9J2cxLTQwJyBkPSdNMi41NjQ5MjctNS44Nzc1OTVDMS45MjE1MjEtNS40NjAyNTEgMS42NjA2ODEtNS4yMzQxOSAxLjMzODk3OS00LjgzNDIzNUMuNzIxNjU3LTQuMDc3Nzk5IC40MTczNDQtMy4yMDgzMzIgLjQxNzM0NC0yLjE5MTA1NkMuNDE3MzQ0LTEuMDg2ODMzIC43MzkwNDctLjIzNDc1NiAxLjUwNDE3NyAuNjUyMUMxLjg2MDY1OSAxLjA2OTQ0NCAyLjA4NjcyIDEuMjYwNzI3IDIuNTM4ODQzIDEuNTM4OTU2TDIuNjQzMTc5IDEuMzk5ODQxQzEuOTQ3NjA1IC44NTIwNzcgMS43MDQxNTUgLjU0Nzc2NCAxLjQ2OTM5OS0uMTA0MzM2QzEuMjYwNzI3LS42ODY4NzkgMS4xNjUwODUtMS4zNDc2NzMgMS4xNjUwODUtMi4yMTcxNEMxLjE2NTA4NS0zLjEzMDA4IDEuMjc4MTE2LTMuODQzMDQzIDEuNTEyODcyLTQuMzgyMTEyQzEuNzU2MzIzLTQuOTIxMTgyIDIuMDE3MTYzLTUuMjM0MTkgMi42NDMxNzktNS43Mzg0OEwyLjU2NDkyNy01Ljg3NzU5NVonLz4KPHBhdGggaWQ9J2cxLTQxJyBkPSdNLjMzMDM5NyAxLjUzODk1NkMuOTczODAzIDEuMTIxNjEyIDEuMjM0NjQzIC44OTU1NTEgMS41NTYzNDUgLjQ5NTU5NkMyLjE3MzY2Ny0uMjYwODQgMi40Nzc5OC0xLjEzMDMwNyAyLjQ3Nzk4LTIuMTQ3NTgzQzIuNDc3OTgtMy4yNjA1IDIuMTU2Mjc4LTQuMTAzODgzIDEuMzkxMTQ3LTQuOTkwNzM5QzEuMDM0NjY1LTUuNDA4MDgzIC44MDg2MDQtNS41OTkzNjYgLjM1NjQ4MS01Ljg3NzU5NUwuMjUyMTQ1LTUuNzM4NDhDLjk0NzcxOS01LjE5MDcxNiAxLjE4MjQ3NS00Ljg4NjQwMyAxLjQyNTkyNS00LjIzNDMwM0MxLjYzNDU5Ny0zLjY1MTc2IDEuNzMwMjM5LTIuOTkwOTY2IDEuNzMwMjM5LTIuMTIxNDk5QzEuNzMwMjM5LTEuMjE3MjUzIDEuNjE3MjA4LS40OTU1OTYgMS4zODI0NTIgLjAzNDc3OUMxLjEzOTAwMSAuNTgyNTQzIC44NzgxNjEgLjg5NTU1MSAuMjUyMTQ1IDEuMzk5ODQxTC4zMzAzOTcgMS41Mzg5NTZaJy8+CjxwYXRoIGlkPSdnMS00NCcgZD0nTS43MjE2NTcgMS4yMjU5NDhDMS4zMDQyIC45MzkwMjQgMS42OTU0NiAuNDA4NjQ5IDEuNjk1NDYtLjExMzAzMUMxLjY5NTQ2LS41NDc3NjQgMS4zOTExNDctLjg4Njg1NiAuOTk5ODg3LS44ODY4NTZDLjY5NTU3My0uODg2ODU2IC40ODY5MDEtLjY4Njg3OSAuNDg2OTAxLS4zOTEyNkMuNDg2OTAxLS4xMTMwMzEgLjY4Njg3OSAuMDUyMTY4IC45OTk4ODcgLjA1MjE2OEMxLjA1MjA1NSAuMDUyMTY4IDEuMTEyOTE3IC4wNDM0NzMgMS4xNjUwODUgLjAzNDc3OUMxLjIyNTk0OCAuMDE3Mzg5IDEuMjI1OTQ4IC4wMTczODkgMS4yMzQ2NDMgLjAxNzM4OUMxLjMwNDIgLjAxNzM4OSAxLjM1NjM2OCAuMDY5NTU3IDEuMzU2MzY4IC4xMzkxMTVDMS4zNTYzNjggLjQxNzM0NCAxLjExMjkxNyAuNzM5MDQ3IC42NDM0MDUgMS4wNjA3NDlMLjcyMTY1NyAxLjIyNTk0OFonLz4KPHBhdGggaWQ9J2cxLTQ2JyBkPSdNMS4wODY4MzMtLjg2OTQ2N0MuODI1OTkzLS44Njk0NjcgLjYwODYyNy0uNjQzNDA1IC42MDg2MjctLjM3Mzg3MUMuNjA4NjI3LS4xMjE3MjUgLjgyNTk5MyAuMDk1NjQxIDEuMDc4MTM5IC4wOTU2NDFDMS4zNDc2NzMgLjA5NTY0MSAxLjU3MzczNS0uMTIxNzI1IDEuNTczNzM1LS4zNzM4NzFDMS41NzM3MzUtLjY0MzQwNSAxLjM0NzY3My0uODY5NDY3IDEuMDg2ODMzLS44Njk0NjdaJy8+CjxwYXRoIGlkPSdnMS00NycgZD0nTTIuNDk1MzctNS44Nzc1OTVIMS45MTI4MjdMLS4wNzgyNTIgLjEyMTcyNUguNTEyOTg1TDIuNDk1MzctNS44Nzc1OTVaJy8+CjxwYXRoIGlkPSdnMS00OCcgZD0nTTIuMjA4NDQ2LTUuODc3NTk1QzEuNzMwMjM5LTUuODc3NTk1IDEuMzY1MDYzLTUuNzI5Nzg2IDEuMDQzMzYtNS40MjU0NzJDLjUzOTA2OS00LjkzODU3MSAuMjA4NjcyLTMuOTM4Njg0IC4yMDg2NzItMi45MjE0MDhDLjIwODY3Mi0xLjk3MzY4OSAuNDk1NTk2LS45NTY0MTMgLjkwNDI0NS0uNDY5NTEyQzEuMjI1OTQ4LS4wODY5NDcgMS42NjkzNzYgLjEyMTcyNSAyLjE3MzY2NyAuMTIxNzI1QzIuNjE3MDk1IC4xMjE3MjUgMi45OTA5NjYtLjAyNjA4NCAzLjMwMzk3NC0uMzMwMzk3QzMuODA4MjY0LS44MDg2MDQgNC4xMzg2NjItMS44MTcxODUgNC4xMzg2NjItMi44NjkyNEM0LjEzODY2Mi00LjY1MTY0NyAzLjM0NzQ0Ny01Ljg3NzU5NSAyLjIwODQ0Ni01Ljg3NzU5NVpNMi4xODIzNjItNS42NTE1MzRDMi45MTI3MTQtNS42NTE1MzQgMy4zMDM5NzQtNC42NjkwMzYgMy4zMDM5NzQtMi44NTE4NTFTMi45MjE0MDgtLjEwNDMzNiAyLjE3MzY2Ny0uMTA0MzM2UzEuMDQzMzYtMS4wMzQ2NjUgMS4wNDMzNi0yLjg0MzE1NkMxLjA0MzM2LTQuNjg2NDI2IDEuNDM0NjItNS42NTE1MzQgMi4xODIzNjItNS42NTE1MzRaJy8+CjxwYXRoIGlkPSdnMS00OScgZD0nTTIuNTMwMTQ4LTUuODc3NTk1TC45NjUxMDgtNS4wODYzOFYtNC45NjQ2NTVDMS4wNjk0NDQtNS4wMDgxMjggMS4xNjUwODUtNS4wNDI5MDcgMS4xOTk4NjQtNS4wNjAyOTZDMS4zNTYzNjgtNS4xMjExNTkgMS41MDQxNzctNS4xNTU5MzggMS41OTExMjQtNS4xNTU5MzhDMS43NzM3MTItNS4xNTU5MzggMS44NTE5NjQtNS4wMjU1MTggMS44NTE5NjQtNC43NDcyODhWLS44MDg2MDRDMS44NTE5NjQtLjUyMTY4IDEuNzgyNDA3LS4zMjE3MDMgMS42NDMyOTItLjI0MzQ1MUMxLjUxMjg3Mi0uMTY1MTk5IDEuMzkxMTQ3LS4xMzkxMTUgMS4wMjU5NzEtLjEzMDQyVjBIMy40MjU2OTlWLS4xMzA0MkMyLjczODgyLS4xMzkxMTUgMi41OTk3MDYtLjIyNjA2MSAyLjU5OTcwNi0uNjQzNDA1Vi01Ljg2MDIwNkwyLjUzMDE0OC01Ljg3NzU5NVonLz4KPHBhdGggaWQ9J2cxLTUwJyBkPSdNNC4xMjk5NjctMS4xOTExNjlMNC4wMTY5MzYtMS4yMzQ2NDNDMy42OTUyMzQtLjczOTA0NyAzLjU4MjIwMy0uNjYwNzk1IDMuMTkwOTQzLS42NjA3OTVIMS4xMTI5MTdMMi41NzM2MjItMi4xOTEwNTZDMy4zNDc0NDctMi45OTk2NiAzLjY4NjUzOS0zLjY2MDQ1NSAzLjY4NjUzOS00LjMzODYzOUMzLjY4NjUzOS01LjIwODEwNiAyLjk4MjI3MS01Ljg3NzU5NSAyLjA3ODAyNi01Ljg3NzU5NUMxLjU5OTgxOS01Ljg3NzU5NSAxLjE0NzY5Ni01LjY4NjMxMiAuODI1OTkzLTUuMzM4NTI2Qy41NDc3NjQtNS4wNDI5MDcgLjQxNzM0NC00Ljc2NDY3OCAuMjY5NTM1LTQuMTQ3MzU2TC40NTIxMjMtNC4xMDM4ODNDLjc5OTkwOS00Ljk1NTk2IDEuMTEyOTE3LTUuMjM0MTkgMS43MTI4NDktNS4yMzQxOUMyLjQ0MzIwMi01LjIzNDE5IDIuOTM4Nzk4LTQuNzM4NTk0IDIuOTM4Nzk4LTQuMDA4MjQyQzIuOTM4Nzk4LTMuMzMwMDU4IDIuNTM4ODQzLTIuNTIxNDU0IDEuODA4NDkxLTEuNzQ3NjI4TC4yNjA4NC0uMTA0MzM2VjBIMy42NTE3Nkw0LjEyOTk2Ny0xLjE5MTE2OVonLz4KPHBhdGggaWQ9J2cxLTUxJyBkPSdNMS4zMzAyODQtMi44NjkyNEMxLjg0MzI2OS0yLjg2OTI0IDIuMDQzMjQ3LTIuODUxODUxIDIuMjUxOTE5LTIuNzczNTk5QzIuNzkwOTg4LTIuNTgyMzE2IDMuMTMwMDgtMi4wODY3MiAzLjEzMDA4LTEuNDg2Nzg4QzMuMTMwMDgtLjc1NjQzNiAyLjYzNDQ4NC0uMTkxMjgzIDEuOTkxMDc5LS4xOTEyODNDMS43NTYzMjMtLjE5MTI4MyAxLjU4MjQyOS0uMjUyMTQ1IDEuMjYwNzI3LS40NjA4MTdDLjk5OTg4Ny0uNjE3MzIxIC44NTIwNzctLjY3ODE4NCAuNzA0MjY4LS42NzgxODRDLjUwNDI5MS0uNjc4MTg0IC4zNzM4NzEtLjU1NjQ1OSAuMzczODcxLS4zNzM4NzFDLjM3Mzg3MS0uMDY5NTU3IC43NDc3NDEgLjEyMTcyNSAxLjM1NjM2OCAuMTIxNzI1QzIuMDI1ODU3IC4xMjE3MjUgMi43MTI3MzYtLjEwNDMzNiAzLjEyMTM4Ni0uNDYwODE3UzMuNzU2MDk2LTEuMzIxNTg5IDMuNzU2MDk2LTEuOTA0MTMyQzMuNzU2MDk2LTIuMzQ3NTYgMy42MTY5ODItMi43NTYyMSAzLjM2NDgzNi0zLjAyNTc0NEMzLjE5MDk0My0zLjIxNzAyNyAzLjAyNTc0NC0zLjMyMTM2MyAyLjY0MzE3OS0zLjQ4NjU2MkMzLjI0MzExMS0zLjg5NTIxMSAzLjQ2MDQ3OC00LjIxNjkxNCAzLjQ2MDQ3OC00LjY4NjQyNkMzLjQ2MDQ3OC01LjM5MDY5NCAyLjkwNDAxOS01Ljg3NzU5NSAyLjEwNDExLTUuODc3NTk1QzEuNjY5Mzc2LTUuODc3NTk1IDEuMjg2ODExLTUuNzI5Nzg2IC45NzM4MDMtNS40NTE1NTZDLjcxMjk2My01LjIxNjggLjU4MjU0My00Ljk5MDczOSAuMzkxMjYtNC40NjkwNTlMLjUyMTY4LTQuNDM0MjhDLjg3ODE2MS01LjA2ODk5MSAxLjI2OTQyMS01LjM1NTkxNSAxLjgxNzE4NS01LjM1NTkxNUMyLjM4MjMzOS01LjM1NTkxNSAyLjc3MzU5OS00Ljk3MzM1IDIuNzczNTk5LTQuNDI1NTg2QzIuNzczNTk5LTQuMTEyNTc4IDIuNjQzMTc5LTMuNzk5NTcgMi40MjU4MTItMy41ODIyMDNDMi4xNjQ5NzItMy4zMjEzNjMgMS45MjE1MjEtMy4xOTA5NDMgMS4zMzAyODQtMi45ODIyNzFWLTIuODY5MjRaJy8+CjxwYXRoIGlkPSdnMS01MicgZD0nTTQuMTAzODgzLTIuMDA4NDY4SDMuMjE3MDI3Vi01Ljg3NzU5NUgyLjgzNDQ2MkwuMTA0MzM2LTIuMDA4NDY4Vi0xLjQ1MjAwOUgyLjU0NzUzOFYwSDMuMjE3MDI3Vi0xLjQ1MjAwOUg0LjEwMzg4M1YtMi4wMDg0NjhaTTIuNTM4ODQzLTIuMDA4NDY4SC40NTIxMjNMMi41Mzg4NDMtNC45OTA3MzlWLTIuMDA4NDY4WicvPgo8cGF0aCBpZD0nZzEtNTMnIGQ9J00xLjU3MzczNS01LjA2ODk5MUgzLjI3Nzg5QzMuNDE3MDA0LTUuMDY4OTkxIDMuNDUxNzgzLTUuMDg2MzggMy40Nzc4NjctNS4xNDcyNDNMMy44MDgyNjQtNS45MjEwNjhMMy43MzAwMTItNS45ODE5MzFDMy41OTk1OTItNS43OTkzNDMgMy41MTI2NDYtNS43NTU4NyAzLjMzMDA1OC01Ljc1NTg3SDEuNTEyODcyTC41NjUxNTMtMy42OTUyMzRDLjU1NjQ1OS0zLjY3Nzg0NCAuNTU2NDU5LTMuNjY5MTUgLjU1NjQ1OS0zLjY1MTc2Qy41NTY0NTktMy42MDgyODcgLjU5MTIzNy0zLjU4MjIwMyAuNjYwNzk1LTMuNTgyMjAzQy45MzkwMjQtMy41ODIyMDMgMS4yODY4MTEtMy41MjEzNCAxLjY0MzI5Mi0zLjQwODMxQzIuNjQzMTc5LTMuMDg2NjA3IDMuMTAzOTk2LTIuNTQ3NTM4IDMuMTAzOTk2LTEuNjg2NzY1QzMuMTAzOTk2LS44NTIwNzcgMi41NzM2MjItLjE5OTk3NyAxLjg5NTQzNy0uMTk5OTc3QzEuNzIxNTQ0LS4xOTk5NzcgMS41NzM3MzUtLjI2MDg0IDEuMzEyODk1LS40NTIxMjNDMS4wMzQ2NjUtLjY1MjEgLjgzNDY4OC0uNzM5MDQ3IC42NTIxLS43MzkwNDdDLjM5OTk1NS0uNzM5MDQ3IC4yNzgyMjktLjYzNDcxMSAuMjc4MjI5LS40MTczNDRDLjI3ODIyOS0uMDg2OTQ3IC42ODY4NzkgLjEyMTcyNSAxLjMzODk3OSAuMTIxNzI1QzIuMDY5MzMxIC4xMjE3MjUgMi42OTUzNDctLjExMzAzMSAzLjEzMDA4LS41NTY0NTlDMy41MzAwMzUtLjk0NzcxOSAzLjcxMjYyMy0xLjQ0MzMxNSAzLjcxMjYyMy0yLjEwNDExQzMuNzEyNjIzLTIuNzMwMTI2IDMuNTQ3NDI0LTMuMTMwMDggMy4xMTI2OTEtMy41NjQ4MTRDMi43MzAxMjYtMy45NDczNzkgMi4yMzQ1My00LjE0NzM1NiAxLjIwODU1OS00LjMyOTk0NEwxLjU3MzczNS01LjA2ODk5MVonLz4KPHBhdGggaWQ9J2cxLTU0JyBkPSdNMy44Nzc4MjItNS45NDcxNTJDMi44ODY2My01Ljg2MDIwNiAyLjM4MjMzOS01LjY5NTAwNyAxLjc0NzYyOC01LjI1MTU3OUMuODA4NjA0LTQuNTgyMDkgLjI5NTYxOS0zLjU5MDg5OCAuMjk1NjE5LTIuNDI1ODEyQy4yOTU2MTktMS42NjkzNzYgLjUzMDM3NS0uOTA0MjQ1IC45MDQyNDUtLjQ2OTUxMkMxLjIzNDY0My0uMDg2OTQ3IDEuNzA0MTU1IC4xMjE3MjUgMi4yNDMyMjQgLjEyMTcyNUMzLjMyMTM2MyAuMTIxNzI1IDQuMDY5MTA0LS43MDQyNjggNC4wNjkxMDQtMS45MDQxMzJDNC4wNjkxMDQtMy4wMTcwNSAzLjQzNDM5NC0zLjcyMTMxOCAyLjQzNDUwNy0zLjcyMTMxOEMyLjA1MTk0Mi0zLjcyMTMxOCAxLjg2OTM1My0zLjY2MDQ1NSAxLjMyMTU4OS0zLjMzMDA1OEMxLjU1NjM0NS00LjY0Mjk1MiAyLjUzMDE0OC01LjU4MTk3NiAzLjg5NTIxMS01LjgwODAzOEwzLjg3NzgyMi01Ljk0NzE1MlpNMi4xMDQxMS0zLjMyMTM2M0MyLjg1MTg1MS0zLjMyMTM2MyAzLjI4NjU4NC0yLjY5NTM0NyAzLjI4NjU4NC0xLjYwODUxM0MzLjI4NjU4NC0uNjUyMSAyLjk0NzQ5Mi0uMTIxNzI1IDIuMzM4ODY2LS4xMjE3MjVDMS41NzM3MzUtLjEyMTcyNSAxLjEwNDIyMy0uOTM5MDI0IDEuMTA0MjIzLTIuMjg2Njk4QzEuMTA0MjIzLTIuNzMwMTI2IDEuMTczNzgtMi45NzM1NzYgMS4zNDc2NzMtMy4xMDM5OTZDMS41MzAyNjEtMy4yNDMxMTEgMS43OTk3OTYtMy4zMjEzNjMgMi4xMDQxMS0zLjMyMTM2M1onLz4KPHBhdGggaWQ9J2cxLTU1JyBkPSdNMy45MDM5MDYtNS43NTU4N0guNjg2ODc5TC4xNzM4OTMtNC40Nzc3NTRMLjMyMTcwMy00LjQwODE5NkMuNjk1NTczLTQuOTk5NDM0IC44NTIwNzctNS4xMTI0NjQgMS4zMzAyODQtNS4xMTI0NjRIMy4yMTcwMjdMMS40OTU0ODMgLjA2OTU1N0gyLjA2MDYzNkwzLjkwMzkwNi01LjYxNjc1NVYtNS43NTU4N1onLz4KPHBhdGggaWQ9J2cxLTU2JyBkPSdNMi41MjE0NTQtMy4yMjU3MjJDMy4zODIyMjYtMy42ODY1MzkgMy42ODY1MzktNC4wNTE3MTUgMy42ODY1MzktNC42NDI5NTJDMy42ODY1MzktNS4zNTU5MTUgMy4wNjA1MjMtNS44Nzc1OTUgMi4xOTEwNTYtNS44Nzc1OTVDMS4yNDMzMzctNS44Nzc1OTUgLjUzOTA2OS01LjI5NTA1MiAuNTM5MDY5LTQuNTAzODM4Qy41MzkwNjktMy45Mzg2ODQgLjcwNDI2OC0zLjY4NjUzOSAxLjYxNzIwOC0yLjg4NjYzQy42NzgxODQtMi4xNzM2NjcgLjQ4NjkwMS0xLjkwNDEzMiAuNDg2OTAxLTEuMzEyODk1Qy40ODY5MDEtLjQ2OTUxMiAxLjE3Mzc4IC4xMjE3MjUgMi4xNTYyNzggLjEyMTcyNUMzLjE5OTYzOCAuMTIxNzI1IDMuODY5MTI3LS40NTIxMjMgMy44NjkxMjctMS4zNDc2NzNDMy44NjkxMjctMi4wMTcxNjMgMy41NzM1MDgtMi40NDMyMDIgMi41MjE0NTQtMy4yMjU3MjJaTTIuMzY0OTUtMi4zMzAxNzFDMi45OTk2Ni0xLjg3ODA0OCAzLjIwODMzMi0xLjU2NTA0IDMuMjA4MzMyLTEuMDc4MTM5QzMuMjA4MzMyLS41MTI5ODUgMi44MTcwNzItLjEyMTcyNSAyLjI1MTkxOS0uMTIxNzI1QzEuNTkxMTI0LS4xMjE3MjUgMS4xNDc2OTYtLjYyNjAxNiAxLjE0NzY5Ni0xLjM4MjQ1MkMxLjE0NzY5Ni0xLjkzODkxMSAxLjMzODk3OS0yLjMwNDA4NyAxLjg0MzI2OS0yLjcxMjczNkwyLjM2NDk1LTIuMzMwMTcxWk0yLjI2OTMwOC0zLjM4MjIyNkMxLjQ5NTQ4My0zLjg4NjUxNiAxLjE4MjQ3NS00LjI4NjQ3MSAxLjE4MjQ3NS00Ljc3MzM3MkMxLjE4MjQ3NS01LjI3NzY2MyAxLjU3MzczNS01LjYzNDE0NCAyLjEyMTQ5OS01LjYzNDE0NEMyLjcxMjczNi01LjYzNDE0NCAzLjA4NjYwNy01LjI1MTU3OSAzLjA4NjYwNy00LjY1MTY0N0MzLjA4NjYwNy00LjE1NjA1MSAyLjg0MzE1Ni0zLjc2NDc5MSAyLjM0NzU2LTMuNDM0Mzk0QzIuMzA0MDg3LTMuNDA4MzEgMi4zMDQwODctMy40MDgzMSAyLjI2OTMwOC0zLjM4MjIyNlonLz4KPHBhdGggaWQ9J2cxLTU3JyBkPSdNLjUxMjk4NSAuMTkxMjgzQzEuNDg2Nzg4IC4wNzgyNTIgMS45NjQ5OTUtLjA4Njk0NyAyLjU1NjIzMi0uNTEyOTg1QzMuNDYwNDc4LTEuMTczNzggMy45OTA4NTItMi4yNTE5MTkgMy45OTA4NTItMy40MjU2OTlDMy45OTA4NTItNC44NjAzMTkgMy4xOTA5NDMtNS44Nzc1OTUgMi4wNjkzMzEtNS44Nzc1OTVDMS4wMzQ2NjUtNS44Nzc1OTUgLjI2MDg0LTQuOTk5NDM0IC4yNjA4NC0zLjgyNTY1NEMuMjYwODQtMi43NjQ5MDQgLjg4Njg1Ni0yLjA2MDYzNiAxLjgyNTg4LTIuMDYwNjM2QzIuMzA0MDg3LTIuMDYwNjM2IDIuNjY5MjYzLTIuMTk5NzUxIDMuMTMwMDgtMi41NTYyMzJDMi43NzM1OTktMS4xMzkwMDEgMS44MDg0OTEtLjIwODY3MiAuNDg2OTAxIC4wMTczODlMLjUxMjk4NSAuMTkxMjgzWk0zLjE0NzQ3LTMuMDg2NjA3QzMuMTQ3NDctMi45MTI3MTQgMy4xMTI2OTEtMi44MzQ0NjIgMy4wMTcwNS0yLjc1NjIxQzIuNzczNTk5LTIuNTQ3NTM4IDIuNDUxODk2LTIuNDM0NTA3IDIuMTM4ODg4LTIuNDM0NTA3QzEuNDc4MDkzLTIuNDM0NTA3IDEuMDYwNzQ5LTMuMDg2NjA3IDEuMDYwNzQ5LTQuMTIxMjcyQzEuMDYwNzQ5LTQuNjE2ODY4IDEuMTk5ODY0LTUuMTM4NTQ4IDEuMzgyNDUyLTUuMzY0NjFDMS41MzAyNjEtNS41Mzg1MDMgMS43NDc2MjgtNS42MzQxNDQgMS45OTk3NzMtNS42MzQxNDRDMi43NTYyMS01LjYzNDE0NCAzLjE0NzQ3LTQuODg2NDAzIDMuMTQ3NDctMy40MjU2OTlWLTMuMDg2NjA3WicvPgo8cGF0aCBpZD0nZzEtNTgnIGQ9J00xLjE4MjQ3NS0zLjk5MDg1MkMuOTIxNjM1LTMuOTkwODUyIC43MDQyNjgtMy43NjQ3OTEgLjcwNDI2OC0zLjQ5NTI1NkMuNzA0MjY4LTMuMjQzMTExIC45MjE2MzUtMy4wMjU3NDQgMS4xNzM3OC0zLjAyNTc0NEMxLjQ0MzMxNS0zLjAyNTc0NCAxLjY2OTM3Ni0zLjI0MzExMSAxLjY2OTM3Ni0zLjQ5NTI1NkMxLjY2OTM3Ni0zLjc2NDc5MSAxLjQ0MzMxNS0zLjk5MDg1MiAxLjE4MjQ3NS0zLjk5MDg1MlpNMS4xODI0NzUtLjg2OTQ2N0MuOTIxNjM1LS44Njk0NjcgLjcwNDI2OC0uNjQzNDA1IC43MDQyNjgtLjM3Mzg3MUMuNzA0MjY4LS4xMjE3MjUgLjkyMTYzNSAuMDk1NjQxIDEuMTczNzggLjA5NTY0MUMxLjQ0MzMxNSAuMDk1NjQxIDEuNjY5Mzc2LS4xMjE3MjUgMS42NjkzNzYtLjM3Mzg3MUMxLjY2OTM3Ni0uNjQzNDA1IDEuNDQzMzE1LS44Njk0NjcgMS4xODI0NzUtLjg2OTQ2N1onLz4KPHBhdGggaWQ9J2cxLTY1JyBkPSdNNi4xMzg0MzUtLjE2NTE5OUM1Ljc0NzE3NS0uMTkxMjgzIDUuNjYwMjI4LS4yNzgyMjkgNS4zNTU5MTUtLjkyMTYzNUwzLjE5MDk0My01Ljg2MDIwNkgzLjAxNzA1TDEuMjA4NTU5LTEuNTkxMTI0Qy42NTIxLS4zMjE3MDMgLjU0Nzc2NC0uMTgyNTg4IC4xMzA0Mi0uMTY1MTk5VjBIMS44NTE5NjRWLS4xNjUxOTlDMS40MzQ2Mi0uMTY1MTk5IDEuMjYwNzI3LS4yNzgyMjkgMS4yNjA3MjctLjUyMTY4QzEuMjYwNzI3LS42MjYwMTYgMS4yODY4MTEtLjc0Nzc0MSAxLjMzMDI4NC0uODYwNzcyTDEuNzMwMjM5LTEuODc4MDQ4SDQuMDA4MjQyTDQuMzY0NzIzLTEuMDQzMzZDNC40NjkwNTktLjgwODYwNCA0LjUyOTkyMi0uNTgyNTQzIDQuNTI5OTIyLS40NjA4MTdDNC41Mjk5MjItLjI0MzQ1MSA0LjM4MjExMi0uMTczODkzIDMuOTIxMjk1LS4xNjUxOTlWMEg2LjEzODQzNVYtLjE2NTE5OVpNMS44NzgwNDgtMi4yMzQ1M0wyLjg3NzkzNS00LjYyNTU2M0wzLjg4NjUxNi0yLjIzNDUzSDEuODc4MDQ4WicvPgo8cGF0aCBpZD0nZzEtNjYnIGQ9J00uMTQ3ODA5LTUuNzU1ODdWLTUuNTkwNjcxQy44NzgxNjEtNS41NDcxOTggLjk4MjQ5Ny01LjQ1MTU1NiAuOTgyNDk3LTQuODA4MTUxVi0uOTQ3NzE5Qy45ODI0OTctLjMwNDMxMyAuODY5NDY3LS4xOTEyODMgLjE0NzgwOS0uMTY1MTk5VjBIMy4wNTE4MjhDMy43MzAwMTIgMCA0LjM0NzMzNC0uMTgyNTg4IDQuNjY5MDM2LS40NzgyMDdDNC45ODIwNDQtLjc1NjQzNiA1LjE1NTkzOC0xLjE0NzY5NiA1LjE1NTkzOC0xLjU2NTA0QzUuMTU1OTM4LTEuOTQ3NjA1IDQuOTk5NDM0LTIuMjk1MzkyIDQuNzI5ODk5LTIuNTQ3NTM4QzQuNDY5MDU5LTIuNzgyMjk0IDQuMjM0MzAzLTIuODg2NjMgMy42NjkxNS0zLjAyNTc0NEM0LjEyMTI3Mi0zLjEzODc3NSA0LjMwMzg2LTMuMjI1NzIyIDQuNTEyNTMyLTMuNDA4MzFDNC43Mjk4OTktMy41OTk1OTIgNC44NjAzMTktMy45MjEyOTUgNC44NjAzMTktNC4yNzc3NzZDNC44NjAzMTktNS4yNTE1NzkgNC4wODY0OTQtNS43NTU4NyAyLjU4MjMxNi01Ljc1NTg3SC4xNDc4MDlaTTEuODY5MzUzLTIuODM0NDYyQzIuNzEyNzM2LTIuODM0NDYyIDMuMTEyNjkxLTIuNzkwOTg4IDMuNDI1Njk5LTIuNjYwNTY4QzMuOTIxMjk1LTIuNDUxODk2IDQuMTU2MDUxLTIuMTA0MTEgNC4xNTYwNTEtMS41NTYzNDVDNC4xNTYwNTEtMS4wODY4MzMgMy45NzM0NjMtLjc0Nzc0MSAzLjYyNTY3Ni0uNTQ3NzY0QzMuMzQ3NDQ3LS4zOTEyNiAyLjk5MDk2Ni0uMzIxNzAzIDIuNDE3MTE4LS4zMjE3MDNDMS45OTEwNzktLjMyMTcwMyAxLjg2OTM1My0uMzk5OTU1IDEuODY5MzUzLS42NzgxODRWLTIuODM0NDYyWk0xLjg2OTM1My0zLjE4MjI0OFYtNS4xNzMzMjdDMS44NjkzNTMtNS4zNTU5MTUgMS45MzAyMTYtNS40MzQxNjcgMi4wNjA2MzYtNS40MzQxNjdIMi40NDMyMDJDMy40NDMwODgtNS40MzQxNjcgMy45NzM0NjMtNS4wMTY4MjMgMy45NzM0NjMtNC4yNDI5OThDMy45NzM0NjMtMy41NjQ4MTQgMy41MTI2NDYtMy4xODIyNDggMi42OTUzNDctMy4xODIyNDhIMS44NjkzNTNaJy8+CjxwYXRoIGlkPSdnMS02OCcgZD0nTS45MDQyNDUtLjk0NzcxOUMuOTA0MjQ1LS4zMjE3MDMgLjc5OTkwOS0uMjA4NjcyIC4xMzkxMTUtLjE2NTE5OVYwSDIuNjA4NEMzLjYxNjk4MiAwIDQuNTI5OTIyLS4yODY5MjQgNS4wNjg5OTEtLjc3MzgyNUM1LjYzNDE0NC0xLjI4NjgxMSA1Ljk1NTg0Ny0yLjA2MDYzNiA1Ljk1NTg0Ny0yLjkwNDAxOUM1Ljk1NTg0Ny0zLjY4NjUzOSA1LjY5NTAwNy00LjM2NDcyMyA1LjIxNjgtNC44NDI5M0M0LjYyNTU2My01LjQ0Mjg2MiAzLjY3Nzg0NC01Ljc1NTg3IDIuNDg2Njc1LTUuNzU1ODdILjEzOTExNVYtNS41OTA2NzFDLjgyNTk5My01LjUyOTgwOCAuOTA0MjQ1LTUuNDUxNTU2IC45MDQyNDUtNC44MDgxNTFWLS45NDc3MTlaTTEuNzkxMTAxLTUuMDk1MDc1QzEuNzkxMTAxLTUuMzY0NjEgMS44ODY3NDMtNS40MzQxNjcgMi4yNDMyMjQtNS40MzQxNjdDMi45OTA5NjYtNS40MzQxNjcgMy41NTYxMTktNS4yOTUwNTIgMy45NzM0NjMtNC45OTk0MzRDNC42NTE2NDctNC41Mjk5MjIgNS4wMDgxMjgtMy43ODIxOCA1LjAwODEyOC0yLjg0MzE1NkM1LjAwODEyOC0xLjgxNzE4NSA0LjY1MTY0Ny0xLjA4NjgzMyAzLjk0NzM3OS0uNjc4MTg0QzMuNTAzOTUxLS40MjYwMzkgMi45OTk2Ni0uMzIxNzAzIDIuMjQzMjI0LS4zMjE3MDNDMS44OTU0MzctLjMyMTcwMyAxLjc5MTEwMS0uMzk5OTU1IDEuNzkxMTAxLS42NzgxODRWLTUuMDk1MDc1WicvPgo8cGF0aCBpZD0nZzEtNzAnIGQ9J000LjE2NDc0Ni0yLjAwODQ2OFYtNC4wMjU2MzFIMy45NjQ3NjhDMy44NjA0MzItMy4zMzAwNTggMy43MDM5MjgtMy4xOTk2MzggMy4wMDgzNTUtMy4xOTk2MzhIMS43NDc2MjhWLTUuMTI5ODU0QzEuNzQ3NjI4LTUuMzczMzA0IDEuNzkxMTAxLTUuNDI1NDcyIDIuMDI1ODU3LTUuNDI1NDcySDMuMjA4MzMyQzQuMTkwODMtNS40MjU0NzIgNC4zODIxMTItNS4yOTUwNTIgNC41Mjk5MjItNC41MTI1MzJINC43NDcyODhMNC43MjEyMDQtNS43NTU4N0guMTA0MzM2Vi01LjU5MDY3MUMuNzQ3NzQxLTUuNTM4NTAzIC44NjA3NzItNS40MTY3NzggLjg2MDc3Mi00LjgwODE1MVYtMS4wNDMzNkMuODYwNzcyLS4zMjE3MDMgLjc2NTEzMS0uMjA4NjcyIC4xMDQzMzYtLjE2NTE5OVYwSDIuNTM4ODQzVi0uMTY1MTk5QzEuODY5MzUzLS4xOTk5NzcgMS43NDc2MjgtLjMyMTcwMyAxLjc0NzYyOC0uOTQ3NzE5Vi0yLjg0MzE1NkgzLjAwODM1NUMzLjcxMjYyMy0yLjg0MzE1NiAzLjg2MDQzMi0yLjcxMjczNiAzLjk2NDc2OC0yLjAwODQ2OEg0LjE2NDc0NlonLz4KPHBhdGggaWQ9J2cxLTczJyBkPSdNLjk5OTg4Ny0uOTQ3NzE5Qy45OTk4ODctLjI5NTYxOSAuODg2ODU2LS4xOTEyODMgLjE1NjUwNC0uMTY1MTk5VjBIMi43Mzg4MlYtLjE2NTE5OUMyLjAyNTg1Ny0uMTkxMjgzIDEuODg2NzQzLS4zMTMwMDggMS44ODY3NDMtLjk0NzcxOVYtNC44MDgxNTFDMS44ODY3NDMtNS40NDI4NjIgMi4wMDg0NjgtNS41NTU4OTIgMi43Mzg4Mi01LjU5MDY3MVYtNS43NTU4N0guMTU2NTA0Vi01LjU5MDY3MUMuODk1NTUxLTUuNTQ3MTk4IC45OTk4ODctNS40NTE1NTYgLjk5OTg4Ny00LjgwODE1MVYtLjk0NzcxOVonLz4KPHBhdGggaWQ9J2cxLTc3JyBkPSdNNS44NjAyMDYtNC45ODIwNDRWLTEuMDQzMzZDNS44NjAyMDYtLjMyMTcwMyA1Ljc1NTg3LS4yMDg2NzIgNS4wNjg5OTEtLjE2NTE5OVYwSDcuNTAzNDk4Vi0uMTY1MTk5QzYuODY4Nzg3LS4yMDg2NzIgNi43NDcwNjItLjMzMDM5NyA2Ljc0NzA2Mi0uOTQ3NzE5Vi00LjgwODE1MUM2Ljc0NzA2Mi01LjQyNTQ3MiA2Ljg2MDA5My01LjUzODUwMyA3LjUwMzQ5OC01LjU5MDY3MVYtNS43NTU4N0g1Ljc3MzI1OUwzLjg1MTczOC0xLjM2NTA2M0wxLjg0MzI2OS01Ljc1NTg3SC4xMjE3MjVWLTUuNTkwNjcxQy44MzQ2ODgtNS41NDcxOTggLjk0NzcxOS01LjQ0Mjg2MiAuOTQ3NzE5LTQuODA4MTUxVi0xLjI3ODExNkMuOTQ3NzE5LS4zODI1NjUgLjgyNTk5My0uMjE3MzY3IC4xMDQzMzYtLjE2NTE5OVYwSDIuMTQ3NTgzVi0uMTY1MTk5QzEuNDc4MDkzLS4xOTk5NzcgMS4zMzAyODQtLjM5OTk1NSAxLjMzMDI4NC0xLjI3ODExNlYtNC43ODIwNjdMMy41MTI2NDYgMEgzLjYzNDM3MUw1Ljg2MDIwNi00Ljk4MjA0NFonLz4KPHBhdGggaWQ9J2cxLTgzJyBkPSdNMy44ODY1MTYtNS44Nzc1OTVIMy43MDM5MjhDMy42NjkxNS01LjY3NzYxOCAzLjU3MzUwOC01LjU4MTk3NiAzLjQyNTY5OS01LjU4MTk3NkMzLjMzODc1Mi01LjU4MTk3NiAzLjE5MDk0My01LjYxNjc1NSAzLjA0MzEzNC01LjY4NjMxMkMyLjcyMTQzMS01LjgwODAzOCAyLjM5OTcyOC01Ljg3NzU5NSAyLjEyMTQ5OS01Ljg3NzU5NUMxLjc0NzYyOC01Ljg3NzU5NSAxLjM2NTA2My01LjcyOTc4NiAxLjA3ODEzOS01LjQ3NzY0Qy43NzM4MjUtNS4yMDgxMDYgLjYxNzMyMS00Ljg0MjkzIC42MTczMjEtNC4zOTA4MDdDLjYxNzMyMS0zLjY5NTIzNCAuOTk5ODg3LTMuMjA4MzMyIDEuOTczNjg5LTIuNjk1MzQ3QzIuNTk5NzA2LTIuMzY0OTUgMy4wNTE4MjgtMi4wMDg0NjggMy4yNjkxOTUtMS42NzgwNzFDMy4zNDc0NDctMS41NjUwNCAzLjM5MDkyLTEuMzgyNDUyIDMuMzkwOTItMS4xNzM3OEMzLjM5MDkyLS41OTEyMzcgMi45NTYxODctLjE5MTI4MyAyLjMyMTQ3Ni0uMTkxMjgzQzEuNTQ3NjUxLS4xOTEyODMgLjk5OTg4Ny0uNjY5NDg5IC41NjUxNTMtMS43MzAyMzlILjM2NTE3NkwuNjI2MDE2IC4xMTMwMzFILjgxNzI5OUMuODI1OTkzLS4wNTIxNjggLjkzMDMyOS0uMTczODkzIDEuMDYwNzQ5LS4xNzM4OTNDMS4xNTYzOTEtLjE3Mzg5MyAxLjMwNDItLjEzOTExNSAxLjQ2OTM5OS0uMDc4MjUyQzEuNzk5Nzk2IC4wNTIxNjggMi4xNDc1ODMgLjEyMTcyNSAyLjQ5NTM3IC4xMjE3MjVDMy40OTUyNTYgLjEyMTcyNSA0LjI2OTA4Mi0uNTY1MTUzIDQuMjY5MDgyLTEuNDYwNzA0QzQuMjY5MDgyLTIuMTczNjY3IDMuNzkwODc1LTIuNzM4ODIgMi42NDMxNzktMy4zNTYxNDJDMS43MzAyMzktMy44NjA0MzIgMS4zNjUwNjMtNC4yNDI5OTggMS4zNjUwNjMtNC43MTI1MUMxLjM2NTA2My01LjE5MDcxNiAxLjczMDIzOS01LjUyMTExNCAyLjI2OTMwOC01LjUyMTExNEMyLjY2MDU2OC01LjUyMTExNCAzLjAyNTc0NC01LjM1NTkxNSAzLjMzMDA1OC01LjA0MjkwN0MzLjU5OTU5Mi00Ljc2NDY3OCAzLjcyMTMxOC00LjUzODYxNiAzLjg2MDQzMi00LjAyNTYzMUg0LjA3Nzc5OUwzLjg4NjUxNi01Ljg3NzU5NVonLz4KPHBhdGggaWQ9J2cxLTk3JyBkPSdNMy44NDMwNDMtLjU3Mzg0OEMzLjY5NTIzNC0uNDUyMTIzIDMuNTkwODk4LS40MDg2NDkgMy40NjA0NzgtLjQwODY0OUMzLjI2MDUtLjQwODY0OSAzLjE5OTYzOC0uNTMwMzc1IDMuMTk5NjM4LS45MTI5NFYtMi42MDg0QzMuMTk5NjM4LTMuMDYwNTIzIDMuMTU2MTY0LTMuMzEyNjY4IDMuMDI1NzQ0LTMuNTIxMzRDMi44MzQ0NjItMy44MzQzNDggMi40NjA1OTEtMy45OTk1NDcgMS45NDc2MDUtMy45OTk1NDdDMS4xMzAzMDctMy45OTk1NDcgLjQ4NjkwMS0zLjU3MzUwOCAuNDg2OTAxLTMuMDI1NzQ0Qy40ODY5MDEtMi44MjU3NjcgLjY2MDc5NS0yLjY1MTg3NCAuODYwNzcyLTIuNjUxODc0QzEuMDY5NDQ0LTIuNjUxODc0IDEuMjUyMDMyLTIuODI1NzY3IDEuMjUyMDMyLTMuMDE3MDVDMS4yNTIwMzItMy4wNTE4MjggMS4yNDMzMzctMy4wOTUzMDIgMS4yMzQ2NDMtMy4xNTYxNjRDMS4yMTcyNTMtMy4yMzQ0MTYgMS4yMDg1NTktMy4zMDM5NzQgMS4yMDg1NTktMy4zNjQ4MzZDMS4yMDg1NTktMy41OTk1OTIgMS40ODY3ODgtMy43OTA4NzUgMS44MzQ1NzUtMy43OTA4NzVDMi4yNjA2MTQtMy43OTA4NzUgMi40OTUzNy0zLjUzODczIDIuNDk1MzctMy4wNjkyMThWLTIuNTM4ODQzQzEuMTU2MzkxLTEuOTk5NzczIDEuMDA4NTgxLTEuOTMwMjE2IC42MzQ3MTEtMS41OTk4MTlDLjQ0MzQyOC0xLjQyNTkyNSAuMzIxNzAzLTEuMTMwMzA3IC4zMjE3MDMtLjg0MzM4M0MuMzIxNzAzLS4yOTU2MTkgLjcwNDI2OCAuMDg2OTQ3IDEuMjM0NjQzIC4wODY5NDdDMS42MTcyMDggLjA4Njk0NyAxLjk3MzY4OS0uMDk1NjQxIDIuNTA0MDY0LS41NDc3NjRDMi41NDc1MzgtLjA5NTY0MSAyLjcwNDA0MiAuMDg2OTQ3IDMuMDYwNTIzIC4wODY5NDdDMy4zNTYxNDIgLjA4Njk0NyAzLjUzODczLS4wMTczODkgMy44NDMwNDMtLjM0Nzc4N1YtLjU3Mzg0OFpNMi40OTUzNy0xLjA2OTQ0NEMyLjQ5NTM3LS43OTk5MDkgMi40NTE4OTYtLjcyMTY1NyAyLjI2OTMwOC0uNjE3MzIxQzIuMDYwNjM2LS40OTU1OTYgMS44MTcxODUtLjQxNzM0NCAxLjYzNDU5Ny0uNDE3MzQ0QzEuMzMwMjg0LS40MTczNDQgMS4wODY4MzMtLjcxMjk2MyAxLjA4NjgzMy0xLjA4NjgzM1YtMS4xMjE2MTJDMS4wODY4MzMtMS42MzQ1OTcgMS40NDMzMTUtMS45NDc2MDUgMi40OTUzNy0yLjMzMDE3MVYtMS4wNjk0NDRaJy8+CjxwYXRoIGlkPSdnMS05OCcgZD0nTTEuMzMwMjg0LTUuOTIxMDY4TDEuMjg2ODExLTUuOTM4NDU4Qy45MjE2MzUtNS44MDgwMzggLjY4Njg3OS01LjczODQ4IC4yNzgyMjktNS42MjU0NUwuMDI2MDg0LTUuNTU1ODkyVi01LjQxNjc3OEMuMDc4MjUyLTUuNDI1NDcyIC4xMTMwMzEtNS40MjU0NzIgLjE3Mzg5My01LjQyNTQ3MkMuNTIxNjgtNS40MjU0NzIgLjU5OTkzMi01LjM0NzIyIC41OTk5MzItNC45ODIwNDRWLS40Njk1MTJDLjU5OTkzMi0uMTk5OTc3IDEuMzM4OTc5IC4wODY5NDcgMi4wMzQ1NTIgLjA4Njk0N0MzLjE4MjI0OCAuMDg2OTQ3IDQuMDY5MTA0LS44Njk0NjcgNC4wNjkxMDQtMi4xMTI4MDRDNC4wNjkxMDQtMy4xODIyNDggMy40MDgzMS0zLjk5OTU0NyAyLjUzODg0My0zLjk5OTU0N0MyLjAwODQ2OC0zLjk5OTU0NyAxLjUwNDE3Ny0zLjY4NjUzOSAxLjMzMDI4NC0zLjI2MDVWLTUuOTIxMDY4Wk0xLjMzMDI4NC0yLjc5OTY4M0MxLjMzMDI4NC0zLjEzODc3NSAxLjczODkzMy0zLjQ1MTc4MyAyLjE5MTA1Ni0zLjQ1MTc4M0MyLjg2OTI0LTMuNDUxNzgzIDMuMzAzOTc0LTIuNzczNTk5IDMuMzAzOTc0LTEuNzEyODQ5QzMuMzAzOTc0LS43NDc3NDEgMi44ODY2My0uMTkxMjgzIDIuMTczNjY3LS4xOTEyODNDMS43MjE1NDQtLjE5MTI4MyAxLjMzMDI4NC0uMzkxMjYgMS4zMzAyODQtLjYwODYyN1YtMi43OTk2ODNaJy8+CjxwYXRoIGlkPSdnMS05OScgZD0nTTMuNDYwNDc4LTEuMzU2MzY4QzMuMDQzMTM0LS43NDc3NDEgMi43MzAxMjYtLjUzOTA2OSAyLjIzNDUzLS41MzkwNjlDMS40NDMzMTUtLjUzOTA2OSAuODg2ODU2LTEuMjM0NjQzIC44ODY4NTYtMi4yMzQ1M0MuODg2ODU2LTMuMTMwMDggMS4zNjUwNjMtMy43NDc0MDIgMi4wNjkzMzEtMy43NDc0MDJDMi4zODIzMzktMy43NDc0MDIgMi40OTUzNy0zLjY1MTc2IDIuNTgyMzE2LTMuMzMwMDU4TDIuNjM0NDg0LTMuMTM4Nzc1QzIuNzA0MDQyLTIuODk1MzI0IDIuODYwNTQ2LTIuNzM4ODIgMy4wNDMxMzQtMi43Mzg4MkMzLjI2OTE5NS0yLjczODgyIDMuNDYwNDc4LTIuOTA0MDE5IDMuNDYwNDc4LTMuMTAzOTk2QzMuNDYwNDc4LTMuNTkwODk4IDIuODUxODUxLTMuOTk5NTQ3IDIuMTIxNDk5LTMuOTk5NTQ3QzEuNjk1NDYtMy45OTk1NDcgMS4yNTIwMzItMy44MjU2NTQgLjg5NTU1MS0zLjUxMjY0NkMuNDYwODE3LTMuMTMwMDggLjIxNzM2Ny0yLjUzODg0MyAuMjE3MzY3LTEuODUxOTY0Qy4yMTczNjctLjcyMTY1NyAuOTA0MjQ1IC4wODY5NDcgMS44NjkzNTMgLjA4Njk0N0MyLjI2MDYxNCAuMDg2OTQ3IDIuNjA4NC0uMDUyMTY4IDIuOTIxNDA4LS4zMjE3MDNDMy4xNTYxNjQtLjUzMDM3NSAzLjMyMTM2My0uNzY1MTMxIDMuNTgyMjAzLTEuMjc4MTE2TDMuNDYwNDc4LTEuMzU2MzY4WicvPgo8cGF0aCBpZD0nZzEtMTAwJyBkPSdNMi45OTA5NjYgLjA4Njk0N0w0LjI2OTA4Mi0uMzY1MTc2Vi0uNTA0MjkxQzQuMTEyNTc4LS40OTU1OTYgNC4wOTUxODgtLjQ5NTU5NiA0LjA2OTEwNC0uNDk1NTk2QzMuNzU2MDk2LS40OTU1OTYgMy42ODY1MzktLjU5MTIzNyAzLjY4NjUzOS0uOTkxMTkyVi01LjkyMTA2OEwzLjY0MzA2Ni01LjkzODQ1OEMzLjIyNTcyMi01Ljc5MDY0OCAyLjkyMTQwOC01LjcwMzcwMiAyLjM2NDk1LTUuNTU1ODkyVi01LjQxNjc3OEMyLjQzNDUwNy01LjQyNTQ3MiAyLjQ4NjY3NS01LjQyNTQ3MiAyLjU1NjIzMi01LjQyNTQ3MkMyLjg3NzkzNS01LjQyNTQ3MiAyLjk1NjE4Ny01LjMzODUyNiAyLjk1NjE4Ny00Ljk4MjA0NFYtMy42MjU2NzZDMi42MjU3OS0zLjkwMzkwNiAyLjM5MTAzNC0zLjk5OTU0NyAyLjA0MzI0Ny0zLjk5OTU0N0MxLjA0MzM2LTMuOTk5NTQ3IC4yMzQ3NTYtMy4wMTcwNSAuMjM0NzU2LTEuNzgyNDA3Qy4yMzQ3NTYtLjY2OTQ4OSAuODg2ODU2IC4wODY5NDcgMS44NDMyNjkgLjA4Njk0N0MyLjMzMDE3MSAuMDg2OTQ3IDIuNjYwNTY4LS4wODY5NDcgMi45NTYxODctLjQ5NTU5NlYuMDYwODYzTDIuOTkwOTY2IC4wODY5NDdaTTIuOTU2MTg3LS44ODY4NTZDMi45NTYxODctLjgyNTk5MyAyLjg5NTMyNC0uNzIxNjU3IDIuODA4Mzc4LS42MjYwMTZDMi42NTE4NzQtLjQ1MjEyMyAyLjQzNDUwNy0uMzY1MTc2IDIuMTgyMzYyLS4zNjUxNzZDMS40NjA3MDQtLjM2NTE3NiAuOTgyNDk3LTEuMDYwNzQ5IC45ODI0OTctMi4xMzAxOTRDLjk4MjQ5Ny0zLjExMjY5MSAxLjQwODUzNi0zLjc1NjA5NiAyLjA2OTMzMS0zLjc1NjA5NkMyLjUzMDE0OC0zLjc1NjA5NiAyLjk1NjE4Ny0zLjM0NzQ0NyAyLjk1NjE4Ny0yLjg4NjYzVi0uODg2ODU2WicvPgo8cGF0aCBpZD0nZzEtMTAxJyBkPSdNMy41NDc0MjQtMS40MjU5MjVDMy4xMzAwOC0uNzY1MTMxIDIuNzU2MjEtLjUxMjk4NSAyLjE5OTc1MS0uNTEyOTg1QzEuNzA0MTU1LS41MTI5ODUgMS4zMzAyODQtLjc2NTEzMSAxLjA3ODEzOS0xLjI2MDcyN0MuOTIxNjM1LTEuNTkxMTI0IC44NjA3NzItMS44NzgwNDggLjg0MzM4My0yLjQwODQyM0gzLjUyMTM0QzMuNDUxNzgzLTIuOTczNTc2IDMuMzY0ODM2LTMuMjI1NzIyIDMuMTQ3NDctMy41MDM5NTFDMi44ODY2My0zLjgxNjk1OSAyLjQ4NjY3NS0zLjk5OTU0NyAyLjAzNDU1Mi0zLjk5OTU0N0MxLjU5OTgxOS0zLjk5OTU0NyAxLjE5MTE2OS0zLjg0MzA0MyAuODYwNzcyLTMuNTQ3NDI0Qy40NTIxMjMtMy4xOTA5NDMgLjIxNzM2Ny0yLjU3MzYyMiAuMjE3MzY3LTEuODYwNjU5Qy4yMTczNjctLjY2MDc5NSAuODQzMzgzIC4wODY5NDcgMS44NDMyNjkgLjA4Njk0N0MyLjY2OTI2MyAuMDg2OTQ3IDMuMzIxMzYzLS40MjYwMzkgMy42ODY1MzktMS4zNjUwNjNMMy41NDc0MjQtMS40MjU5MjVaTS44NjA3NzItMi42ODY2NTJDLjk1NjQxMy0zLjM2NDgzNiAxLjI1MjAzMi0zLjY4NjUzOSAxLjc4MjQwNy0zLjY4NjUzOVMyLjUyMTQ1NC0zLjQ0MzA4OCAyLjYzNDQ4NC0yLjY4NjY1MkguODYwNzcyWicvPgo8cGF0aCBpZD0nZzEtMTAyJyBkPSdNMi42ODY2NTItMy45MTI2SDEuNjE3MjA4Vi00LjkyMTE4MkMxLjYxNzIwOC01LjQyNTQ3MiAxLjc4MjQwNy01LjY5NTAwNyAyLjExMjgwNC01LjY5NTAwN0MyLjI5NTM5Mi01LjY5NTAwNyAyLjQxNzExOC01LjYwODA2IDIuNTczNjIyLTUuMzU1OTE1QzIuNzEyNzM2LTUuMTI5ODU0IDIuODE3MDcyLTUuMDQyOTA3IDIuOTY0ODgyLTUuMDQyOTA3QzMuMTY0ODU5LTUuMDQyOTA3IDMuMzMwMDU4LTUuMTk5NDExIDMuMzMwMDU4LTUuMzk5Mzg4QzMuMzMwMDU4LTUuNzEyMzk2IDIuOTQ3NDkyLTUuOTM4NDU4IDIuNDI1ODEyLTUuOTM4NDU4QzEuODg2NzQzLTUuOTM4NDU4IDEuNDI1OTI1LTUuNzAzNzAyIDEuMTk5ODY0LTUuMzAzNzQ3Qy45NzM4MDMtNC45MjExODIgLjkwNDI0NS00LjYwODE3NCAuODk1NTUxLTMuOTEyNkguMTgyNTg4Vi0zLjYzNDM3MUguODk1NTUxVi0uOTA0MjQ1Qy44OTU1NTEtLjI2OTUzNSAuNzk5OTA5LS4xNjUxOTkgLjE3Mzg5My0uMTMwNDJWMEgyLjQzNDUwN1YtLjEzMDQyQzEuNzIxNTQ0LS4xNTY1MDQgMS42MjU5MDMtLjI1MjE0NSAxLjYyNTkwMy0uOTA0MjQ1Vi0zLjYzNDM3MUgyLjY4NjY1MlYtMy45MTI2WicvPgo8cGF0aCBpZD0nZzEtMTAzJyBkPSdNNC4wODY0OTQtMy4zNzM1MzFWLTMuNzEyNjIzSDMuNDE3MDA0QzMuMjQzMTExLTMuNzEyNjIzIDMuMTEyNjkxLTMuNzM4NzA3IDIuOTM4Nzk4LTMuNzk5NTdMMi43NDc1MTUtMy44NjkxMjdDMi41MTI3NTktMy45NTYwNzQgMi4yNzgwMDMtMy45OTk1NDcgMi4wNTE5NDItMy45OTk1NDdDMS4yNDMzMzctMy45OTk1NDcgLjU5OTkzMi0zLjM3MzUzMSAuNTk5OTMyLTIuNTgyMzE2Qy41OTk5MzItMi4wMzQ1NTIgLjgzNDY4OC0xLjcwNDE1NSAxLjQwODUzNi0xLjQxNzIzMUMxLjI0MzMzNy0xLjI2MDcyNyAxLjA4NjgzMy0xLjExMjkxNyAxLjAzNDY2NS0xLjA2OTQ0NEMuNzQ3NzQxLS44MTcyOTkgLjYzNDcxMS0uNjQzNDA1IC42MzQ3MTEtLjQ2OTUxMkMuNjM0NzExLS4yODY5MjQgLjczOTA0Ny0uMTgyNTg4IDEuMDk1NTI4LS4wMDg2OTVDLjQ3ODIwNyAuNDQzNDI4IC4yNDM0NTEgLjczMDM1MiAuMjQzNDUxIDEuMDUyMDU1Qy4yNDM0NTEgMS41MTI4NzIgLjkyMTYzNSAxLjg5NTQzNyAxLjc0NzYyOCAxLjg5NTQzN0MyLjM5OTcyOCAxLjg5NTQzNyAzLjA3NzkxMiAxLjY2OTM3NiAzLjUzMDAzNSAxLjMwNDJDMy44NjA0MzIgMS4wMzQ2NjUgNC4wMDgyNDIgLjc1NjQzNiA0LjAwODI0MiAuNDI2MDM5QzQuMDA4MjQyLS4xMTMwMzEgMy41OTk1OTItLjQ3ODIwNyAyLjk1NjE4Ny0uNTA0MjkxTDEuODM0NTc1LS41NTY0NTlDMS4zNzM3NTctLjU3Mzg0OCAxLjE1NjM5MS0uNjUyMSAxLjE1NjM5MS0uNzkxMjE1QzEuMTU2MzkxLS45NjUxMDggMS40NDMzMTUtMS4yNjk0MjEgMS42NzgwNzEtMS4zMzg5NzlDMS43NTYzMjMtMS4zMzAyODQgMS44MTcxODUtMS4zMjE1ODkgMS44NDMyNjktMS4zMjE1ODlDMi4wMDg0NjgtMS4zMDQyIDIuMTIxNDk5LTEuMjk1NTA1IDIuMTczNjY3LTEuMjk1NTA1QzIuNDk1MzctMS4yOTU1MDUgMi44NDMxNTYtMS40MjU5MjUgMy4xMTI2OTEtMS42NjA2ODFDMy4zOTk2MTUtMS45MDQxMzIgMy41MzAwMzUtMi4yMDg0NDYgMy41MzAwMzUtMi42NDMxNzlDMy41MzAwMzUtMi44OTUzMjQgMy40ODY1NjItMy4wOTUzMDIgMy4zNjQ4MzYtMy4zNzM1MzFINC4wODY0OTRaTTEuMjc4MTE2IC4wMTczODlDMS41NjUwNCAuMDc4MjUyIDIuMjYwNjE0IC4xMzA0MiAyLjY4NjY1MiAuMTMwNDJDMy40Nzc4NjcgLjEzMDQyIDMuNzY0NzkxIC4yNDM0NTEgMy43NjQ3OTEgLjU1NjQ1OUMzLjc2NDc5MSAxLjA2MDc0OSAzLjEwMzk5NiAxLjM5OTg0MSAyLjEyMTQ5OSAxLjM5OTg0MUMxLjM1NjM2OCAxLjM5OTg0MSAuODUyMDc3IDEuMTQ3Njk2IC44NTIwNzcgLjc2NTEzMUMuODUyMDc3IC41NjUxNTMgLjkxMjk0IC40NTIxMjMgMS4yNzgxMTYgLjAxNzM4OVpNMS4zMjE1ODktMi45Mzg3OThDMS4zMjE1ODktMy40NTE3ODMgMS41NjUwNC0zLjc1NjA5NiAxLjk2NDk5NS0zLjc1NjA5NkMyLjIzNDUzLTMuNzU2MDk2IDIuNDYwNTkxLTMuNjA4Mjg3IDIuNTk5NzA2LTMuMzQ3NDQ3QzIuNzU2MjEtMy4wNDMxMzQgMi44NjA1NDYtMi42NDMxNzkgMi44NjA1NDYtMi4zMDQwODdDMi44NjA1NDYtMS44MTcxODUgMi42MDg0LTEuNTEyODcyIDIuMjA4NDQ2LTEuNTEyODcyQzEuNjg2NzY1LTEuNTEyODcyIDEuMzIxNTg5LTIuMDc4MDI2IDEuMzIxNTg5LTIuOTEyNzE0Vi0yLjkzODc5OFonLz4KPHBhdGggaWQ9J2cxLTEwNCcgZD0nTTEuMzY1MDYzLTIuOTgyMjcxQzEuNzMwMjM5LTMuMzgyMjI2IDEuOTkxMDc5LTMuNTMwMDM1IDIuMzMwMTcxLTMuNTMwMDM1QzIuNzY0OTA0LTMuNTMwMDM1IDIuOTgyMjcxLTMuMjE3MDI3IDIuOTgyMjcxLTIuNjA4NFYtLjg4Njg1NkMyLjk4MjI3MS0uMjk1NjE5IDIuODk1MzI0LS4xODI1ODggMi4zOTEwMzQtLjEzMDQyVjBINC4yMzQzMDNWLS4xMzA0MkMzLjc2NDc5MS0uMjE3MzY3IDMuNzEyNjIzLS4yODY5MjQgMy43MTI2MjMtLjg4Njg1NlYtMi42MTcwOTVDMy43MTI2MjMtMy41MzAwMzUgMy4zNDc0NDctMy45OTk1NDcgMi42NDMxNzktMy45OTk1NDdDMi4xMzAxOTQtMy45OTk1NDcgMS43NjUwMTctMy43OTA4NzUgMS4zNjUwNjMtMy4yNjkxOTVWLTUuOTEyMzc0TDEuMzIxNTg5LTUuOTM4NDU4QzEuMDI1OTcxLTUuODM0MTIyIC44MDg2MDQtNS43NjQ1NjQgLjMyMTcwMy01LjYyNTQ1TC4wODY5NDctNS41NTU4OTJWLTUuNDE2Nzc4Qy4xMjE3MjUtNS40MjU0NzIgLjE0NzgwOS01LjQyNTQ3MiAuMTkxMjgzLTUuNDI1NDcyQy41NjUxNTMtNS40MjU0NzIgLjYzNDcxMS01LjM1NTkxNSAuNjM0NzExLTQuOTgyMDQ0Vi0uODg2ODU2Qy42MzQ3MTEtLjI3ODIyOSAuNTgyNTQzLS4xOTk5NzcgLjA3ODI1Mi0uMTMwNDJWMEgxLjk1NjNWLS4xMzA0MkMxLjQ1MjAwOS0uMTgyNTg4IDEuMzY1MDYzLS4yODY5MjQgMS4zNjUwNjMtLjg4Njg1NlYtMi45ODIyNzFaJy8+CjxwYXRoIGlkPSdnMS0xMDUnIGQ9J00xLjUyMTU2Ny0zLjk5OTU0N0wuMTczODkzLTMuNTIxMzRWLTMuMzkwOTJMLjI0MzQ1MS0zLjM5OTYxNUMuMzQ3Nzg3LTMuNDE3MDA0IC40NjA4MTctMy40MjU2OTkgLjUzOTA2OS0zLjQyNTY5OUMuNzQ3NzQxLTMuNDI1Njk5IC44MjU5OTMtMy4yODY1ODQgLjgyNTk5My0yLjkwNDAxOVYtLjg4Njg1NkMuODI1OTkzLS4yNjA4NCAuNzM5MDQ3LS4xNjUxOTkgLjEzOTExNS0uMTMwNDJWMEgyLjE5OTc1MVYtLjEzMDQyQzEuNjI1OTAzLS4xNzM4OTMgMS41NTYzNDUtLjI2MDg0IDEuNTU2MzQ1LS44ODY4NTZWLTMuOTczNDYzTDEuNTIxNTY3LTMuOTk5NTQ3Wk0xLjExMjkxNy01LjkzODQ1OEMuODc4MTYxLTUuOTM4NDU4IC42NzgxODQtNS43Mzg0OCAuNjc4MTg0LTUuNDk1MDNTLjg2OTQ2Ny01LjA1MTYwMiAxLjExMjkxNy01LjA1MTYwMkMxLjM2NTA2My01LjA1MTYwMiAxLjU2NTA0LTUuMjQyODg0IDEuNTY1MDQtNS40OTUwM0MxLjU2NTA0LTUuNzM4NDggMS4zNjUwNjMtNS45Mzg0NTggMS4xMTI5MTctNS45Mzg0NThaJy8+CjxwYXRoIGlkPSdnMS0xMDgnIGQ9J00uMTY1MTk5LTUuNDE2Nzc4SC4yMTczNjdDLjMxMzAwOC01LjQyNTQ3MiAuNDE3MzQ0LTUuNDM0MTY3IC40ODY5MDEtNS40MzQxNjdDLjc2NTEzMS01LjQzNDE2NyAuODUyMDc3LTUuMzEyNDQyIC44NTIwNzctNC45MDM3OTJWLS43NTY0MzZDLjg1MjA3Ny0uMjg2OTI0IC43MzAzNTItLjE3Mzg5MyAuMTgyNTg4LS4xMzA0MlYwSDIuMjM0NTNWLS4xMzA0MkMxLjY4Njc2NS0uMTY1MTk5IDEuNTgyNDI5LS4yNTIxNDUgMS41ODI0MjktLjczMDM1MlYtNS45MjEwNjhMMS41NDc2NTEtNS45Mzg0NThDMS4wOTU1MjgtNS43OTA2NDggLjc2NTEzMS01LjcwMzcwMiAuMTY1MTk5LTUuNTU1ODkyVi01LjQxNjc3OFonLz4KPHBhdGggaWQ9J2cxLTEwOScgZD0nTS4xNjUxOTktMy40NjA0NzhDLjI3ODIyOS0zLjQ4NjU2MiAuMzQ3Nzg3LTMuNDk1MjU2IC40NDM0MjgtMy40OTUyNTZDLjY2OTQ4OS0zLjQ5NTI1NiAuNzQ3NzQxLTMuMzU2MTQyIC43NDc3NDEtMi45Mzg3OThWLS43MzkwNDdDLjc0Nzc0MS0uMjY5NTM1IC42MjYwMTYtLjEzOTExNSAuMTM5MTE1LS4xMzA0MlYwSDIuMDY5MzMxVi0uMTMwNDJDMS42MDg1MTMtLjE0NzgwOSAxLjQ3ODA5My0uMjQzNDUxIDEuNDc4MDkzLS41ODI1NDNWLTMuMDM0NDM5QzEuNDc4MDkzLTMuMDUxODI4IDEuNTQ3NjUxLTMuMTM4Nzc1IDEuNjA4NTEzLTMuMTk5NjM4QzEuODI1ODgtMy4zOTk2MTUgMi4xOTk3NTEtMy41NDc0MjQgMi41MDQwNjQtMy41NDc0MjRDMi44ODY2My0zLjU0NzQyNCAzLjA3NzkxMi0zLjI0MzExMSAzLjA3NzkxMi0yLjYzNDQ4NFYtLjc0Nzc0MUMzLjA3NzkxMi0uMjYwODQgMi45ODIyNzEtLjE2NTE5OSAyLjQ4NjY3NS0uMTMwNDJWMEg0LjQzNDI4Vi0uMTMwNDJDMy45Mzg2ODQtLjEzOTExNSAzLjgwODI2NC0uMjg2OTI0IDMuODA4MjY0LS44MjU5OTNWLTMuMDE3MDVDNC4wNjkxMDQtMy4zOTA5MiA0LjM1NjAyOC0zLjU0NzQyNCA0Ljc1NTk4My0zLjU0NzQyNEM1LjI1MTU3OS0zLjU0NzQyNCA1LjQwODA4My0zLjMxMjY2OCA1LjQwODA4My0yLjU5MTAxMVYtLjc1NjQzNkM1LjQwODA4My0uMjYwODQgNS4zMzg1MjYtLjE5MTI4MyA0LjgzNDIzNS0uMTMwNDJWMEg2LjczODM2N1YtLjEzMDQyTDYuNTEyMzA2LS4xNDc4MDlDNi4yNTE0NjYtLjE2NTE5OSA2LjEzODQzNS0uMzIxNzAzIDYuMTM4NDM1LS42NjA3OTVWLTIuNDUxODk2QzYuMTM4NDM1LTMuNDc3ODY3IDUuNzk5MzQzLTMuOTk5NTQ3IDUuMTI5ODU0LTMuOTk5NTQ3QzQuNjI1NTYzLTMuOTk5NTQ3IDQuMTgyMTM1LTMuNzczNDg2IDMuNzEyNjIzLTMuMjY5MTk1QzMuNTU2MTE5LTMuNzY0NzkxIDMuMjYwNS0zLjk5OTU0NyAyLjc5MDk4OC0zLjk5OTU0N0MyLjQwODQyMy0zLjk5OTU0NyAyLjE2NDk3Mi0zLjg3NzgyMiAxLjQ0MzMxNS0zLjMzMDA1OFYtMy45ODIxNThMMS4zODI0NTItMy45OTk1NDdDLjkzOTAyNC0zLjgzNDM0OCAuNjQzNDA1LTMuNzM4NzA3IC4xNjUxOTktMy42MDgyODdWLTMuNDYwNDc4WicvPgo8cGF0aCBpZD0nZzEtMTEwJyBkPSdNLjEzOTExNS0zLjQ2MDQ3OEMuMTkxMjgzLTMuNDg2NTYyIC4yNzgyMjktMy40OTUyNTYgLjM3Mzg3MS0zLjQ5NTI1NkMuNjE3MzIxLTMuNDk1MjU2IC42OTU1NzMtMy4zNjQ4MzYgLjY5NTU3My0yLjkzODc5OFYtLjc4MjUyQy42OTU1NzMtLjI4NjkyNCAuNTk5OTMyLS4xNjUxOTkgLjE1NjUwNC0uMTMwNDJWMEgxLjk5OTc3M1YtLjEzMDQyQzEuNTU2MzQ1LS4xNjUxOTkgMS40MjU5MjUtLjI2OTUzNSAxLjQyNTkyNS0uNTgyNTQzVi0zLjAyNTc0NEMxLjg0MzI2OS0zLjQxNzAwNCAyLjAzNDU1Mi0zLjUyMTM0IDIuMzIxNDc2LTMuNTIxMzRDMi43NDc1MTUtMy41MjEzNCAyLjk1NjE4Ny0zLjI1MTgwNiAyLjk1NjE4Ny0yLjY3Nzk1OFYtLjg2MDc3MkMyLjk1NjE4Ny0uMzEzMDA4IDIuODQzMTU2LS4xNjUxOTkgMi40MDg0MjMtLjEzMDQyVjBINC4yMTY5MTRWLS4xMzA0MkMzLjc5MDg3NS0uMTczODkzIDMuNjg2NTM5LS4yNzgyMjkgMy42ODY1MzktLjcwNDI2OFYtMi42OTUzNDdDMy42ODY1MzktMy41MTI2NDYgMy4zMDM5NzQtMy45OTk1NDcgMi42NjA1NjgtMy45OTk1NDdDMi4yNjA2MTQtMy45OTk1NDcgMS45OTEwNzktMy44NTE3MzggMS4zOTk4NDEtMy4yOTUyNzlWLTMuOTgyMTU4TDEuMzM4OTc5LTMuOTk5NTQ3Qy45MTI5NC0zLjg0MzA0MyAuNjE3MzIxLTMuNzQ3NDAyIC4xMzkxMTUtMy42MDgyODdWLTMuNDYwNDc4WicvPgo8cGF0aCBpZD0nZzEtMTExJyBkPSdNMi4xNzM2NjctMy45OTk1NDdDMS4wNDMzNi0zLjk5OTU0NyAuMjUyMTQ1LTMuMTY0ODU5IC4yNTIxNDUtMS45NjQ5OTVDLjI1MjE0NS0uNzkxMjE1IDEuMDYwNzQ5IC4wODY5NDcgMi4xNTYyNzggLjA4Njk0N1M0LjA4NjQ5NC0uODM0Njg4IDQuMDg2NDk0LTIuMDM0NTUyQzQuMDg2NDk0LTMuMTczNTU0IDMuMjg2NTg0LTMuOTk5NTQ3IDIuMTczNjY3LTMuOTk5NTQ3Wk0yLjA2MDYzNi0zLjc1NjA5NkMyLjc5MDk4OC0zLjc1NjA5NiAzLjMwMzk3NC0yLjkyMTQwOCAzLjMwMzk3NC0xLjczMDIzOUMzLjMwMzk3NC0uNzQ3NzQxIDIuOTEyNzE0LS4xNTY1MDQgMi4yNjA2MTQtLjE1NjUwNEMxLjkyMTUyMS0uMTU2NTA0IDEuNTk5ODE5LS4zNjUxNzYgMS40MTcyMzEtLjcxMjk2M0MxLjE3Mzc4LTEuMTY1MDg1IDEuMDM0NjY1LTEuNzczNzEyIDEuMDM0NjY1LTIuMzkxMDM0QzEuMDM0NjY1LTMuMjE3MDI3IDEuNDQzMzE1LTMuNzU2MDk2IDIuMDYwNjM2LTMuNzU2MDk2WicvPgo8cGF0aCBpZD0nZzEtMTEyJyBkPSdNLjA3ODI1Mi0zLjQxNzAwNEMuMTU2NTA0LTMuNDI1Njk5IC4yMTczNjctMy40MjU2OTkgLjI5NTYxOS0zLjQyNTY5OUMuNTkxMjM3LTMuNDI1Njk5IC42NTIxLTMuMzM4NzUyIC42NTIxLTIuOTMwMTAzVjEuMTM5MDAxQy42NTIxIDEuNTkxMTI0IC41NTY0NTkgMS42ODY3NjUgLjA0MzQ3MyAxLjczODkzM1YxLjg4Njc0M0gyLjE0NzU4M1YxLjczMDIzOUMxLjQ5NTQ4MyAxLjcyMTU0NCAxLjM4MjQ1MiAxLjYyNTkwMyAxLjM4MjQ1MiAxLjA3ODEzOVYtLjI4NjkyNEMxLjY4Njc2NSAwIDEuODk1NDM3IC4wODY5NDcgMi4yNjA2MTQgLjA4Njk0N0MzLjI4NjU4NCAuMDg2OTQ3IDQuMDg2NDk0LS44ODY4NTYgNC4wODY0OTQtMi4xNDc1ODNDNC4wODY0OTQtMy4yMjU3MjIgMy40Nzc4NjctMy45OTk1NDcgMi42MzQ0ODQtMy45OTk1NDdDMi4xNDc1ODMtMy45OTk1NDcgMS43NjUwMTctMy43ODIxOCAxLjM4MjQ1Mi0zLjMxMjY2OFYtMy45ODIxNThMMS4zMzAyODQtMy45OTk1NDdDLjg2MDc3Mi0zLjgxNjk1OSAuNTU2NDU5LTMuNzAzOTI4IC4wNzgyNTItMy41NTYxMTlWLTMuNDE3MDA0Wk0xLjM4MjQ1Mi0yLjkwNDAxOUMxLjM4MjQ1Mi0zLjE2NDg1OSAxLjg2OTM1My0zLjQ3Nzg2NyAyLjI2OTMwOC0zLjQ3Nzg2N0MyLjkxMjcxNC0zLjQ3Nzg2NyAzLjMzODc1Mi0yLjgxNzA3MiAzLjMzODc1Mi0xLjgwODQ5MUMzLjMzODc1Mi0uODQzMzgzIDIuOTEyNzE0LS4xOTEyODMgMi4yODY2OTgtLjE5MTI4M0MxLjg3ODA0OC0uMTkxMjgzIDEuMzgyNDUyLS41MDQyOTEgMS4zODI0NTItLjc2NTEzMVYtMi45MDQwMTlaJy8+CjxwYXRoIGlkPSdnMS0xMTQnIGQ9J00uMDYwODYzLTMuMzkwOTJDLjE4MjU4OC0zLjQxNzAwNCAuMjYwODQtMy40MjU2OTkgLjM2NTE3Ni0zLjQyNTY5OUMuNTgyNTQzLTMuNDI1Njk5IC42NjA3OTUtMy4yODY1ODQgLjY2MDc5NS0yLjkwNDAxOVYtLjczMDM1MkMuNjYwNzk1LS4yOTU2MTkgLjU5OTkzMi0uMjM0NzU2IC4wNDM0NzMtLjEzMDQyVjBIMi4xMzAxOTRWLS4xMzA0MkMxLjUzODk1Ni0uMTU2NTA0IDEuMzkxMTQ3LS4yODY5MjQgMS4zOTExNDctLjc4MjUyVi0yLjczODgyQzEuMzkxMTQ3LTMuMDE3MDUgMS43NjUwMTctMy40NTE3ODMgMS45OTk3NzMtMy40NTE3ODNDMi4wNTE5NDItMy40NTE3ODMgMi4xMzAxOTQtMy40MDgzMSAyLjIyNTgzNS0zLjMyMTM2M0MyLjM2NDk1LTMuMTk5NjM4IDIuNDYwNTkxLTMuMTQ3NDcgMi41NzM2MjItMy4xNDc0N0MyLjc4MjI5NC0zLjE0NzQ3IDIuOTEyNzE0LTMuMjk1Mjc5IDIuOTEyNzE0LTMuNTM4NzNDMi45MTI3MTQtMy44MjU2NTQgMi43MzAxMjYtMy45OTk1NDcgMi40MzQ1MDctMy45OTk1NDdDMi4wNjkzMzEtMy45OTk1NDcgMS44MTcxODUtMy43OTk1NyAxLjM5MTE0Ny0zLjE4MjI0OFYtMy45ODIxNThMMS4zNDc2NzMtMy45OTk1NDdDLjg4Njg1Ni0zLjgwODI2NCAuNTczODQ4LTMuNjk1MjM0IC4wNjA4NjMtMy41MzAwMzVWLTMuMzkwOTJaJy8+CjxwYXRoIGlkPSdnMS0xMTUnIGQ9J00yLjczODgyLTIuNzMwMTI2TDIuNzA0MDQyLTMuOTEyNkgyLjYwODRMMi41OTEwMTEtMy44OTUyMTFDMi41MTI3NTktMy44MzQzNDggMi41MDQwNjQtMy44MjU2NTQgMi40NjkyODYtMy44MjU2NTRDMi40MTcxMTgtMy44MjU2NTQgMi4zMzAxNzEtMy44NDMwNDMgMi4yMzQ1My0zLjg4NjUxNkMyLjA0MzI0Ny0zLjk1NjA3NCAxLjg1MTk2NC0zLjk5MDg1MiAxLjYyNTkwMy0zLjk5MDg1MkMuOTM5MDI0LTMuOTkwODUyIC40NDM0MjgtMy41NDc0MjQgLjQ0MzQyOC0yLjkyMTQwOEMuNDQzNDI4LTIuNDM0NTA3IC43MjE2NTctMi4wODY3MiAxLjQ2MDcwNC0xLjY2OTM3NkwxLjk2NDk5NS0xLjM4MjQ1MkMyLjI2OTMwOC0xLjIwODU1OSAyLjQxNzExOC0uOTk5ODg3IDIuNDE3MTE4LS43MzAzNTJDMi40MTcxMTgtLjM0Nzc4NyAyLjEzODg4OC0uMTA0MzM2IDEuNjk1NDYtLjEwNDMzNkMxLjM5OTg0MS0uMTA0MzM2IDEuMTMwMzA3LS4yMTczNjcgLjk2NTEwOC0uNDA4NjQ5Qy43ODI1Mi0uNjI2MDE2IC43MDQyNjgtLjgyNTk5MyAuNTkxMjM3LTEuMzIxNTg5SC40NTIxMjNWLjAzNDc3OUguNTY1MTUzQy42MjYwMTYtLjA1MjE2OCAuNjYwNzk1LS4wNjk1NTcgLjc2NTEzMS0uMDY5NTU3Qy44NDMzODMtLjA2OTU1NyAuOTY1MTA4LS4wNTIxNjggMS4xNjUwODUgMEMxLjQwODUzNiAuMDUyMTY4IDEuNjQzMjkyIC4wODY5NDcgMS43OTk3OTYgLjA4Njk0N0MyLjQ2OTI4NiAuMDg2OTQ3IDMuMDI1NzQ0LS40MTczNDQgMy4wMjU3NDQtMS4wMjU5NzFDMy4wMjU3NDQtMS40NjA3MDQgMi44MTcwNzItMS43NDc2MjggMi4yOTUzOTItMi4wNjA2MzZMMS4zNTYzNjgtMi42MTcwOTVDMS4xMTI5MTctMi43NTYyMSAuOTgyNDk3LTIuOTczNTc2IC45ODI0OTctMy4yMDgzMzJDLjk4MjQ5Ny0zLjU1NjExOSAxLjI1MjAzMi0zLjc5OTU3IDEuNjUxOTg3LTMuNzk5NTdDMi4xNDc1ODMtMy43OTk1NyAyLjQwODQyMy0zLjUwMzk1MSAyLjYwODQtMi43MzAxMjZIMi43Mzg4MlonLz4KPHBhdGggaWQ9J2cxLTExNicgZD0nTTIuMjE3MTQtMy45MTI2SDEuMzM4OTc5Vi00LjkyMTE4MkMxLjMzODk3OS01LjAwODEyOCAxLjMzMDI4NC01LjAzNDIxMiAxLjI3ODExNi01LjAzNDIxMkMxLjIxNzI1My00Ljk1NTk2IDEuMTY1MDg1LTQuODc3NzA4IDEuMTA0MjIzLTQuNzkwNzYyQy43NzM4MjUtNC4zMTI1NTUgLjM5OTk1NS0zLjg5NTIxMSAuMjYwODQtMy44NjA0MzJDLjE2NTE5OS0zLjc5OTU3IC4xMTMwMzEtMy43Mzg3MDcgLjExMzAzMS0zLjY5NTIzNEMuMTEzMDMxLTMuNjY5MTUgLjEyMTcyNS0zLjY1MTc2IC4xNDc4MDktMy42MzQzNzFILjYwODYyN1YtMS4wMTcyNzZDLjYwODYyNy0uMjg2OTI0IC44Njk0NjcgLjA4Njk0NyAxLjM4MjQ1MiAuMDg2OTQ3QzEuODA4NDkxIC4wODY5NDcgMi4xMzg4ODgtLjEyMTcyNSAyLjQyNTgxMi0uNTczODQ4TDIuMzEyNzgyLS42Njk0ODlDMi4xMzAxOTQtLjQ1MjEyMyAxLjk4MjM4NC0uMzY1MTc2IDEuNzkxMTAxLS4zNjUxNzZDMS40NjkzOTktLjM2NTE3NiAxLjMzODk3OS0uNTk5OTMyIDEuMzM4OTc5LTEuMTQ3Njk2Vi0zLjYzNDM3MUgyLjIxNzE0Vi0zLjkxMjZaJy8+CjxwYXRoIGlkPSdnMS0xMTcnIGQ9J000LjE2NDc0Ni0uNDM0NzMzSDQuMTIxMjcyQzMuNzIxMzE4LS40MzQ3MzMgMy42MjU2NzYtLjUzMDM3NSAzLjYyNTY3Ni0uOTMwMzI5Vi0zLjkxMjZIMi4yNTE5MTlWLTMuNzY0NzkxQzIuNzkwOTg4LTMuNzM4NzA3IDIuODk1MzI0LTMuNjUxNzYgMi44OTUzMjQtMy4yMTcwMjdWLTEuMTczNzhDMi44OTUzMjQtLjkzMDMyOSAyLjg1MTg1MS0uODA4NjA0IDIuNzMwMTI2LS43MTI5NjNDMi40OTUzNy0uNTIxNjggMi4yMjU4MzUtLjQxNzM0NCAxLjk2NDk5NS0uNDE3MzQ0QzEuNjI1OTAzLS40MTczNDQgMS4zNDc2NzMtLjcxMjk2MyAxLjM0NzY3My0xLjA3ODEzOVYtMy45MTI2SC4wNzgyNTJWLTMuNzkwODc1Qy40OTU1OTYtMy43NjQ3OTEgLjYxNzMyMS0zLjYzNDM3MSAuNjE3MzIxLTMuMjM0NDE2Vi0xLjA0MzM2Qy42MTczMjEtLjM1NjQ4MSAxLjAzNDY2NSAuMDg2OTQ3IDEuNjY5Mzc2IC4wODY5NDdDMS45OTEwNzkgLjA4Njk0NyAyLjMzMDE3MS0uMDUyMTY4IDIuNTY0OTI3LS4yODY5MjRMMi45Mzg3OTgtLjY2MDc5NVYuMDYwODYzTDIuOTczNTc2IC4wNzgyNTJDMy40MDgzMS0uMDk1NjQxIDMuNzIxMzE4LS4xOTEyODMgNC4xNjQ3NDYtLjMxMzAwOFYtLjQzNDczM1onLz4KPHBhdGggaWQ9J2cxLTExOCcgZD0nTTQuMTQ3MzU2LTMuOTEyNkgyLjkzODc5OFYtMy43ODIxOEMzLjIxNzAyNy0zLjc1NjA5NiAzLjM0NzQ0Ny0zLjY2OTE1IDMuMzQ3NDQ3LTMuNTAzOTUxQzMuMzQ3NDQ3LTMuNDE3MDA0IDMuMzMwMDU4LTMuMzMwMDU4IDMuMjk1Mjc5LTMuMjQzMTExTDIuNDM0NTA3LS45OTExOTJMMS41NDc2NTEtMy4yMTcwMjdDMS40OTU0ODMtMy4zMzg3NTIgMS40NjkzOTktMy40NjA0NzggMS40NjkzOTktMy41Mzg3M0MxLjQ2OTM5OS0zLjY5NTIzNCAxLjU2NTA0LTMuNzU2MDk2IDEuODY5MzUzLTMuNzgyMThWLTMuOTEyNkguMTY1MTk5Vi0zLjc4MjE4Qy40OTU1OTYtMy43NjQ3OTEgLjU1NjQ1OS0zLjY3Nzg0NCAuOTU2NDEzLTIuNzgyMjk0TDEuOTk5NzczLS4yODY5MjRDMi4wMTcxNjMtLjIzNDc1NiAyLjA0MzI0Ny0uMTczODkzIDIuMDY5MzMxLS4xMDQzMzZDMi4xMjE0OTkgLjA1MjE2OCAyLjE3MzY2NyAuMTIxNzI1IDIuMjI1ODM1IC4xMjE3MjVTMi4zMzg4NjYgLjAwODY5NSAyLjQ2OTI4Ni0uMzEzMDA4TDMuNTgyMjAzLTMuMTAzOTk2QzMuODM0MzQ4LTMuNjk1MjM0IDMuODg2NTE2LTMuNzU2MDk2IDQuMTQ3MzU2LTMuNzgyMThWLTMuOTEyNlonLz4KPHBhdGggaWQ9J2cxLTExOScgZD0nTTQuOTY0NjU1LTMuOTEyNlYtMy43ODIxOEM1LjI2MDI3NC0zLjcyMTMxOCA1LjM0NzIyLTMuNjYwNDU1IDUuMzQ3MjItMy41MTI2NDZDNS4zNDcyMi0zLjM4MjIyNiA1LjI5NTA1Mi0zLjE3MzU1NCA1LjE5OTQxMS0yLjkzODc5OEw0LjQxNjg5MS0xLjAwODU4MUwzLjY4NjUzOS0yLjk1NjE4N0MzLjUzODczLTMuMzU2MTQyIDMuNTM4NzMtMy4zNTYxNDIgMy41Mzg3My0zLjQ2OTE3MkMzLjUzODczLTMuNjYwNDU1IDMuNjM0MzcxLTMuNzIxMzE4IDQuMDQzMDItMy43ODIxOFYtMy45MTI2SDIuMjc4MDAzVi0zLjc4MjE4QzIuNTk5NzA2LTMuNzQ3NDAyIDIuNzA0MDQyLTMuNjUxNzYgMi44Nzc5MzUtMy4xODIyNDhDMi45Mzg3OTgtMy4wMTcwNSAyLjk5OTY2LTIuODUxODUxIDMuMDUxODI4LTIuNjk1MzQ3TDIuMjYwNjE0LS45NjUxMDhMMS4zOTk4NDEtMy4yMzQ0MTZDMS4zNjUwNjMtMy4zMjEzNjMgMS4zNDc2NzMtMy40MDgzMSAxLjM0NzY3My0zLjQ5NTI1NkMxLjM0NzY3My0zLjY3Nzg0NCAxLjQ1MjAwOS0zLjc0NzQwMiAxLjc0NzYyOC0zLjc4MjE4Vi0zLjkxMjZILjE4MjU4OFYtMy43ODIxOEMuMzgyNTY1LTMuNzY0NzkxIC40NTIxMjMtMy42Nzc4NDQgLjY0MzQwNS0zLjIzNDQxNkwxLjgxNzE4NS0uMjYwODRDMS45MjE1MjEgMCAxLjk5MTA3OSAuMTIxNzI1IDIuMDQzMjQ3IC4xMjE3MjVDMi4wODY3MiAuMTIxNzI1IDIuMTU2Mjc4IC4wMDg2OTUgMi4yNjA2MTQtLjIxNzM2N0wzLjIzNDQxNi0yLjMwNDA4N0w0LjAyNTYzMS0uMjUyMTQ1QzQuMTQ3MzU2IC4wNjk1NTcgNC4xODIxMzUgLjEyMTcyNSA0LjIzNDMwMyAuMTIxNzI1QzQuMjk1MTY2IC4xMjE3MjUgNC4zMzg2MzkgLjA0MzQ3MyA0LjQ3Nzc1NC0uMzA0MzEzTDUuNjc3NjE4LTMuMzEyNjY4QzUuODM0MTIyLTMuNjc3ODQ0IDUuODYwMjA2LTMuNzIxMzE4IDYuMDM0MDk5LTMuNzgyMThWLTMuOTEyNkg0Ljk2NDY1NVonLz4KPHBhdGggaWQ9J2cxLTEyMCcgZD0nTTIuNDE3MTE4IDBINC4xNjQ3NDZWLS4xMzA0MkMzLjg5NTIxMS0uMTMwNDIgMy43MjEzMTgtLjI2OTUzNSAzLjQ1MTc4My0uNjUyMUwyLjMzODg2Ni0yLjM1NjI1NUwzLjA2MDUyMy0zLjM5OTYxNUMzLjIyNTcyMi0zLjYzNDM3MSAzLjQ4NjU2Mi0zLjc3MzQ4NiAzLjc2NDc5MS0zLjc4MjE4Vi0zLjkxMjZIMi4zOTEwMzRWLTMuNzgyMThDMi42NTE4NzQtMy43NjQ3OTEgMi43Mzg4Mi0zLjcxMjYyMyAyLjczODgyLTMuNTkwODk4QzIuNzM4ODItMy40ODY1NjIgMi42MzQ0ODQtMy4yOTUyNzkgMi40MTcxMTgtMy4wMjU3NDRDMi4zNzM2NDQtMi45NzM1NzYgMi4yNjkzMDgtMi44MTcwNzIgMi4xNTYyNzgtMi42NDMxNzlMMi4wMzQ1NTItMi44MTcwNzJDMS43OTExMDEtMy4xODIyNDggMS42MzQ1OTctMy40Nzc4NjcgMS42MzQ1OTctMy41OTA4OThDMS42MzQ1OTctMy43MTI2MjMgMS43NDc2MjgtMy43NzM0ODYgMi4wMDg0NjgtMy43ODIxOFYtMy45MTI2SC4yMDg2NzJWLTMuNzgyMThILjI4NjkyNEMuNTQ3NzY0LTMuNzgyMTggLjY4Njg3OS0zLjY2OTE1IC45NTY0MTMtMy4yNjA1TDEuNzczNzEyLTIuMDA4NDY4TC43ODI1Mi0uNTczODQ4Qy41MjE2OC0uMjE3MzY3IC40MzQ3MzMtLjE1NjUwNCAuMTQ3ODA5LS4xMzA0MlYwSDEuNDA4NTM2Vi0uMTMwNDJDMS4xNjUwODUtLjEzMDQyIDEuMDYwNzQ5LS4xNzM4OTMgMS4wNjA3NDktLjI4NjkyNEMxLjA2MDc0OS0uMzM5MDkyIDEuMTIxNjEyLS40Njk1MTIgMS4yMzQ2NDMtLjY0MzQwNUwxLjkyMTUyMS0xLjcxMjg0OUwyLjcxMjczNi0uNDk1NTk2QzIuNzQ3NTE1LS40NDM0MjggMi43NjQ5MDQtLjM5MTI2IDIuNzY0OTA0LS4zMzkwOTJDMi43NjQ5MDQtLjE4MjU4OCAyLjcwNDA0Mi0uMTQ3ODA5IDIuNDE3MTE4LS4xMzA0MlYwWicvPgo8cGF0aCBpZD0nZzEtMTIxJyBkPSdNNC4xMjk5NjctMy45MTI2SDIuOTU2MTg3Vi0zLjc4MjE4QzMuMjM0NDE2LTMuNzgyMTggMy4zNzM1MzEtMy43MDM5MjggMy4zNzM1MzEtMy41NjQ4MTRDMy4zNzM1MzEtMy41MzAwMzUgMy4zNjQ4MzYtMy40Nzc4NjcgMy4zMzg3NTItMy40MTcwMDRMMi40OTUzNy0xLjAxNzI3NkwxLjQ5NTQ4My0zLjIxNzAyN0MxLjQ0MzMxNS0zLjMzODc1MiAxLjQwODUzNi0zLjQ1MTc4MyAxLjQwODUzNi0zLjU0NzQyNEMxLjQwODUzNi0zLjcwMzkyOCAxLjUzODk1Ni0zLjc2NDc5MSAxLjkxMjgyNy0zLjc4MjE4Vi0zLjkxMjZILjEyMTcyNVYtMy43OTA4NzVDLjM0Nzc4Ny0zLjc1NjA5NiAuNDk1NTk2LTMuNjYwNDU1IC41NjUxNTMtMy41MTI2NDZMMS41NTYzNDUtMS4zNzM3NTdMMS41ODI0MjktMS4zMDQyTDEuNzEyODQ5LTEuMDQzMzZDMS45NTYzLS42MDg2MjcgMi4wOTU0MTUtLjI5NTYxOSAyLjA5NTQxNS0uMTY1MTk5UzEuODk1NDM3IC41MTI5ODUgMS43NDc2MjggLjc3MzgyNUMxLjYyNTkwMyAuOTk5ODg3IDEuNDM0NjIgMS4xNjUwODUgMS4zMTI4OTUgMS4xNjUwODVDMS4yNjA3MjcgMS4xNjUwODUgMS4xODI0NzUgMS4xNDc2OTYgMS4wOTU1MjggMS4xMDQyMjNDLjkzMDMyOSAxLjA0MzM2IC43ODI1MiAxLjAwODU4MSAuNjM0NzExIDEuMDA4NTgxQy40MzQ3MzMgMS4wMDg1ODEgLjI2MDg0IDEuMTgyNDc1IC4yNjA4NCAxLjM5MTE0N0MuMjYwODQgMS42NzgwNzEgLjUzOTA2OSAxLjg5NTQzNyAuOTA0MjQ1IDEuODk1NDM3QzEuNDg2Nzg4IDEuODk1NDM3IDEuOTA0MTMyIDEuNDA4NTM2IDIuMzczNjQ0IC4xNTY1MDRMMy43MTI2MjMtMy4zOTA5MkMzLjgyNTY1NC0zLjY2OTE1IDMuOTIxMjk1LTMuNzU2MDk2IDQuMTI5OTY3LTMuNzgyMThWLTMuOTEyNlonLz4KPHVzZSBpZD0nZzQ2LTQzJyB4bGluazpocmVmPScjZzQ1LTQzJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzMzMzMzKScvPgo8dXNlIGlkPSdnNDYtNDgnIHhsaW5rOmhyZWY9JyNnNDUtNDgnIHRyYW5zZm9ybT0nc2NhbGUoMS4zMzMzMzMpJy8+Cjx1c2UgaWQ9J2c0Ni00OScgeGxpbms6aHJlZj0nI2c0NS00OScgdHJhbnNmb3JtPSdzY2FsZSgxLjMzMzMzMyknLz4KPHBhdGggaWQ9J2c0Mi0wJyBkPSdNNy44Nzg0NTYtMi43NDk2ODlDOC4wODE2OTQtMi43NDk2ODkgOC4yOTY4ODctMi43NDk2ODkgOC4yOTY4ODctMi45ODg3OTJTOC4wODE2OTQtMy4yMjc4OTUgNy44Nzg0NTYtMy4yMjc4OTVIMS40MTA3MUMxLjIwNzQ3Mi0zLjIyNzg5NSAuOTkyMjc5LTMuMjI3ODk1IC45OTIyNzktMi45ODg3OTJTMS4yMDc0NzItMi43NDk2ODkgMS40MTA3MS0yLjc0OTY4OUg3Ljg3ODQ1NlonLz4KPHBhdGggaWQ9J2c0Mi0yJyBkPSdNNC42NTA1Ni0zLjMyMzUzN0wyLjI1OTUyNy01LjcwMjYxNUMyLjExNjA2NS01Ljg0NjA3NyAyLjA5MjE1NC01Ljg2OTk4OCAxLjk5NjUxMy01Ljg2OTk4OEMxLjg3Njk2MS01Ljg2OTk4OCAxLjc1NzQxLTUuNzYyMzkxIDEuNzU3NDEtNS42MzA4ODRDMS43NTc0MS01LjU0NzE5OCAxLjc4MTMyLTUuNTIzMjg4IDEuOTEyODI3LTUuMzkxNzgxTDQuMzAzODYxLTIuOTg4NzkyTDEuOTEyODI3LS41ODU4MDNDMS43ODEzMi0uNDU0Mjk2IDEuNzU3NDEtLjQzMDM4NiAxLjc1NzQxLS4zNDY3QzEuNzU3NDEtLjIxNTE5MyAxLjg3Njk2MS0uMTA3NTk3IDEuOTk2NTEzLS4xMDc1OTdDMi4wOTIxNTQtLjEwNzU5NyAyLjExNjA2NS0uMTMxNTA3IDIuMjU5NTI3LS4yNzQ5NjlMNC42Mzg2MDUtMi42NTQwNDdMNy4xMTMzMjUtLjE3OTMyOEM3LjEzNzIzNS0uMTY3MzcyIDcuMjIwOTIyLS4xMDc1OTcgNy4yOTI2NTMtLjEwNzU5N0M3LjQzNjExNS0uMTA3NTk3IDcuNTMxNzU2LS4yMTUxOTMgNy41MzE3NTYtLjM0NjdDNy41MzE3NTYtLjM3MDYxIDcuNTMxNzU2LS40MTg0MzEgNy40OTU4OS0uNDc4MjA3QzcuNDgzOTM1LS41MDIxMTcgNS41ODMwNjQtMi4zNzkwNzggNC45ODUzMDUtMi45ODg3OTJMNy4xNzMxMDEtNS4xNzY1ODhDNy4yMzI4NzctNS4yNDgzMTkgNy40MTIyMDQtNS40MDM3MzYgNy40NzE5OC01LjQ3NTQ2N0M3LjQ4MzkzNS01LjQ5OTM3NyA3LjUzMTc1Ni01LjU0NzE5OCA3LjUzMTc1Ni01LjYzMDg4NEM3LjUzMTc1Ni01Ljc2MjM5MSA3LjQzNjExNS01Ljg2OTk4OCA3LjI5MjY1My01Ljg2OTk4OEM3LjE5NzAxMS01Ljg2OTk4OCA3LjE0OTE5MS01LjgyMjE2NyA3LjAxNzY4NC01LjY5MDY2TDQuNjUwNTYtMy4zMjM1MzdaJy8+CjxwYXRoIGlkPSdnNDItMjAnIGQ9J004LjA2OTczOC03LjEwMTM3QzguMjAxMjQ1LTcuMTYxMTQ2IDguMjk2ODg3LTcuMjIwOTIyIDguMjk2ODg3LTcuMzY0Mzg0QzguMjk2ODg3LTcuNDk1ODkgOC4yMDEyNDUtNy42MDM0ODcgOC4wNTc3ODMtNy42MDM0ODdDNy45OTgwMDctNy42MDM0ODcgNy44OTA0MTEtNy41NTU2NjYgNy44NDI1OS03LjUzMTc1NkwxLjIzMTM4Mi00LjQxMTQ1N0MxLjAyODE0NC00LjMxNTgxNiAuOTkyMjc5LTQuMjMyMTMgLjk5MjI3OS00LjEzNjQ4OEMuOTkyMjc5LTQuMDI4ODkyIDEuMDY0MDEtMy45NDUyMDUgMS4yMzEzODItMy44NzM0NzRMNy44NDI1OS0uNzY1MTMxQzcuOTk4MDA3LS42ODE0NDUgOC4wMjE5MTgtLjY4MTQ0NSA4LjA1Nzc4My0uNjgxNDQ1QzguMTg5MjktLjY4MTQ0NSA4LjI5Njg4Ny0uNzg5MDQxIDguMjk2ODg3LS45MjA1NDhDOC4yOTY4ODctMS4wMjgxNDQgOC4yNDkwNjYtMS4wOTk4NzUgOC4wNDU4MjgtMS4xOTU1MTdMMS43OTMyNzUtNC4xMzY0ODhMOC4wNjk3MzgtNy4xMDEzN1pNNy44Nzg0NTYgMS42Mzc4NThDOC4wODE2OTQgMS42Mzc4NTggOC4yOTY4ODcgMS42Mzc4NTggOC4yOTY4ODcgMS4zOTg3NTVTOC4wNDU4MjggMS4xNTk2NTEgNy44NjY1MDEgMS4xNTk2NTFIMS40MjI2NjVDMS4yNDMzMzcgMS4xNTk2NTEgLjk5MjI3OSAxLjE1OTY1MSAuOTkyMjc5IDEuMzk4NzU1UzEuMjA3NDcyIDEuNjM3ODU4IDEuNDEwNzEgMS42Mzc4NThINy44Nzg0NTZaJy8+CjxwYXRoIGlkPSdnNDItMzInIGQ9J00xMC44NTUyOTMtMi43NDk2ODlDMTEuMDcwNDg2LTIuNzQ5Njg5IDExLjI4NTY3OS0yLjc0OTY4OSAxMS4yODU2NzktMi45ODg3OTJTMTEuMDcwNDg2LTMuMjI3ODk1IDEwLjg1NTI5My0zLjIyNzg5NUgxLjk3MjYwM0MyLjYzMDEzNy0zLjczMDAxMiAyLjk1MjkyNy00LjIyMDE3NCAzLjA0ODU2OC00LjM3NTU5MkMzLjU4NjU1LTUuMjAwNDk4IDMuNjgyMTkyLTUuOTUzNjc0IDMuNjgyMTkyLTUuOTY1NjI5QzMuNjgyMTkyLTYuMTA5MDkxIDMuNTM4NzMtNi4xMDkwOTEgMy40NDMwODgtNi4xMDkwOTFDMy4yMzk4NTEtNi4xMDkwOTEgMy4yMjc4OTUtNi4wODUxODEgMy4xODAwNzUtNS44Njk5ODhDMi45MDUxMDYtNC42OTgzODEgMi4xOTk3NTEtMy43MDYxMDIgLjg0ODgxNy0zLjE0NDIwOUMuNzE3MzEtMy4wOTYzODkgLjY2OTQ4OS0zLjA3MjQ3OCAuNjY5NDg5LTIuOTg4NzkyUy43MjkyNjUtMi44ODExOTYgLjg0ODgxNy0yLjgzMzM3NUMyLjA5MjE1NC0yLjMxOTMwMyAyLjg5MzE1MS0xLjM4NjggMy4xOTIwMy0uMDQ3ODIxQzMuMjI3ODk1IC4wOTU2NDEgMy4yMzk4NTEgLjEzMTUwNyAzLjQ0MzA4OCAuMTMxNTA3QzMuNTM4NzMgLjEzMTUwNyAzLjY4MjE5MiAuMTMxNTA3IDMuNjgyMTkyLS4wMTE5NTVDMy42ODIxOTItLjAzNTg2NiAzLjU3NDU5NS0uNzg5MDQxIDMuMDcyNDc4LTEuNTkwMDM3QzIuODMzMzc1LTEuOTQ4NjkyIDIuNDg2Njc1LTIuMzY3MTIzIDEuOTcyNjAzLTIuNzQ5Njg5SDEwLjg1NTI5M1onLz4KPHBhdGggaWQ9J2c0Mi00OScgZD0nTTYuMDczMjI1LTMuMjM5ODUxQzUuNDI3NjQ2LTQuMDUyODAyIDUuMjg0MTg0LTQuMjMyMTMgNC45MTM1NzQtNC41MzEwMDlDNC4yNDQwODUtNS4wNjg5OTEgMy41NzQ1OTUtNS4yODQxODQgMi45NjQ4ODItNS4yODQxODRDMS41NjYxMjctNS4yODQxODQgLjY1NzUzNC0zLjk2OTExNiAuNjU3NTM0LTIuNTcwMzYxQy42NTc1MzQtMS4xOTU1MTcgMS41NDIyMTcgLjEzMTUwNyAyLjkxNzA2MSAuMTMxNTA3UzUuMjg0MTg0LS45NTY0MTMgNS44Njk5ODgtMS45MTI4MjdDNi41MTU1NjctMS4wOTk4NzUgNi42NTkwMjktLjkyMDU0OCA3LjAyOTYzOS0uNjIxNjY5QzcuNjk5MTI4LS4wODM2ODYgOC4zNjg2MTggLjEzMTUwNyA4Ljk3ODMzMSAuMTMxNTA3QzEwLjM3NzA4NiAuMTMxNTA3IDExLjI4NTY3OS0xLjE4MzU2MiAxMS4yODU2NzktMi41ODIzMTZDMTEuMjg1Njc5LTMuOTU3MTYxIDEwLjQwMDk5Ni01LjI4NDE4NCA5LjAyNjE1Mi01LjI4NDE4NFM2LjY1OTAyOS00LjE5NjI2NCA2LjA3MzIyNS0zLjIzOTg1MVpNNi4zODQwNi0yLjgzMzM3NUM2Ljg3NDIyMi0zLjY5NDE0NyA3Ljc1ODkwNC00LjkwMTYxOSA5LjEwOTgzOC00LjkwMTYxOUMxMC4zNzcwODYtNC45MDE2MTkgMTEuMDIyNjY1LTMuNjU4MjgxIDExLjAyMjY2NS0yLjU4MjMxNkMxMS4wMjI2NjUtMS40MTA3MSAxMC4yMjE2NjktLjQ0MjM0MSA5LjE2OTYxNC0uNDQyMzQxQzguNDc2MjE0LS40NDIzNDEgNy45MzgyMzItLjk0NDQ1OCA3LjY4NzE3My0xLjE5NTUxN0M3LjM4ODI5NC0xLjUxODMwNiA3LjExMzMyNS0xLjg4ODkxNyA2LjM4NDA2LTIuODMzMzc1Wk01LjU1OTE1My0yLjMxOTMwM0M1LjA2ODk5MS0xLjQ1ODUzMSA0LjE4NDMwOS0uMjUxMDU5IDIuODMzMzc1LS4yNTEwNTlDMS41NjYxMjctLjI1MTA1OSAuOTIwNTQ4LTEuNDk0Mzk2IC45MjA1NDgtMi41NzAzNjFDLjkyMDU0OC0zLjc0MTk2OCAxLjcyMTU0NC00LjcxMDMzNiAyLjc3MzU5OS00LjcxMDMzNkMzLjQ2Njk5OS00LjcxMDMzNiA0LjAwNDk4MS00LjIwODIxOSA0LjI1NjA0LTMuOTU3MTYxQzQuNTU0OTE5LTMuNjM0MzcxIDQuODI5ODg4LTMuMjYzNzYxIDUuNTU5MTUzLTIuMzE5MzAzWicvPgo8dXNlIGlkPSdnNTItMicgeGxpbms6aHJlZj0nI2cxLTInIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi00MCcgeGxpbms6aHJlZj0nI2cxLTQwJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzY5ODYzKScvPgo8dXNlIGlkPSdnNTItNDEnIHhsaW5rOmhyZWY9JyNnMS00MScgdHJhbnNmb3JtPSdzY2FsZSgxLjM2OTg2MyknLz4KPHVzZSBpZD0nZzUyLTQ0JyB4bGluazpocmVmPScjZzEtNDQnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi00NicgeGxpbms6aHJlZj0nI2cxLTQ2JyB0cmFuc2Zvcm09J3NjYWxlKDEuMzY5ODYzKScvPgo8dXNlIGlkPSdnNTItNDcnIHhsaW5rOmhyZWY9JyNnMS00NycgdHJhbnNmb3JtPSdzY2FsZSgxLjM2OTg2MyknLz4KPHVzZSBpZD0nZzUyLTQ4JyB4bGluazpocmVmPScjZzEtNDgnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi00OScgeGxpbms6aHJlZj0nI2cxLTQ5JyB0cmFuc2Zvcm09J3NjYWxlKDEuMzY5ODYzKScvPgo8dXNlIGlkPSdnNTItNTAnIHhsaW5rOmhyZWY9JyNnMS01MCcgdHJhbnNmb3JtPSdzY2FsZSgxLjM2OTg2MyknLz4KPHVzZSBpZD0nZzUyLTUyJyB4bGluazpocmVmPScjZzEtNTInIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi01MycgeGxpbms6aHJlZj0nI2cxLTUzJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzY5ODYzKScvPgo8dXNlIGlkPSdnNTItNTgnIHhsaW5rOmhyZWY9JyNnMS01OCcgdHJhbnNmb3JtPSdzY2FsZSgxLjM2OTg2MyknLz4KPHVzZSBpZD0nZzUyLTY1JyB4bGluazpocmVmPScjZzEtNjUnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi02NicgeGxpbms6aHJlZj0nI2cxLTY2JyB0cmFuc2Zvcm09J3NjYWxlKDEuMzY5ODYzKScvPgo8dXNlIGlkPSdnNTItNjgnIHhsaW5rOmhyZWY9JyNnMS02OCcgdHJhbnNmb3JtPSdzY2FsZSgxLjM2OTg2MyknLz4KPHVzZSBpZD0nZzUyLTcwJyB4bGluazpocmVmPScjZzEtNzAnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi03MycgeGxpbms6aHJlZj0nI2cxLTczJyB0cmFuc2Zvcm09J3NjYWxlKDEuMzY5ODYzKScvPgo8dXNlIGlkPSdnNTItNzcnIHhsaW5rOmhyZWY9JyNnMS03NycgdHJhbnNmb3JtPSdzY2FsZSgxLjM2OTg2MyknLz4KPHVzZSBpZD0nZzUyLTgzJyB4bGluazpocmVmPScjZzEtODMnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi05NycgeGxpbms6aHJlZj0nI2cxLTk3JyB0cmFuc2Zvcm09J3NjYWxlKDEuMzY5ODYzKScvPgo8dXNlIGlkPSdnNTItOTgnIHhsaW5rOmhyZWY9JyNnMS05OCcgdHJhbnNmb3JtPSdzY2FsZSgxLjM2OTg2MyknLz4KPHVzZSBpZD0nZzUyLTk5JyB4bGluazpocmVmPScjZzEtOTknIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMDAnIHhsaW5rOmhyZWY9JyNnMS0xMDAnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMDEnIHhsaW5rOmhyZWY9JyNnMS0xMDEnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMDInIHhsaW5rOmhyZWY9JyNnMS0xMDInIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMDMnIHhsaW5rOmhyZWY9JyNnMS0xMDMnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMDQnIHhsaW5rOmhyZWY9JyNnMS0xMDQnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMDUnIHhsaW5rOmhyZWY9JyNnMS0xMDUnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMDgnIHhsaW5rOmhyZWY9JyNnMS0xMDgnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMDknIHhsaW5rOmhyZWY9JyNnMS0xMDknIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMTAnIHhsaW5rOmhyZWY9JyNnMS0xMTAnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMTEnIHhsaW5rOmhyZWY9JyNnMS0xMTEnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMTInIHhsaW5rOmhyZWY9JyNnMS0xMTInIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMTQnIHhsaW5rOmhyZWY9JyNnMS0xMTQnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMTUnIHhsaW5rOmhyZWY9JyNnMS0xMTUnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMTYnIHhsaW5rOmhyZWY9JyNnMS0xMTYnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMTcnIHhsaW5rOmhyZWY9JyNnMS0xMTcnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMTgnIHhsaW5rOmhyZWY9JyNnMS0xMTgnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMTknIHhsaW5rOmhyZWY9JyNnMS0xMTknIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMjAnIHhsaW5rOmhyZWY9JyNnMS0xMjAnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+Cjx1c2UgaWQ9J2c1Mi0xMjEnIHhsaW5rOmhyZWY9JyNnMS0xMjEnIHRyYW5zZm9ybT0nc2NhbGUoMS4zNjk4NjMpJy8+CjxwYXRoIGlkPSdnNDEtMTEyJyBkPSdNMy4yODM2ODYgNi43MzQ3NDVMMS43NzczMzUgMy42NDIzNDFDMS43Mzc0ODQgMy41NTQ2NyAxLjcwNTYwNCAzLjUxNDgxOSAxLjY0MTg0MyAzLjUxNDgxOUMxLjYwOTk2MyAzLjUxNDgxOSAxLjU5NDAyMiAzLjUyMjc5IDEuNTE0MzIxIDMuNTc4NThMLjcwMTM3IDQuMTQ0NDU4Qy41ODk3ODggNC4yMTYxODkgLjU4OTc4OCA0LjI1NjA0IC41ODk3ODggNC4yNzk5NUMuNTg5Nzg4IDQuMzI3NzcxIC42Mjk2MzkgNC4zOTE1MzIgLjcwMTM3IDQuMzkxNTMyQy43MzMyNSA0LjM5MTUzMiAuNzQ5MTkxIDQuMzkxNTMyIC44NDQ4MzIgNC4zMTE4MzFDLjk0ODQ0MyA0LjI0ODA3IDEuMTA3ODQ2IDQuMTI4NTE4IDEuMjQzMzM3IDQuMDMyODc3TDIuOTE3MDYxIDcuNDY3OTk1QzIuOTg4NzkyIDcuNjExNDU3IDMuMDIwNjcyIDcuNjExNDU3IDMuMTAwMzc0IDcuNjExNDU3QzMuMjM1ODY2IDcuNjExNDU3IDMuMjU5Nzc2IDcuNTcxNjA2IDMuMzIzNTM3IDcuNDQ0MDg1TDcuMTczMTAxLS4wMjM5MUM3LjIzNjg2Mi0uMTM1NDkyIDcuMjM2ODYyLS4xNTE0MzIgNy4yMzY4NjItLjE4MzMxM0M3LjIzNjg2Mi0uMjc4OTU0IDcuMTU3MTYxLS4zNjY2MjUgNy4wNTM1NDktLjM2NjYyNVM2LjkxODA1Ny0uMzAyODY0IDYuODYyMjY3LS4xOTkyNTNMMy4yODM2ODYgNi43MzQ3NDVaJy8+CjwvZGVmcz4KPGcgaWQ9J3BhZ2UxJyB0cmFuc2Zvcm09J21hdHJpeCgxLjQgMCAwIDEuNCAwIDApJz4KPHVzZSB4PScwJyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnOC02NScvPgo8dXNlIHg9JzguNjMxNTk5JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnOC0xMDgnLz4KPHVzZSB4PScxMS45NTUwMicgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzgtMTAzJy8+Cjx1c2UgeD0nMTcuOTMyNjA0JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnOC0xMTEnLz4KPHVzZSB4PScyMy45MTAxODgnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c4LTExNCcvPgo8dXNlIHg9JzI5LjIxODIxNycgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzgtMTA1Jy8+Cjx1c2UgeD0nMzIuNTQxNjM4JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnOC0xMTYnLz4KPHVzZSB4PSczNi41MjI2NjYnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c4LTEwNCcvPgo8dXNlIHg9JzQzLjE2OTY2OCcgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzgtMTA5Jy8+Cjx1c2UgeD0nNTYuMTE3MDcyJyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnOC00OScvPgo8dXNlIHg9JzY1LjA4MzQ0OCcgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTcwJy8+Cjx1c2UgeD0nNzEuNzMwNDUnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PSc3NS4wNTM4NzEnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PSc4MS4wMzE0NTUnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PSc4OS45OTc4MzEnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi04MycvPgo8dXNlIHg9Jzk2LjY0NDgzNCcgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9Jzk5Ljk2ODI1NScgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMTA1LjI3NjI4NCcgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTk4Jy8+Cjx1c2UgeD0nMTExLjI1Mzg2OCcgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzExNC41NzcyODknIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxMjIuODc0MTExJyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItNzMnLz4KPHVzZSB4PScxMjYuODU1MTM4JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMTMyLjgzMjcyMicgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzEzNi4xNTYxNDMnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxNDEuNDY0MTczJyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTE0Jy8+Cjx1c2UgeD0nMTQ1LjQ0NTInIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMTgnLz4KPHVzZSB4PScxNTEuMTIzOTAyJyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PScxNTYuNDMxOTMxJyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTA4Jy8+Cjx1c2UgeD0nMTYyLjc0NDE0NCcgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTExMScvPgo8dXNlIHg9JzE2OC43MjE3MjgnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMDInLz4KPHVzZSB4PScxNzUuNjkxNTQ4JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItNzcnLz4KPHVzZSB4PScxODYuMzE5NTc4JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItNjUnLz4KPHVzZSB4PScxOTQuOTUxMTc2JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItNjgnLz4KPHVzZSB4PScyMDMuNTgyNzc1JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItNjgnLz4KPHVzZSB4PScyMTUuMjAzMTY2JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTE5Jy8+Cjx1c2UgeD0nMjIzLjgzNDc2NCcgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzIyNy4xNTgxODYnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScyMzAuNDgxNjA3JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTA0Jy8+Cjx1c2UgeD0nMjM5LjQ0Nzk4MycgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTc3Jy8+Cjx1c2UgeD0nMjUwLjA3NjAxMycgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzI1My4zOTk0MzQnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScyNTkuMzc3MDE4JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjYyLjcwMDQzOScgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTEwOScvPgo8dXNlIHg9JzI3Mi4wMDE0NDUnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMTcnLz4KPHVzZSB4PScyNzcuOTc5MDI5JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTA5Jy8+Cjx1c2UgeD0nMjkwLjI2ODgyNicgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTgzJy8+Cjx1c2UgeD0nMjk2LjkxNTgyOCcgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzMwMC4yMzkyNDknIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzMwNS41NDcyNzknIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PSczMTEuNTI0ODYzJyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nMzE3LjUwMjQ0NycgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMzIyLjgxMDQ3NicgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzMyNi43OTE1MDMnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PSczMzUuNzU3ODgnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi02OCcvPgo8dXNlIHg9JzM0NC4zODk0NzgnIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PSczNDkuMzk4NjI1JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTE4Jy8+Cjx1c2UgeD0nMzU1LjM3NjIwOScgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzM1OC42OTk2MycgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMzY0LjAwNzY2JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMzY3LjMzMTA4MScgeT0nODUuOTI2NDc5JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzM3MC42NTQ1MDInIHk9Jzg1LjkyNjQ3OScgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PSczNzYuNjMyMDg2JyB5PSc4NS45MjY0NzknIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzEwOC43NTI2MjQnIHhsaW5rOmhyZWY9JyNnMTktNDknLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzEwOC43NTI2MjQnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PScyMC4zMjM3NDknIHk9JzEwOC43NTI2MjQnIHhsaW5rOmhyZWY9JyNnOC03MycvPgo8dXNlIHg9JzI0Ljk3NDE5NScgeT0nMTA4Ljc1MjYyNCcgeGxpbms6aHJlZj0nI2c4LTExMCcvPgo8dXNlIHg9JzMxLjYyMTE5NycgeT0nMTA4Ljc1MjYyNCcgeGxpbms6aHJlZj0nI2c4LTExMicvPgo8dXNlIHg9JzM4LjI2ODE5OScgeT0nMTA4Ljc1MjYyNCcgeGxpbms6aHJlZj0nI2c4LTExNycvPgo8dXNlIHg9JzQ0LjkxNTIwMScgeT0nMTA4Ljc1MjYyNCcgeGxpbms6aHJlZj0nI2c4LTExNicvPgo8dXNlIHg9JzQ4Ljg5NjIyOScgeT0nMTA4Ljc1MjYyNCcgeGxpbms6aHJlZj0nI2c4LTU4Jy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnMTktNTAnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSc1MC4yMTE2NycgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c0NC03NicvPgo8dXNlIHg9JzU4LjE3NjE3NicgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c0NC0xMDQnLz4KPHVzZSB4PSc2NC45MTQ3MzEnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItNTgnLz4KPHVzZSB4PSc3MS45NDQyMjUnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nNzcuOTIxODA5JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzgxLjkwMjgzNycgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PSc4Ny44ODA0MjEnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nOTMuMTg4NDUnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTE0Jy8+Cjx1c2UgeD0nOTcuMTY5NDc4JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzEwMi40Nzc1MDcnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nMTExLjQ0Mzg4MycgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PScxMTQuNzY3MzA0JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzExOC4wOTA3MjUnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTE1Jy8+Cjx1c2UgeD0nMTIyLjc0MTE3MScgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScxMjkuMDUzMzg0JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTExMScvPgo8dXNlIHg9JzEzNS4wMzA5NjgnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTAyJy8+Cjx1c2UgeD0nMTQyLjAwMDc4OCcgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c0NC0xMDQnLz4KPHVzZSB4PScxNTEuNzI4MTM1JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTExOCcvPgo8dXNlIHg9JzE1Ny40MDY4MzcnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PScxNjIuNzE0ODY2JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzE2Ni4wMzgyODcnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTE3Jy8+Cjx1c2UgeD0nMTcyLjAxNTg3MScgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxNzcuMzIzOScgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PScxODQuOTYzMTM4JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTExOScvPgo8dXNlIHg9JzE5My41OTQ3MzcnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTA0Jy8+Cjx1c2UgeD0nMTk5LjU3MjMyMScgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScyMDQuODgwMzUnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTE0Jy8+Cjx1c2UgeD0nMjA4Ljg2MTM3NycgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScyMTcuMTU4MTk5JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzIyMC40ODE2MicgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PScyMjkuNDQ3OTk2JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTInLz4KPHVzZSB4PScyMzYuMDk0OTk4JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzI0Mi4wNzI1ODInIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nMjUxLjAzODk1OCcgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzI1OS4zMzU3NzknIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTE1Jy8+Cjx1c2UgeD0nMjYzLjk4NjIyNScgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScyNjcuMzA5NjQ2JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMjcyLjYxNzY3NScgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi05OCcvPgo8dXNlIHg9JzI3OC41OTUyNicgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PScyODEuOTE4NjgxJyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzI5MC4yMTU1MDInIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjkzLjUzODkyMycgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScyOTkuNTE2NTA3JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzMwMi44Mzk5MjknIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMzA4LjE0Nzk1OCcgeT0nMTIzLjE5ODQ1MicgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PSczMTIuMTI4OTg1JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTExOCcvPgo8dXNlIHg9JzMxNy44MDc2ODcnIHk9JzEyMy4xOTg0NTInIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PSczMjMuMTE1NzE2JyB5PScxMjMuMTk4NDUyJyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnMTktNTEnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2cxOS01OCcvPgo8dXNlIHg9JzUwLjIxMTY3JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNDQtNzYnLz4KPHVzZSB4PSc1OC4xNzYxNzYnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c0NC0xMDknLz4KPHVzZSB4PSc2OC40MTU0NDMnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c0NC05NycvPgo8dXNlIHg9Jzc0LjU2MDM4NycgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzgwLjY0MzA4JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nODYuNzI1NzczJyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItNTgnLz4KPHVzZSB4PSc5My43NTUyNjcnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PSc5OS43MzI4NTEnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PScxMDMuNzEzODc5JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nMTA5LjY5MTQ2MycgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzExNC45OTk0OTInIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PScxMTguOTgwNTInIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxMjQuMjg4NTQ5JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nMTMzLjI1NDkyNScgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzEzNi41NzgzNDYnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScxMzkuOTAxNzY4JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTE1Jy8+Cjx1c2UgeD0nMTQ0LjU1MjIxMycgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzE1MC44NjQ0MjcnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PScxNTYuODQyMDExJyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTAyJy8+Cjx1c2UgeD0nMTYzLjgxMTgzJyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItNzcnLz4KPHVzZSB4PScxNzQuNDM5ODYnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi02NScvPgo8dXNlIHg9JzE4My4wNzE0NTknIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi02OCcvPgo8dXNlIHg9JzE5MS43MDMwNTcnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi02OCcvPgo8dXNlIHg9JzIwMy4zMjM0NDgnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PScyMDcuMzA0NDc1JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjEyLjYxMjUwNScgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzIxNy4yNjI5NScgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzUyLTExNycvPgo8dXNlIHg9JzIyMy4yNDA1MzQnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PScyMjYuNTYzOTU2JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMjI5Ljg4NzM3NycgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzIzNy41MjY2MTUnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzI0Mi44MzQ2NDQnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PScyNDcuNDg1MDg5JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTE1Jy8+Cjx1c2UgeD0nMjUyLjEzNTUzNScgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzUyLTExMScvPgo8dXNlIHg9JzI1OC4xMTMxMTknIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi05OScvPgo8dXNlIHg9JzI2My40MjExNDgnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScyNjYuNzQ0NTY5JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PScyNzIuMDUyNTk5JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMjc1LjM3NjAyJyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjgwLjY4NDA0OScgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzUyLTEwMCcvPgo8dXNlIHg9JzI4OS42NTA0MjUnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScyOTIuOTczODQ2JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMzAxLjk0MDIyMicgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzMwNS4yNjM2NDQnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDQnLz4KPHVzZSB4PSczMTEuMjQxMjI4JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMzE5LjUzODA0OScgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzQ0LTEwNCcvPgo8dXNlIHg9JzMyOS4yNjUzOTYnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PSczMzIuNTg4ODE3JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMzQxLjU1NTE5MycgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzQ0LTEwNCcvPgo8cmVjdCB4PSczNDkuMDExMDI5JyB5PScxMzcuMjQ1NzgxJyBoZWlnaHQ9Jy4zOTg1JyB3aWR0aD0nMy41ODY1ODcnLz4KPHVzZSB4PSczNTIuNTk3NjE2JyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNDQtMTA4Jy8+Cjx1c2UgeD0nMzU2LjM0NzQyNCcgeT0nMTM3LjY0NDI4JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzM2MC4zNDA4NTcnIHk9JzEzNy42NDQyOCcgeGxpbms6aHJlZj0nI2c0NC0xMTUnLz4KPHVzZSB4PSczNjUuODU0ODYyJyB5PScxMzcuNjQ0MjgnIHhsaW5rOmhyZWY9JyNnNDQtMTE2Jy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnMTktNTInLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSc1MC4yMTE2NycgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PSc1Ny4xOTkyNzUnIHk9JzE1My44ODMzNzEnIHhsaW5rOmhyZWY9JyNnNDYtNDgnLz4KPHVzZSB4PSc2MS42ODI0NzknIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItNDQnLz4KPHVzZSB4PSc2Ny42NjAwNjMnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nNzQuNjQ3NjY4JyB5PScxNTMuODgzMzcxJyB4bGluazpocmVmPScjZzQ2LTQ5Jy8+Cjx1c2UgeD0nNzkuMTMwODcyJyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTU4Jy8+Cjx1c2UgeD0nODYuMTYwMzY2JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzkyLjEzNzk1JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTExNycvPgo8dXNlIHg9Jzk4LjExNTUzNCcgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDknLz4KPHVzZSB4PScxMDcuNDE2NTM5JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTk4Jy8+Cjx1c2UgeD0nMTEzLjM5NDEyMycgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxMTguNzAyMTUyJyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzEyNS42NzE5NzInIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMTMxLjY0OTU1NicgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDInLz4KPHVzZSB4PScxMzguNjE5Mzc2JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzE0MS45NDI3OTcnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMTQ3LjkyMDM4MScgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PScxNTMuODk3OTY1JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzE1Ni45MjI1MDQnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTE4Jy8+Cjx1c2UgeD0nMTYyLjkwMDA4OCcgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScxNjYuMjIzNTA5JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTEwMCcvPgo8dXNlIHg9JzE3Mi4yMDEwOTMnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTE3Jy8+Cjx1c2UgeD0nMTc4LjE3ODY3NycgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzE4My40ODY3MDcnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTA4Jy8+Cjx1c2UgeD0nMTg2LjgxMDEyOCcgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PScxOTQuNDQ5MzY2JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzE5Ny43NzI3ODcnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMjA2LjczOTE2MycgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c0NC03MScvPgo8dXNlIHg9JzIxNS45NzI3ODYnIHk9JzE1My44ODMzNzEnIHhsaW5rOmhyZWY9JyNnNDYtNDgnLz4KPHVzZSB4PScyMjMuNDQ0NzgyJyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMjI4Ljc1MjgxMScgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScyMzQuNzMwMzk1JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTEwMCcvPgo8dXNlIHg9JzI0My42OTY3NzEnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNDQtNzEnLz4KPHVzZSB4PScyNTIuOTMwMzk0JyB5PScxNTMuODgzMzcxJyB4bGluazpocmVmPScjZzQ2LTQ5Jy8+Cjx1c2UgeD0nMjYwLjQwMjM5JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzI2NC4zODM0MTcnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjY5LjY5MTQ0NicgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PScyNzQuMzQxODkyJyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTExMicvPgo8dXNlIHg9JzI4MC4zMTk0NzYnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjg1LjYyNzUwNScgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi05OScvPgo8dXNlIHg9JzI5MC45MzU1MzQnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMjk0LjI1ODk1NicgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScyOTcuMjgzNDk1JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTExOCcvPgo8dXNlIHg9JzMwMy4wODE4NjUnIHk9JzE1Mi4wOTAxMDgnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMzA4LjM4OTg5NCcgeT0nMTUyLjA5MDEwOCcgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PSczMTEuNzEzMzE1JyB5PScxNTIuMDkwMTA4JyB4bGluazpocmVmPScjZzUyLTEyMScvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzE5LTUzJy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nNTEuNDkxOTMzJyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUzLTkxJy8+Cjx1c2UgeD0nNTQuNzQzNTk1JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzYxLjczMTInIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNDQtOTgnLz4KPHVzZSB4PSc2Ni43MDgzMDYnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNDQtODAnLz4KPHVzZSB4PSc3NS44Nzk0MDQnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNDQtMTExJy8+Cjx1c2UgeD0nODEuNTA2ODQyJyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9Jzg1LjUwMDI3NCcgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PSc5Mi40ODc4OCcgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c0NC0xMTYnLz4KPHVzZSB4PSc5Ni43MTUwMzknIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNDQtMTE1Jy8+Cjx1c2UgeD0nMTAyLjIyOTA0NScgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c0NC03NycvPgo8dXNlIHg9JzExNC44MDI2NTInIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nMTE4Ljc5NjA4NCcgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScxMzAuMjg5OTM5JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUzLTYxJy8+Cjx1c2UgeD0nMTQzLjkwMDg0JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUzLTUzJy8+Cjx1c2UgeD0nMTQ5Ljc1MzgzJyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUzLTQ4Jy8+Cjx1c2UgeD0nMTU1LjYwNjgyJyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUzLTkzJy8+Cjx1c2UgeD0nMTU4Ljg1ODQ4MScgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi01OCcvPgo8dXNlIHg9JzE2Ny4xNjgyMzknIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nMTczLjE0NTgyMycgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxNzguNDUzODUzJyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzE4My4xMDQyOTgnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMTg2LjQyNzcxOScgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PScxOTAuNDA4NzQ3JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzE5NS43MTY3NzYnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nMjA1LjMyMzI2OScgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMDknLz4KPHVzZSB4PScyMTQuNjI0Mjc0JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzIxNy45NDc2OTYnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMjIzLjkyNTI4JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzIyNy4yNDg3MDEnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTA5Jy8+Cjx1c2UgeD0nMjM2LjU0OTcwNicgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMTcnLz4KPHVzZSB4PScyNDIuNTI3MjknIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTA5Jy8+Cjx1c2UgeD0nMjU1LjQ1NzIxOScgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScyNjEuNDM0ODA0JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTExNycvPgo8dXNlIHg9JzI2Ny40MTIzODgnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTA5Jy8+Cjx1c2UgeD0nMjc2LjcxMzM5MycgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi05OCcvPgo8dXNlIHg9JzI4Mi42OTA5NzcnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjg3Ljk5OTAwNicgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PScyOTUuNjA4OTU4JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTExMScvPgo8dXNlIHg9JzMwMS41ODY1NDInIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTAyJy8+Cjx1c2UgeD0nMzA5LjE5NjQ5MycgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PSczMTMuODQ2OTM5JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzMxNy4xNzAzNicgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzMyMi40NzgzODknIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItOTgnLz4KPHVzZSB4PSczMjguNDU1OTczJyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzMzMS43NzkzOTQnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMzQwLjcxNjM0OCcgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi03NycvPgo8dXNlIHg9JzM1MS4zNDQzNzcnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItNjUnLz4KPHVzZSB4PSczNTkuOTc1OTc2JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTY4Jy8+Cjx1c2UgeD0nMzY4LjYwNzU3NScgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi02OCcvPgo8dXNlIHg9JzM4MC44Njc0NTknIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTE0Jy8+Cjx1c2UgeD0nMzg0Ljg0ODQ4NicgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PSczOTAuMTU2NTE1JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzM5NC44MDY5NjEnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTE3Jy8+Cjx1c2UgeD0nNDAwLjc4NDU0NScgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PSc0MDQuMTA3OTY2JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzQwNy40MzEzODgnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTE1Jy8+Cjx1c2UgeD0nNDE1LjcxMDc1NycgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi00MCcvPgo8dXNlIHg9JzQxOS42OTE3ODUnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nNDI1LjY2OTM2OScgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PSc0MzAuOTc3Mzk4JyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTEwMicvPgo8dXNlIHg9JzQzNC44Mzg4OTQnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PSc0NDAuMTQ2OTIzJyB5PScxNjYuNTM1OTM2JyB4bGluazpocmVmPScjZzUyLTExNycvPgo8dXNlIHg9JzQ0Ni4xMjQ1MDcnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItMTA4Jy8+Cjx1c2UgeD0nNDQ5LjQ0NzkyOCcgeT0nMTY2LjUzNTkzNicgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PSc0NTIuNzcxMzUnIHk9JzE2Ni41MzU5MzYnIHhsaW5rOmhyZWY9JyNnNTItNTgnLz4KPHVzZSB4PScyMC4zMjM3NDknIHk9JzE4MC45ODE3NjUnIHhsaW5rOmhyZWY9JyNnNTItNTMnLz4KPHVzZSB4PScyNi4zMDEzMzMnIHk9JzE4MC45ODE3NjUnIHhsaW5rOmhyZWY9JyNnNTItNDgnLz4KPHVzZSB4PSczMi4yNzg5MTcnIHk9JzE4MC45ODE3NjUnIHhsaW5rOmhyZWY9JyNnNTItNDEnLz4KPHVzZSB4PSc2LjU5NTMzOScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2cxOS01NCcvPgo8dXNlIHg9JzExLjU3NjY1OScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2cxOS01OCcvPgo8dXNlIHg9JzUwLjA3MjA0MScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1My05MScvPgo8dXNlIHg9JzUzLjMyMzcwMicgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c0NC0xMTInLz4KPHVzZSB4PSc1OS4xOTg4NDYnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nNjQuNjI0Mjg2JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzQ0LTExNCcvPgo8dXNlIHg9JzcwLjIyNDc1OScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c0NC05OScvPgo8dXNlIHg9Jzc1LjI2Mjc0OCcgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c0NC0xMDEnLz4KPHVzZSB4PSc4MC42ODgxODgnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nODcuNjc1NzkzJyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9Jzk1LjIyMzc4MicgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1My02MScvPgo8dXNlIHg9JzEwNy42NDkyNjMnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTMtNDgnLz4KPHVzZSB4PScxMTMuNTAyMjU0JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzQ0LTU4Jy8+Cjx1c2UgeD0nMTE2Ljc1MzkxNScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1My01MicvPgo8dXNlIHg9JzEyMi42MDY5MDUnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTMtNTMnLz4KPHVzZSB4PScxMjguNDU5ODk1JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUzLTkzJy8+Cjx1c2UgeD0nMTMxLjcxMTU1NycgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi01OCcvPgo8dXNlIHg9JzEzOC43MDYxMzInIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTEyJy8+Cjx1c2UgeD0nMTQ0LjY4MzcxNicgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxNDkuOTkxNzQ1JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzE1My45NzI3NzMnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItOTknLz4KPHVzZSB4PScxNTkuMjgwODAyJyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzE2NC41ODg4MzEnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMTcwLjU2NjQxNScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScxNzYuODA4ODIyJyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTEwMicvPgo8dXNlIHg9JzE4MC43ODk4NScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PScxODYuNzY3NDM0JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzE5My42Njc0MzInIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMTk2Ljk5MDg1MycgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDQnLz4KPHVzZSB4PScyMDIuOTY4NDM3JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzIxMS4xOTU0MzYnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTA5Jy8+Cjx1c2UgeD0nMjIwLjQ5NjQ0MicgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScyMjMuODE5ODYzJyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzIyOS43OTc0NDcnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjMzLjEyMDg2OCcgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDknLz4KPHVzZSB4PScyNDIuNDIxODczJyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMjQ3LjcyOTkwMycgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PScyNTMuOTcyMzA5JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzI1Ny4yOTU3MzEnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjYyLjYwMzc2JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzI2OC41ODEzNDQnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTAzJy8+Cjx1c2UgeD0nMjc0LjU1ODkyOCcgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScyNzcuODgyMzQ5JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTEwNCcvPgo8dXNlIHg9JzI4Ni43Nzg5MDMnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMjkyLjc1NjQ4OCcgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDInLz4KPHVzZSB4PScyOTkuNjU2NDg1JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzMwMi45Nzk5MDcnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTA0Jy8+Cjx1c2UgeD0nMzA4Ljk1NzQ5MScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PSczMTcuMTg0NTA1JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzMyMS44MzQ5NTEnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMzI1LjE1ODM3MicgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzMzMC40NjY0MDEnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItOTgnLz4KPHVzZSB4PSczMzYuNDQzOTg1JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzMzOS43Njc0MDcnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMzQ3Ljk5NDQwNicgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PSczNTEuMzE3ODI3JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzM1Ny4yOTU0MTEnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMzYwLjYxODgzMycgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PSczNjUuOTI2ODYyJyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzM2OS45MDc4ODknIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTE4Jy8+Cjx1c2UgeD0nMzc1LjU4NjU5MScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzM4MC44OTQ2MicgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PSczODcuMTM3MDEyJyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTQwJy8+Cjx1c2UgeD0nMzkxLjExODAzOScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PSczOTcuMDk1NjIzJyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzQwMi40MDM2NTMnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTAyJy8+Cjx1c2UgeD0nNDA2LjI2NTE0OScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzQxMS41NzMxNzgnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItMTE3Jy8+Cjx1c2UgeD0nNDE3LjU1MDc2MicgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PSc0MjAuODc0MTgzJyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzQyNC4xOTc2MDQnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItNTgnLz4KPHVzZSB4PSc0MzEuMTkyMTk1JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTQ4Jy8+Cjx1c2UgeD0nNDM3LjE2OTc3OScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi00NicvPgo8dXNlIHg9JzQ0MC4xNTg1NzEnIHk9JzE5NS40Mjc1OTMnIHhsaW5rOmhyZWY9JyNnNTItNTInLz4KPHVzZSB4PSc0NDYuMTM2MTU1JyB5PScxOTUuNDI3NTkzJyB4bGluazpocmVmPScjZzUyLTUzJy8+Cjx1c2UgeD0nNDUyLjExMzczOScgeT0nMTk1LjQyNzU5MycgeGxpbms6aHJlZj0nI2c1Mi00MScvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PScyMjQuMzE5MjQ5JyB4bGluazpocmVmPScjZzE5LTU1Jy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PScyMjQuMzE5MjQ5JyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nMjAuMzIzNzQ5JyB5PScyMjQuMzE5MjQ5JyB4bGluazpocmVmPScjZzgtNzknLz4KPHVzZSB4PScyOS42MjQ3NTUnIHk9JzIyNC4zMTkyNDknIHhsaW5rOmhyZWY9JyNnOC0xMTcnLz4KPHVzZSB4PSczNi4yNzE3NTcnIHk9JzIyNC4zMTkyNDknIHhsaW5rOmhyZWY9JyNnOC0xMTYnLz4KPHVzZSB4PSc0MC4yNTI3ODQnIHk9JzIyNC4zMTkyNDknIHhsaW5rOmhyZWY9JyNnOC0xMTInLz4KPHVzZSB4PSc0Ni44OTk3ODcnIHk9JzIyNC4zMTkyNDknIHhsaW5rOmhyZWY9JyNnOC0xMTcnLz4KPHVzZSB4PSc1My41NDY3ODknIHk9JzIyNC4zMTkyNDknIHhsaW5rOmhyZWY9JyNnOC0xMTYnLz4KPHVzZSB4PSc1Ny41Mjc4MTYnIHk9JzIyNC4zMTkyNDknIHhsaW5rOmhyZWY9JyNnOC01OCcvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzE5LTU2Jy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nNTAuMjExNjcnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nNTQuMjA1MTAyJyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzYxLjE5MjcwOCcgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c0NC0xMDAnLz4KPHVzZSB4PSc2Ny4yNzU0MDEnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nNzIuNzAwODQxJyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzQ0LTEyMCcvPgo8dXNlIHg9Jzc5LjM1MjkyOCcgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c0NC0xMDEnLz4KPHVzZSB4PSc4NC43NzgzNjgnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNDQtMTE1Jy8+Cjx1c2UgeD0nOTAuMjkyMzc0JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTU4Jy8+Cjx1c2UgeD0nOTcuMzIxODY4JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzEwMC42NDUyODknIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTE3Jy8+Cjx1c2UgeD0nMTA2LjYyMjg3MycgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMTInLz4KPHVzZSB4PScxMTIuNjAwNDU3JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzExNS45MjM4NzgnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMTI0LjIyMDcnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTMtNDAnLz4KPHVzZSB4PScxMjguNzczMDI1JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzEzMi43NjY0NTgnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNDQtNTknLz4KPHVzZSB4PScxMzguMDEwNjE2JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzQ0LTEwNicvPgo8dXNlIHg9JzE0My41MjYxMTInIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTMtNDEnLz4KPHVzZSB4PScxNTEuMDY3MjMnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMTU3LjA0NDgxNCcgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMDInLz4KPHVzZSB4PScxNjQuMDE0NjMzJyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzE2OC42NjUwNzknIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMTcxLjk4ODUnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PScxNzcuMjk2NTI5JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzE4MS4yNzc1NTcnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMTg3LjU4OTc3JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMTkyLjg5Nzc5OScgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScxOTguODc1Mzg0JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTEwMCcvPgo8dXNlIHg9JzIwNy44NDE3NicgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScyMTMuMTQ5Nzg5JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzIxOS4xMjczNzMnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nMjI4LjA5Mzc0OScgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScyMzEuNDE3MTcnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMjM3LjM5NDc1NCcgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PScyNDMuMzcyMzM4JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzI0OC41MDExNTQnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTIwJy8+Cjx1c2UgeD0nMjU0LjI5OTUyNCcgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScyNTkuNjA3NTUzJyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzI2Ny4yNDY3OTEnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMjczLjIyNDM3NScgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMDInLz4KPHVzZSB4PScyODAuMTk0MTk0JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzI4My41MTc2MTYnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTA0Jy8+Cjx1c2UgeD0nMjg5LjQ5NTInIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjk3Ljc5MjAyMScgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PSczMDIuNDQyNDY3JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzMwNS43NjU4ODgnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PSczMTEuMDczOTE3JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTk4Jy8+Cjx1c2UgeD0nMzE3LjA1MTUwMScgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PSczMjAuMzc0OTIyJyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzMyOC42NzE3NDQnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMzMxLjk5NTE2NScgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PSczMzcuOTcyNzQ5JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzM0MS4yOTYxNycgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PSczNDYuNjA0MTk5JyB5PScyMzguNzY1MDc3JyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzM1MC41ODUyMjcnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTE4Jy8+Cjx1c2UgeD0nMzU2LjI2MzkyOScgeT0nMjM4Ljc2NTA3NycgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzM2MS41NzE5NTgnIHk9JzIzOC43NjUwNzcnIHhsaW5rOmhyZWY9JyNnNTItMTA4Jy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnMTktNTcnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSc1MC4yMTE2NycgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c0NC0xMTUnLz4KPHVzZSB4PSc1NS43MjU2NzUnIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNDQtMTE2Jy8+Cjx1c2UgeD0nNTkuOTUyODM1JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzY2LjAzNTUyOCcgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c0NC03NycvPgo8dXNlIHg9Jzc4LjYwOTEzNScgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c0NC0xMDUnLz4KPHVzZSB4PSc4Mi42MDI1NjcnIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nODkuNTkwMTczJyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTU4Jy8+Cjx1c2UgeD0nOTYuNjE5NjY3JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwOScvPgo8dXNlIHg9JzEwNS45MjA2NzInIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMTA5LjI0NDA5NCcgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScxMTUuMjIxNjc4JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzExOC41NDUwOTknIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTA5Jy8+Cjx1c2UgeD0nMTI3Ljg0NjEwNCcgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTcnLz4KPHVzZSB4PScxMzMuODIzNjg4JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwOScvPgo8dXNlIHg9JzE0Ni4xMTM0ODYnIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTE1Jy8+Cjx1c2UgeD0nMTUwLjc2MzkzMScgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScxNTQuMDg3MzUzJyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMTU5LjM5NTM4MicgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScxNjUuMzcyOTY2JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwMCcvPgo8dXNlIHg9JzE3MS4zNTA1NScgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzE3Ni42NTg1NzknIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTE0Jy8+Cjx1c2UgeD0nMTgwLjYzOTYwNycgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PScxODkuNjA1OTgzJyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwMCcvPgo8dXNlIHg9JzE5NS41ODM1NjcnIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjAwLjU5MjcxNCcgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTgnLz4KPHVzZSB4PScyMDYuNTcwMjk4JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzIwOS44OTM3MTknIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PScyMTUuMjAxNzQ4JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzIxOC41MjUxNjknIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjIxLjg0ODU5MScgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PScyMjcuODI2MTc1JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzIzNi43OTI1NTEnIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTAyJy8+Cjx1c2UgeD0nMjQwLjc3MzU3OCcgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PScyNDYuNzUxMTYyJyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTExNycvPgo8dXNlIHg9JzI1Mi43Mjg3NDcnIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMjU4LjcwNjMzMScgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PScyNjcuNjcyNzA3JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzI3MC45OTYxMjgnIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMjc5Ljk2MjUwNCcgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScyODMuMjg1OTI1JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwNCcvPgo8dXNlIHg9JzI4OS4yNjM1MDknIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjkyLjU4NjkzMScgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PSczMDAuMjI2MTY4JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzMwMy41NDk1OScgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PSczMDkuNTI3MTc0JyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzMxMi44NTA1OTUnIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMzE4LjE1ODYyNCcgeT0nMjUzLjIxMDkwNScgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PSczMjIuMTM5NjUyJyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTExOCcvPgo8dXNlIHg9JzMyNy44MTgzNTMnIHk9JzI1My4yMTA5MDUnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PSczMzMuMTI2MzgzJyB5PScyNTMuMjEwOTA1JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzE5LTQ5Jy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnMTktNDgnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSc1MC4yMTE2NycgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c0NC05NycvPgo8dXNlIHg9JzU2LjM1NjYxNCcgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c0NC0xMTgnLz4KPHVzZSB4PSc2Mi40NDQ4MzMnIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nNjcuODcwMjczJyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzQ0LTExNCcvPgo8dXNlIHg9JzczLjQ3MDc0NicgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c0NC05NycvPgo8dXNlIHg9Jzc5LjYxNTY5MScgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c0NC0xMDMnLz4KPHVzZSB4PSc4NS42NDk5NDcnIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nOTEuMDc1Mzg3JyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTU4Jy8+Cjx1c2UgeD0nOTguMTA0ODgxJyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMTAzLjE3Mzg2MicgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi0xMTgnLz4KPHVzZSB4PScxMDguOTcyMjMzJyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzExNC4yODAyNjInIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNTItMTE0Jy8+Cjx1c2UgeD0nMTE4LjI2MTI4OScgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzEyMy41NjkzMTgnIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNTItMTAzJy8+Cjx1c2UgeD0nMTI5LjU0NjkwMycgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxMzcuODQzNzI0JyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTc3Jy8+Cjx1c2UgeD0nMTQ4LjQ3MTc1MycgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi02NScvPgo8dXNlIHg9JzE1Ny4xMDMzNTInIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNTItNjgnLz4KPHVzZSB4PScxNjUuNzM0OTUxJyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTY4Jy8+Cjx1c2UgeD0nMTc3LjM1NTM0MScgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi0xMTknLz4KPHVzZSB4PScxODUuOTg2OTQnIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMTg5LjMxMDM2MScgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScxOTIuNjMzNzgzJyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTEwNCcvPgo8dXNlIHg9JzE5OC42MTEzNjcnIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjAxLjkzNDc4OCcgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScyMTAuOTAxMTY0JyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzIxNC4yMjQ1ODUnIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNTItMTA0Jy8+Cjx1c2UgeD0nMjIwLjIwMjE2OScgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScyMjMuNTI1NTkxJyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzIzMS4xNjQ4MjgnIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjM0LjQ4ODI0OScgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScyNDAuNDY1ODM0JyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzI0My43ODkyNTUnIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjQ5LjA5NzI4NCcgeT0nMjY3LjY1NjczMycgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PScyNTMuMDc4MzEyJyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTExOCcvPgo8dXNlIHg9JzI1OC43NTcwMTMnIHk9JzI2Ny42NTY3MzMnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PScyNjQuMDY1MDQyJyB5PScyNjcuNjU2NzMzJyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PScyOTYuNTQ4MzknIHhsaW5rOmhyZWY9JyNnMTktNDknLz4KPHVzZSB4PSc2LjU5NTMzOScgeT0nMjk2LjU0ODM5JyB4bGluazpocmVmPScjZzE5LTQ5Jy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PScyOTYuNTQ4MzknIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PScyMC4zMjM3NDknIHk9JzI5Ni41NDgzOScgeGxpbms6aHJlZj0nI2c4LTczJy8+Cjx1c2UgeD0nMjQuOTc0MTk1JyB5PScyOTYuNTQ4MzknIHhsaW5rOmhyZWY9JyNnOC0xMTAnLz4KPHVzZSB4PSczMS42MjExOTcnIHk9JzI5Ni41NDgzOScgeGxpbms6aHJlZj0nI2c4LTEwNScvPgo8dXNlIHg9JzM0Ljk0NDYxOCcgeT0nMjk2LjU0ODM5JyB4bGluazpocmVmPScjZzgtMTE2Jy8+Cjx1c2UgeD0nMzguOTI1NjQ2JyB5PScyOTYuNTQ4MzknIHhsaW5rOmhyZWY9JyNnOC0xMDUnLz4KPHVzZSB4PSc0Mi4yNDkwNjcnIHk9JzI5Ni41NDgzOScgeGxpbms6aHJlZj0nI2c4LTk3Jy8+Cjx1c2UgeD0nNDguMjI2NjUxJyB5PScyOTYuNTQ4MzknIHhsaW5rOmhyZWY9JyNnOC0xMDgnLz4KPHVzZSB4PSc1MS41NTAwNzMnIHk9JzI5Ni41NDgzOScgeGxpbms6aHJlZj0nI2c4LTEwNScvPgo8dXNlIHg9JzU0Ljg3MzQ5NCcgeT0nMjk2LjU0ODM5JyB4bGluazpocmVmPScjZzgtMTIyJy8+Cjx1c2UgeD0nNjAuMTgxNTIzJyB5PScyOTYuNTQ4MzknIHhsaW5rOmhyZWY9JyNnOC05NycvPgo8dXNlIHg9JzY2LjE1OTEwNycgeT0nMjk2LjU0ODM5JyB4bGluazpocmVmPScjZzgtMTE2Jy8+Cjx1c2UgeD0nNzAuMTQwMTM1JyB5PScyOTYuNTQ4MzknIHhsaW5rOmhyZWY9JyNnOC0xMDUnLz4KPHVzZSB4PSc3My40NjM1NTYnIHk9JzI5Ni41NDgzOScgeGxpbms6aHJlZj0nI2c4LTExMScvPgo8dXNlIHg9Jzc5LjQ0MTE0JyB5PScyOTYuNTQ4MzknIHhsaW5rOmhyZWY9JyNnOC0xMTAnLz4KPHVzZSB4PScxLjYxNDAxOScgeT0nMzEwLjk5NDIxOCcgeGxpbms6aHJlZj0nI2cxOS00OScvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PSczMTAuOTk0MjE4JyB4bGluazpocmVmPScjZzE5LTUwJy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PSczMTAuOTk0MjE4JyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nMjAuMzIzNzQ5JyB5PSczMTAuOTk0MjE4JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzI0LjMxNzE4MicgeT0nMzEwLjk5NDIxOCcgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PSczMS4zMDQ3ODcnIHk9JzMxMC45OTQyMTgnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nMzcuMzg3NDgnIHk9JzMxMC45OTQyMTgnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nNDIuODEyOTInIHk9JzMxMC45OTQyMTgnIHhsaW5rOmhyZWY9JyNnNDQtMTIwJy8+Cjx1c2UgeD0nNDkuNDY1MDA3JyB5PSczMTAuOTk0MjE4JyB4bGluazpocmVmPScjZzQ0LTEwMScvPgo8dXNlIHg9JzU0Ljg5MDQ0OCcgeT0nMzEwLjk5NDIxOCcgeGxpbms6aHJlZj0nI2c0NC0xMTUnLz4KPHVzZSB4PSc2My43MjUyODMnIHk9JzMxMC45OTQyMTgnIHhsaW5rOmhyZWY9JyNnNDItMzInLz4KPHVzZSB4PSc3OS4wMDEzMTQnIHk9JzMxMC45OTQyMTgnIHhsaW5rOmhyZWY9JyNnNTMtNDAnLz4KPHVzZSB4PSc4My41NTM2NCcgeT0nMzEwLjk5NDIxOCcgeGxpbms6aHJlZj0nI2c1My00OCcvPgo8dXNlIHg9Jzg5LjQwNjYzJyB5PSczMTAuOTk0MjE4JyB4bGluazpocmVmPScjZzQ0LTU5Jy8+Cjx1c2UgeD0nOTQuNjUwNzg5JyB5PSczMTAuOTk0MjE4JyB4bGluazpocmVmPScjZzUzLTQ4Jy8+Cjx1c2UgeD0nMTAwLjUwMzc3OScgeT0nMzEwLjk5NDIxOCcgeGxpbms6aHJlZj0nI2c1My00MScvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSczMjUuNDQwMDQ2JyB4bGluazpocmVmPScjZzE5LTQ5Jy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzMyNS40NDAwNDYnIHhsaW5rOmhyZWY9JyNnMTktNTEnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzMyNS40NDAwNDYnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PScyMC4zMjM3NDknIHk9JzMyNS40NDAwNDYnIHhsaW5rOmhyZWY9JyNnNDQtMTE1Jy8+Cjx1c2UgeD0nMjUuODM3NzU1JyB5PSczMjUuNDQwMDQ2JyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzMwLjA2NDkxNScgeT0nMzI1LjQ0MDA0NicgeGxpbms6aHJlZj0nI2c0NC0xMDAnLz4KPHVzZSB4PSczNi4xNDc2MDgnIHk9JzMyNS40NDAwNDYnIHhsaW5rOmhyZWY9JyNnNDQtNzcnLz4KPHVzZSB4PSc0OC43MjEyMTUnIHk9JzMyNS40NDAwNDYnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nNTIuNzE0NjQ3JyB5PSczMjUuNDQwMDQ2JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzYzLjAyMzA4MicgeT0nMzI1LjQ0MDA0NicgeGxpbms6aHJlZj0nI2c0Mi0zMicvPgo8dXNlIHg9Jzc4LjI5OTExNCcgeT0nMzI1LjQ0MDA0NicgeGxpbms6aHJlZj0nI2c0Mi00OScvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSczMzkuODg1ODc0JyB4bGluazpocmVmPScjZzE5LTQ5Jy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzMzOS44ODU4NzQnIHhsaW5rOmhyZWY9JyNnMTktNTInLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzMzOS44ODU4NzQnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PScyMC4zMjM3NDknIHk9JzMzOS44ODU4NzQnIHhsaW5rOmhyZWY9JyNnNDQtMTA0Jy8+Cjx1c2UgeD0nMjcuMDYyMzA0JyB5PSczMzkuODg1ODc0JyB4bGluazpocmVmPScjZzQ0LTc3Jy8+Cjx1c2UgeD0nMzkuNjM1OTExJyB5PSczMzkuODg1ODc0JyB4bGluazpocmVmPScjZzQ0LTk3Jy8+Cjx1c2UgeD0nNDUuNzgwODU2JyB5PSczMzkuODg1ODc0JyB4bGluazpocmVmPScjZzQ0LTEyMCcvPgo8dXNlIHg9JzU1Ljc1Mzc3MicgeT0nMzM5Ljg4NTg3NCcgeGxpbms6aHJlZj0nI2c0Mi0zMicvPgo8dXNlIHg9JzcxLjAyOTgwNCcgeT0nMzM5Ljg4NTg3NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PSc3NC4zNTMyMjUnIHk9JzMzOS44ODU4NzQnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PSc3OS42NjEyNTQnIHk9JzMzOS44ODU4NzQnIHhsaW5rOmhyZWY9JyNnNTItMTE1Jy8+Cjx1c2UgeD0nODQuMzExNycgeT0nMzM5Ljg4NTg3NCcgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PSc5MC42MjM5MTMnIHk9JzMzOS44ODU4NzQnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nOTUuOTMxOTQyJyB5PSczMzkuODg1ODc0JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9Jzk5LjI1NTM2MycgeT0nMzM5Ljg4NTg3NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxMDQuNTYzMzkzJyB5PSczMzkuODg1ODc0JyB4bGluazpocmVmPScjZzUyLTEwOScvPgo8dXNlIHg9JzExMy44NjQzOTgnIHk9JzMzOS44ODU4NzQnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMTE5LjE3MjQyNycgeT0nMzM5Ljg4NTg3NCcgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScxMjUuMTUwMDExJyB5PSczMzkuODg1ODc0JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzEzMS40NjIyMjQnIHk9JzMzOS44ODU4NzQnIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMTM3LjQzOTgwOScgeT0nMzM5Ljg4NTg3NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDInLz4KPHVzZSB4PScxNDQuNDA5NTUyJyB5PSczMzkuODg1ODc0JyB4bGluazpocmVmPScjZzQ0LTc2Jy8+Cjx1c2UgeD0nMTUyLjM3NDA1OScgeT0nMzM5Ljg4NTg3NCcgeGxpbms6aHJlZj0nI2c0NC0xMDQnLz4KPHVzZSB4PScxLjYxNDAxOScgeT0nMzU4LjcyMzg3NycgeGxpbms6aHJlZj0nI2cxOS00OScvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PSczNTguNzIzODc3JyB4bGluazpocmVmPScjZzE5LTUzJy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PSczNTguNzIzODc3JyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nMjAuMzIzNzQ5JyB5PSczNTguNzIzODc3JyB4bGluazpocmVmPScjZzQ0LTExMScvPgo8dXNlIHg9JzI1Ljk1MTE4NycgeT0nMzU4LjcyMzg3NycgeGxpbms6aHJlZj0nI2c0NC0xMTQnLz4KPHVzZSB4PSczMS41NTE2NicgeT0nMzU4LjcyMzg3NycgeGxpbms6aHJlZj0nI2c0NC0xMDAnLz4KPHVzZSB4PSczNy42MzQzNTMnIHk9JzM1OC43MjM4NzcnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nNDMuMDU5NzkzJyB5PSczNTguNzIzODc3JyB4bGluazpocmVmPScjZzQ0LTExNCcvPgo8dXNlIHg9JzUxLjk4MTA5NicgeT0nMzU4LjcyMzg3NycgeGxpbms6aHJlZj0nI2c0Mi0zMicvPgo8dXNlIHg9JzY3LjI1NzEyOCcgeT0nMzQ1LjQ1MzUyNycgeGxpbms6aHJlZj0nI2c0MC0xNicvPgo8dXNlIHg9Jzc1LjU5MjU1NCcgeT0nMzQ3LjQwNjM0OCcgeGxpbms6aHJlZj0nI2c0MS0xMTInLz4KPHJlY3QgeD0nODIuNjQ5NTI1JyB5PSczNDcuMDQ3NjkyJyBoZWlnaHQ9Jy4zNTg2NTYnIHdpZHRoPSc4LjYyNTEyNicvPgo8dXNlIHg9JzgyLjY0OTUyNScgeT0nMzUyLjU5ODU0NycgeGxpbms6aHJlZj0nI2c0My0xMTAnLz4KPHVzZSB4PSc4Ny43ODc3MjgnIHk9JzM1My43MDU0OTUnIHhsaW5rOmhyZWY9JyNnNDUtNDgnLz4KPHVzZSB4PSc5MS4yNzQ2NTInIHk9JzM1Mi41OTg1NDcnIHhsaW5rOmhyZWY9JyNnNDYtNDMnLz4KPHVzZSB4PSc5Ny40NzM2NScgeT0nMzQ3LjQwNjM0OCcgeGxpbms6aHJlZj0nI2c0MS0xMTInLz4KPHJlY3QgeD0nMTA0LjUzMDYyMScgeT0nMzQ3LjA0NzY5MicgaGVpZ2h0PScuMzU4NjU2JyB3aWR0aD0nOC42MjUxMjYnLz4KPHVzZSB4PScxMDQuNTMwNjIxJyB5PSczNTIuNTk4NTQ3JyB4bGluazpocmVmPScjZzQzLTExMCcvPgo8dXNlIHg9JzEwOS42Njg4MjQnIHk9JzM1My43MDU0OTUnIHhsaW5rOmhyZWY9JyNnNDUtNDknLz4KPHJlY3QgeD0nNzUuNTkyNTU0JyB5PSczNTUuNDk1OTkyJyBoZWlnaHQ9Jy40NzgxODcnIHdpZHRoPSczNy41NjMxOTQnLz4KPHVzZSB4PSc4Mi4yMjA1NDYnIHk9JzM1Ny42NTQzMScgeGxpbms6aHJlZj0nI2c0MS0xMTInLz4KPHJlY3QgeD0nODkuMjc3NTE4JyB5PSczNTcuMjk1NjU1JyBoZWlnaHQ9Jy4zNTg2NTYnIHdpZHRoPScxNy4yNTAyNTMnLz4KPHVzZSB4PSc4OS4yNzc1MTgnIHk9JzM2Mi44NDY1MDknIHhsaW5rOmhyZWY9JyNnNDMtMTEwJy8+Cjx1c2UgeD0nOTQuNDE1NzInIHk9JzM2My45NTM0NTgnIHhsaW5rOmhyZWY9JyNnNDUtNDgnLz4KPHVzZSB4PSc5Ny45MDI2NDQnIHk9JzM2Mi44NDY1MDknIHhsaW5rOmhyZWY9JyNnNDMtMTEwJy8+Cjx1c2UgeD0nMTAzLjA0MDg0NycgeT0nMzYzLjk1MzQ1OCcgeGxpbms6aHJlZj0nI2c0NS00OScvPgo8dXNlIHg9JzExNC4zNTEyNjInIHk9JzM0NS40NTM1MjcnIHhsaW5rOmhyZWY9JyNnNDAtMTcnLz4KPHVzZSB4PScxMjIuNjg2Njg4JyB5PSczNDQuODcxNzQnIHhsaW5rOmhyZWY9JyNnNDUtNTAnLz4KPHJlY3QgeD0nMTIyLjY4NjY4OCcgeT0nMzQ1Ljk1ODMxNycgaGVpZ2h0PScuMzU4NjU2JyB3aWR0aD0nMi45ODg3OTInLz4KPHVzZSB4PScxMjIuNjg2Njg4JyB5PSczNTEuMjU1Nzc0JyB4bGluazpocmVmPScjZzQ1LTUxJy8+Cjx1c2UgeD0nMS42MTQwMTknIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2cxOS00OScvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PSczNzUuNzkzMjknIHhsaW5rOmhyZWY9JyNnMTktNTQnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2cxOS01OCcvPgo8dXNlIHg9JzIwLjMyMzc0OScgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzI0LjMxNzE4MicgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzMxLjMwNDc4NycgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzM1LjUzMTk0NycgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTEwMScvPgo8dXNlIHg9JzQwLjk1NzM4NycgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTExNCcvPgo8dXNlIHg9JzQ2LjU1Nzg2JyB5PSczNzUuNzkzMjknIHhsaW5rOmhyZWY9JyNnNDQtMTE4Jy8+Cjx1c2UgeD0nNTIuNjQ2MDc5JyB5PSczNzUuNzkzMjknIHhsaW5rOmhyZWY9JyNnNDQtOTcnLz4KPHVzZSB4PSc1OC43OTEwMjQnIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC0xMDgnLz4KPHVzZSB4PSc2Mi41NDA4MzInIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC03NicvPgo8dXNlIHg9JzcwLjUwNTMzOCcgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTEwMScvPgo8dXNlIHg9Jzc1LjkzMDc3OScgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzgyLjkxODM4NCcgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTEwMycvPgo8dXNlIHg9Jzg4Ljk1MjY0MScgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzkzLjE3OTgnIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC0xMDQnLz4KPHVzZSB4PSc5OS45MTgzNTUnIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC03NycvPgo8dXNlIHg9JzExMi40OTE5NjInIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC0xMDUnLz4KPHVzZSB4PScxMTYuNDg1Mzk0JyB5PSczNzUuNzkzMjknIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nMTI2Ljc5MzgyOScgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQyLTMyJy8+Cjx1c2UgeD0nMTQyLjA2OTg2MScgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTExMScvPgo8dXNlIHg9JzE0Ny42OTcyOTknIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC0xMTQnLz4KPHVzZSB4PScxNTMuMjk3NzcyJyB5PSczNzUuNzkzMjknIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nMTU5LjM4MDQ2NScgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTEwMScvPgo8dXNlIHg9JzE2NC44MDU5MDUnIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC0xMTQnLz4KPHVzZSB4PScxNzMuMDYzMDQyJyB5PSczNzUuNzkzMjknIHhsaW5rOmhyZWY9JyNnNDItMicvPgo8dXNlIHg9JzE4NS4wMTgyMDMnIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC0xMTInLz4KPHVzZSB4PScxOTAuODkzMzQ2JyB5PSczNzUuNzkzMjknIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nMTk2LjMxODc4NicgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTExNCcvPgo8dXNlIHg9JzIwMS45MTkyNTknIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC05OScvPgo8dXNlIHg9JzIwNi45NTcyNDgnIHk9JzM3NS43OTMyOScgeGxpbms6aHJlZj0nI2c0NC0xMDEnLz4KPHVzZSB4PScyMTIuMzgyNjg4JyB5PSczNzUuNzkzMjknIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nMjE5LjM3MDI5NCcgeT0nMzc1Ljc5MzI5JyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzE5LTQ5Jy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnMTktNTUnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PScyMC4zMjM3NDknIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC04MycvPgo8dXNlIHg9JzI2Ljk3MDc1MScgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTEwMScvPgo8dXNlIHg9JzMyLjI3ODc4MScgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTk3Jy8+Cjx1c2UgeD0nMzguMjU2MzY1JyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtMTE0Jy8+Cjx1c2UgeD0nNDMuMzQ5MjczJyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtOTknLz4KPHVzZSB4PSc0OC42NTczMDMnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMDQnLz4KPHVzZSB4PSc1OC4yOTMwOTcnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMTEnLz4KPHVzZSB4PSc2NC4yNzA2ODEnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMDInLz4KPHVzZSB4PSc3MS4yNDA1JyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtMTE2Jy8+Cjx1c2UgeD0nNzUuMjIxNTI4JyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtMTA0Jy8+Cjx1c2UgeD0nODEuODY4NTMnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMDEnLz4KPHVzZSB4PSc5MC4xNjUzNTEnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMTEnLz4KPHVzZSB4PSc5Ni4xNDI5MzUnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMTInLz4KPHVzZSB4PScxMDIuNzg5OTM4JyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtMTE2Jy8+Cjx1c2UgeD0nMTA2Ljc3MDk2NScgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTEwNScvPgo8dXNlIHg9JzExMC4wOTQzODYnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMDknLz4KPHVzZSB4PScxMjAuMDUyOTk4JyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtOTcnLz4KPHVzZSB4PScxMjYuMDMwNTgyJyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtMTA4Jy8+Cjx1c2UgeD0nMTMyLjM0Mjc5NScgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTk4Jy8+Cjx1c2UgeD0nMTM4Ljk4OTc5NycgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTk3Jy8+Cjx1c2UgeD0nMTQ0Ljk2NzM4MicgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTExMCcvPgo8dXNlIHg9JzE1MS42MTQzODQnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMDAnLz4KPHVzZSB4PScxNTguMDgyMTcyJyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtMTE5Jy8+Cjx1c2UgeD0nMTY2LjcxMzc3MScgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTEwNScvPgo8dXNlIHg9JzE3MC4wMzcxOTInIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMDAnLz4KPHVzZSB4PScxNzYuNjg0MTk0JyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtMTE2Jy8+Cjx1c2UgeD0nMTgwLjY2NTIyMicgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTEwNCcvPgo8dXNlIHg9JzE5MC4zMDEwMTYnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMDUnLz4KPHVzZSB4PScxOTMuNjI0NDM3JyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtMTEwJy8+Cjx1c2UgeD0nMjAwLjI3MTQzOScgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTExNicvPgo8dXNlIHg9JzIwNC4yNTI0NjcnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC0xMDEnLz4KPHVzZSB4PScyMDkuNTYwNDk2JyB5PSc0MDQuNjg0OTQ2JyB4bGluazpocmVmPScjZzgtMTE0Jy8+Cjx1c2UgeD0nMjE0Ljc0ODk5MycgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTExOCcvPgo8dXNlIHg9JzIyMC42MDcwNDYnIHk9JzQwNC42ODQ5NDYnIHhsaW5rOmhyZWY9JyNnOC05NycvPgo8dXNlIHg9JzIyNi41ODQ2MycgeT0nNDA0LjY4NDk0NicgeGxpbms6aHJlZj0nI2c4LTEwOCcvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzE5LTQ5Jy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnMTktNTYnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PScyMC4zMjM3NDknIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnOC0xMDInLz4KPHVzZSB4PScyNC4wMDU4OTUnIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnOC0xMTEnLz4KPHVzZSB4PScyOS45ODM0NzknIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnOC0xMTQnLz4KPHVzZSB4PSczOC4yODAzJyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzUzLTQ4Jy8+Cjx1c2UgeD0nNDcuNDU0MTInIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNDItMjAnLz4KPHVzZSB4PSc2MC4wNzM0NDYnIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nNjcuMzg3NzA3JyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzQyLTIwJy8+Cjx1c2UgeD0nODAuMDA3MDM0JyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzgzLjMzMDQ1NScgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PSc4OC42Mzg0ODQnIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nOTQuNjE2MDY4JyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzUyLTEwMycvPgo8dXNlIHg9JzEwMC41OTM2NTInIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMTAzLjkxNzA3NCcgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDQnLz4KPHVzZSB4PScxMTIuODgzNDUnIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMTE4Ljg2MTAzNCcgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDInLz4KPHVzZSB4PScxMjUuODMwODMxJyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzQ0LTc2Jy8+Cjx1c2UgeD0nMTMzLjc5NTMzNycgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c0NC0xMDknLz4KPHVzZSB4PScxNDQuMDM0NjA0JyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzQ0LTk3Jy8+Cjx1c2UgeD0nMTUwLjE3OTU0OCcgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c0NC0xMDAnLz4KPHVzZSB4PScxNTYuMjYyMjQxJyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzE2NS4wMDE1OTgnIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNDItMCcvPgo8dXNlIHg9JzE3Ni45NTY3NTgnIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nMTgzLjk0NDM2NCcgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c0NC05OCcvPgo8dXNlIHg9JzE4OC45MjE0NjknIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNDQtODAnLz4KPHVzZSB4PScxOTguMDkyNTY4JyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzQ0LTExMScvPgo8dXNlIHg9JzIwMy43MjAwMDUnIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nMjA3LjcxMzQzOCcgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScyMTQuNzAxMDQzJyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzIxOC45MjgyMDMnIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNDQtMTE1Jy8+Cjx1c2UgeD0nMjI0LjQ0MjIwOScgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c0NC03NycvPgo8dXNlIHg9JzIzNy4wMTU4MTYnIHk9JzQxOS4xMzA3NzQnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nMjQxLjAwOTI0OCcgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScyNTAuOTg1NjQ2JyB5PSc0MTkuMTMwNzc0JyB4bGluazpocmVmPScjZzgtMTAwJy8+Cjx1c2UgeD0nMjU3LjYzMjY0OCcgeT0nNDE5LjEzMDc3NCcgeGxpbms6aHJlZj0nI2c4LTExMScvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc0MzMuNTc2NjAyJyB4bGluazpocmVmPScjZzE5LTQ5Jy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzQzMy41NzY2MDInIHhsaW5rOmhyZWY9JyNnMTktNTcnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzQzMy41NzY2MDInIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSczOC4yNTY1MDEnIHk9JzQzMy41NzY2MDInIHhsaW5rOmhyZWY9JyNnNDQtMTA4Jy8+Cjx1c2UgeD0nNDIuMDA2MzEnIHk9JzQzMy41NzY2MDInIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nNDcuNDMxNzUnIHk9JzQzMy41NzY2MDInIHhsaW5rOmhyZWY9JyNnNDQtMTAyJy8+Cjx1c2UgeD0nNTQuNDc4MTg3JyB5PSc0MzMuNTc2NjAyJyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzU4LjcwNTM0NicgeT0nNDMzLjU3NjYwMicgeGxpbms6aHJlZj0nI2c0NC02NicvPgo8dXNlIHg9JzY4LjIwMTYwNycgeT0nNDMzLjU3NjYwMicgeGxpbms6aHJlZj0nI2c0NC0xMTEnLz4KPHVzZSB4PSc3My44MjkwNDUnIHk9JzQzMy41NzY2MDInIHhsaW5rOmhyZWY9JyNnNDQtMTE3Jy8+Cjx1c2UgeD0nODAuNDkxNDg0JyB5PSc0MzMuNTc2NjAyJyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9Jzg3LjQ3OTA5JyB5PSc0MzMuNTc2NjAyJyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9Jzk2Ljg4MjYxMicgeT0nNDMzLjU3NjYwMicgeGxpbms6aHJlZj0nI2c0Mi0zMicvPgo8dXNlIHg9JzExMi4xNTg2NDQnIHk9JzQzMy41NzY2MDInIHhsaW5rOmhyZWY9JyNnNDQtNzYnLz4KPHVzZSB4PScxMjAuMTIzMTUnIHk9JzQzMy41NzY2MDInIHhsaW5rOmhyZWY9JyNnNDQtMTA0Jy8+Cjx1c2UgeD0nMTI2Ljg2MTcwNScgeT0nNDMzLjU3NjYwMicgeGxpbms6aHJlZj0nI2c1My05MScvPgo8dXNlIHg9JzEzMC4xMTMzNjcnIHk9JzQzMy41NzY2MDInIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nMTM0LjEwNjc5OScgeT0nNDMzLjU3NjYwMicgeGxpbms6aHJlZj0nI2c1My05MycvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzE5LTUwJy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnMTktNDgnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSczOC4yNTY1MDEnIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItNDcnLz4KPHVzZSB4PSc0MS41Nzk5MjMnIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItNDcnLz4KPHVzZSB4PSc0Ny44OTIxMzYnIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItNDknLz4KPHVzZSB4PSc1My44Njk3MicgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi00NicvPgo8dXNlIHg9JzYwLjU2NDU4NScgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi02NicvPgo8dXNlIHg9JzY4LjUzODU4OScgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMTcnLz4KPHVzZSB4PSc3NC41MTYxNzMnIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nNzcuODM5NTk0JyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzgxLjE2MzAxNScgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PSc4Ny4xNDA1OTknIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nOTAuNDY0MDIxJyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9Jzk2LjQ0MTYwNScgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMDMnLz4KPHVzZSB4PScxMDUuNDA3OTgxJyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzExMC43MTYwMScgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PScxMTQuMDM5NDMxJyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzExNy4zNjI4NTMnIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItMTAzJy8+Cjx1c2UgeD0nMTIzLjM0MDQzNycgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScxMjYuNjYzODU4JyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTk4Jy8+Cjx1c2UgeD0nMTMyLjY0MTQ0MicgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMDgnLz4KPHVzZSB4PScxMzUuOTY0ODYzJyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzE0NC4yNjE2ODQnIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMTQ3LjU4NTEwNicgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScxNTMuNTYyNjknIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMTU2Ljg4NjExMScgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxNjIuMTk0MTQnIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItMTE0Jy8+Cjx1c2UgeD0nMTY2LjE3NTE2OCcgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMTgnLz4KPHVzZSB4PScxNzEuODUzODcnIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PScxNzcuMTYxODk5JyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzE4MC40ODUzMicgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PScxODguMTI0NTU4JyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTQwJy8+Cjx1c2UgeD0nMTkyLjEwNTU4NScgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScxOTUuNDI5MDA2JyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTEwMicvPgo8dXNlIHg9JzIwMi4zOTg4MjYnIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMjA4LjM3NjQxJyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzIxMy42ODQ0MzknIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjE4Ljk5MjQ2OCcgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PScyMjQuOTcwMDUyJyB5PSc0NjIuNDY4MjU5JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzIzMC4yNzgwODInIHk9JzQ2Mi40NjgyNTknIHhsaW5rOmhyZWY9JyNnNTItMTAwJy8+Cjx1c2UgeD0nMjM2LjI1NTY2NicgeT0nNDYyLjQ2ODI1OScgeGxpbms6aHJlZj0nI2c1Mi00MScvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzE5LTUwJy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnMTktNDknLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSczOC4yNTY1MDEnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnOC0xMDUnLz4KPHVzZSB4PSc0MS41Nzk5MjMnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnOC0xMDInLz4KPHVzZSB4PSc0OC41NDk3NDInIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtMTA4Jy8+Cjx1c2UgeD0nNTIuMjk5NTUxJyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTEwMScvPgo8dXNlIHg9JzU3LjcyNDk5MScgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c0NC0xMDInLz4KPHVzZSB4PSc2NC43NzE0MjgnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtMTE2Jy8+Cjx1c2UgeD0nNjguOTk4NTg3JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTY2Jy8+Cjx1c2UgeD0nNzguNDk0ODQ4JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTExMScvPgo8dXNlIHg9Jzg0LjEyMjI4NicgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c0NC0xMTcnLz4KPHVzZSB4PSc5MC43ODQ3MjUnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nOTcuNzcyMzMxJyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzEwNy4xNzU4NTMnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtNjInLz4KPHVzZSB4PScxMTkuNjAxMzM0JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzUzLTQwJy8+Cjx1c2UgeD0nMTI0LjE1MzY2JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTEwNCcvPgo8dXNlIHg9JzEzMC44OTIyMTUnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtNzcnLz4KPHVzZSB4PScxNDMuNDY1ODIyJyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTk3Jy8+Cjx1c2UgeD0nMTQ5LjYxMDc2NicgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c0NC0xMjAnLz4KPHVzZSB4PScxNTguOTE5NTE3JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQyLTAnLz4KPHVzZSB4PScxNzAuODc0Njc3JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzE3NC44NjgxMDknIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nMTgxLjg1NTcxNScgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c0NC0xMTYnLz4KPHVzZSB4PScxODYuMDgyODc1JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTEwMScvPgo8dXNlIHg9JzE5MS41MDgzMTUnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtMTE0Jy8+Cjx1c2UgeD0nMTk3LjEwODc4OCcgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c0NC0xMTgnLz4KPHVzZSB4PScyMDMuMTk3MDA3JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTk3Jy8+Cjx1c2UgeD0nMjA5LjM0MTk1MScgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c0NC0xMDgnLz4KPHVzZSB4PScyMTMuMDkxNzYnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtNzYnLz4KPHVzZSB4PScyMjEuMDU2MjY2JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTEwMScvPgo8dXNlIHg9JzIyNi40ODE3MDYnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nMjMzLjQ2OTMxMicgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c0NC0xMDMnLz4KPHVzZSB4PScyMzkuNTAzNTY4JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzI0My43MzA3MjgnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNDQtMTA0Jy8+Cjx1c2UgeD0nMjUwLjQ2OTI4MycgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c0NC03NycvPgo8dXNlIHg9JzI2My4wNDI4OScgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c0NC0xMDUnLz4KPHVzZSB4PScyNjcuMDM2MzIyJyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzI3NC4wMjM5MjgnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnNTMtNDEnLz4KPHVzZSB4PScyODEuNTY1MDQ2JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzgtMTE2Jy8+Cjx1c2UgeD0nMjg1LjU0NjA3MycgeT0nNDc2LjkxNDA4NycgeGxpbms6aHJlZj0nI2c4LTEwNCcvPgo8dXNlIHg9JzI5Mi4xOTMwNzUnIHk9JzQ3Ni45MTQwODcnIHhsaW5rOmhyZWY9JyNnOC0xMDEnLz4KPHVzZSB4PScyOTcuNTAxMTA0JyB5PSc0NzYuOTE0MDg3JyB4bGluazpocmVmPScjZzgtMTEwJy8+Cjx1c2UgeD0nMS42MTQwMTknIHk9JzQ5MS4zNTk5MTUnIHhsaW5rOmhyZWY9JyNnMTktNTAnLz4KPHVzZSB4PSc2LjU5NTMzOScgeT0nNDkxLjM1OTkxNScgeGxpbms6aHJlZj0nI2cxOS01MCcvPgo8dXNlIHg9JzExLjU3NjY1OScgeT0nNDkxLjM1OTkxNScgeGxpbms6aHJlZj0nI2cxOS01OCcvPgo8dXNlIHg9JzU2LjE4OTI1NCcgeT0nNDkxLjM1OTkxNScgeGxpbms6aHJlZj0nI2c4LTk4Jy8+Cjx1c2UgeD0nNjIuODM2MjU2JyB5PSc0OTEuMzU5OTE1JyB4bGluazpocmVmPScjZzgtMTE0Jy8+Cjx1c2UgeD0nNjcuOTI5MTY1JyB5PSc0OTEuMzU5OTE1JyB4bGluazpocmVmPScjZzgtMTAxJy8+Cjx1c2UgeD0nNzMuMjM3MTk0JyB5PSc0OTEuMzU5OTE1JyB4bGluazpocmVmPScjZzgtOTcnLz4KPHVzZSB4PSc3OS4yMTQ3NzgnIHk9JzQ5MS4zNTk5MTUnIHhsaW5rOmhyZWY9JyNnOC0xMDcnLz4KPHVzZSB4PScxLjYxNDAxOScgeT0nNTA1LjgwNTc0MycgeGxpbms6aHJlZj0nI2cxOS01MCcvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PSc1MDUuODA1NzQzJyB4bGluazpocmVmPScjZzE5LTUxJy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PSc1MDUuODA1NzQzJyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nMzguMjU2NTAxJyB5PSc1MDUuODA1NzQzJyB4bGluazpocmVmPScjZzgtMTAxJy8+Cjx1c2UgeD0nNDMuNTY0NTMxJyB5PSc1MDUuODA1NzQzJyB4bGluazpocmVmPScjZzgtMTEwJy8+Cjx1c2UgeD0nNTAuMjExNTMzJyB5PSc1MDUuODA1NzQzJyB4bGluazpocmVmPScjZzgtMTAwJy8+Cjx1c2UgeD0nNTkuODQ3MzI3JyB5PSc1MDUuODA1NzQzJyB4bGluazpocmVmPScjZzgtMTA1Jy8+Cjx1c2UgeD0nNjMuMTcwNzQ4JyB5PSc1MDUuODA1NzQzJyB4bGluazpocmVmPScjZzgtMTAyJy8+Cjx1c2UgeD0nMS42MTQwMTknIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnMTktNTAnLz4KPHVzZSB4PSc2LjU5NTMzOScgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2cxOS01MicvPgo8dXNlIHg9JzExLjU3NjY1OScgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2cxOS01OCcvPgo8dXNlIHg9JzM4LjI1NjUwMScgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC0xMTQnLz4KPHVzZSB4PSc0My44NTY5NzUnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nNDcuODUwNDA3JyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTEwMycvPgo8dXNlIHg9JzUzLjg4NDY2MycgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC0xMDQnLz4KPHVzZSB4PSc2MC42MjMyMTgnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTE2Jy8+Cjx1c2UgeD0nNjQuODUwMzc4JyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTY2Jy8+Cjx1c2UgeD0nNzQuMzQ2NjM5JyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTExMScvPgo8dXNlIHg9Jzc5Ljk3NDA3NicgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC0xMTcnLz4KPHVzZSB4PSc4Ni42MzY1MTYnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nOTMuNjI0MTIyJyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzEwMy4wMjc2NDQnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDItMzInLz4KPHVzZSB4PScxMTguMzAzNjc2JyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTEwOCcvPgo8dXNlIHg9JzEyMi4wNTM0ODQnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nMTI3LjQ3ODkyNCcgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC0xMDInLz4KPHVzZSB4PScxMzQuNTI1MzYxJyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzEzOC43NTI1MicgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC02NicvPgo8dXNlIHg9JzE0OC4yNDg3ODEnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTExJy8+Cjx1c2UgeD0nMTUzLjg3NjIxOScgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC0xMTcnLz4KPHVzZSB4PScxNjAuNTM4NjU4JyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzE2Ny41MjYyNjQnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nMTc2LjI2NTYyMScgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c1My00MycvPgo8dXNlIHg9JzE4OC4wMjY5MzYnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nMTkyLjAyMDM2OCcgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScxOTkuMDA3OTczJyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzIwMy4yMzUxMzMnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nMjA4LjY2MDU3MycgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC0xMTQnLz4KPHVzZSB4PScyMTQuMjYxMDQ3JyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTExOCcvPgo8dXNlIHg9JzIyMC4zNDkyNjYnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtOTcnLz4KPHVzZSB4PScyMjYuNDk0MjEnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTA4Jy8+Cjx1c2UgeD0nMjMwLjI0NDAxOCcgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC03NicvPgo8dXNlIHg9JzIzOC4yMDg1MjUnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nMjQzLjYzMzk2NScgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScyNTAuNjIxNTcnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTAzJy8+Cjx1c2UgeD0nMjU2LjY1NTgyNycgeT0nNTIwLjI1MTU3MScgeGxpbms6aHJlZj0nI2c0NC0xMTYnLz4KPHVzZSB4PScyNjAuODgyOTg2JyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTEwNCcvPgo8dXNlIHg9JzI2Ny42MjE1NDEnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtNzcnLz4KPHVzZSB4PScyODAuMTk1MTQ4JyB5PSc1MjAuMjUxNTcxJyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzI4NC4xODg1ODEnIHk9JzUyMC4yNTE1NzEnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nMS42MTQwMTknIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnMTktNTAnLz4KPHVzZSB4PSc2LjU5NTMzOScgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2cxOS01MycvPgo8dXNlIHg9JzExLjU3NjY1OScgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2cxOS01OCcvPgo8dXNlIHg9JzM4LjI1NjUwMScgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c0NC0xMTQnLz4KPHVzZSB4PSc0My44NTY5NzUnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nNDcuODUwNDA3JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTEwMycvPgo8dXNlIHg9JzUzLjg4NDY2MycgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c0NC0xMDQnLz4KPHVzZSB4PSc2MC42MjMyMTgnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNDQtMTE2Jy8+Cjx1c2UgeD0nNjQuODUwMzc4JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTY2Jy8+Cjx1c2UgeD0nNzQuMzQ2NjM5JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTExMScvPgo8dXNlIHg9Jzc5Ljk3NDA3NicgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c0NC0xMTcnLz4KPHVzZSB4PSc4Ni42MzY1MTYnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nOTMuNjI0MTIyJyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9Jzk5LjcwNjgxNScgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c0NC03MycvPgo8dXNlIHg9JzEwNS44MDk1OTcnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nMTEyLjc5NzIwMicgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c0NC0xMDAnLz4KPHVzZSB4PScxMTguODc5ODk1JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTEwMScvPgo8dXNlIHg9JzEyNC4zMDUzMzYnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNDQtMTIwJy8+Cjx1c2UgeD0nMTM0LjI3ODI1MicgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c0Mi0zMicvPgo8dXNlIHg9JzE0OS41NTQyODQnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNTMtNDAnLz4KPHVzZSB4PScxNTQuMTA2NjA5JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzUyLTExMicvPgo8dXNlIHg9JzE2MC4wODQxOTQnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMTY2LjA2MTc3OCcgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PScxNzAuNzEyMjIzJyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzE3NC4wMzU2NDUnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNTItMTE2Jy8+Cjx1c2UgeD0nMTc3LjM1OTA2NicgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScxODAuNjgyNDg3JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzUyLTExMScvPgo8dXNlIHg9JzE4Ni42NjAwNzEnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMTk1LjYyNjQ0NycgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PScyMDEuNjA0MDMxJyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzUyLTEwMicvPgo8dXNlIHg9JzIwOC41NzM4MicgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c0NC0xMTQnLz4KPHVzZSB4PScyMTQuMTc0Mjk0JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzIxOC4xNjc3MjYnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNDQtMTAzJy8+Cjx1c2UgeD0nMjI0LjIwMTk4MicgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c0NC0xMDQnLz4KPHVzZSB4PScyMzAuOTQwNTM3JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzIzNS4xNjc2OTcnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNDQtNjYnLz4KPHVzZSB4PScyNDQuNjYzOTU4JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTExMScvPgo8dXNlIHg9JzI1MC4yOTEzOTUnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNDQtMTE3Jy8+Cjx1c2UgeD0nMjU2Ljk1MzgzNScgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScyNjMuOTQxNDQxJyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzI3My4wMTI5MjYnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PScyNzguMzIwOTU1JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzI4NS45NjAxOTInIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjg5LjI4MzYxNCcgeT0nNTM0LjY5NzM5OScgeGxpbms6aHJlZj0nI2c1Mi0xMDInLz4KPHVzZSB4PScyOTYuMjUzNDMzJyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzI5OS41NzY4NTUnIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMzA4LjU0MzInIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNDQtNzYnLz4KPHVzZSB4PSczMTYuNTA3NzA3JyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQ0LTEwNCcvPgo8dXNlIHg9JzMyMy4yNDYyNjInIHk9JzUzNC42OTczOTknIHhsaW5rOmhyZWY9JyNnNTMtNDEnLz4KPHVzZSB4PSczMzAuNDU1MjUxJyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzQyLTAnLz4KPHVzZSB4PSczNDIuNDEwNDExJyB5PSc1MzQuNjk3Mzk5JyB4bGluazpocmVmPScjZzUzLTQ5Jy8+Cjx1c2UgeD0nMS42MTQwMTknIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnMTktNTAnLz4KPHVzZSB4PSc2LjU5NTMzOScgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2cxOS01NCcvPgo8dXNlIHg9JzExLjU3NjY1OScgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2cxOS01OCcvPgo8dXNlIHg9JzM4LjI1NjUwMScgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c4LTEwNScvPgo8dXNlIHg9JzQxLjU3OTkyMycgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c4LTEwMicvPgo8dXNlIHg9JzQ4LjU0OTc0MicgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c0NC0xMTQnLz4KPHVzZSB4PSc1NC4xNTAyMTYnIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nNTguMTQzNjQ4JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTEwMycvPgo8dXNlIHg9JzY0LjE3NzkwNCcgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c0NC0xMDQnLz4KPHVzZSB4PSc3MC45MTY0NTknIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNDQtMTE2Jy8+Cjx1c2UgeD0nNzUuMTQzNjE5JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTY2Jy8+Cjx1c2UgeD0nODQuNjM5ODgnIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNDQtMTExJy8+Cjx1c2UgeD0nOTAuMjY3MzE3JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTExNycvPgo8dXNlIHg9Jzk2LjkyOTc1NycgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScxMDMuOTE3MzYzJyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzExMC4wMDAwNTUnIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNDQtNzMnLz4KPHVzZSB4PScxMTYuMTAyODM4JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzEyMy4wOTA0NDMnIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nMTI5LjE3MzEzNicgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c0NC0xMDEnLz4KPHVzZSB4PScxMzQuNTk4NTc2JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTEyMCcvPgo8dXNlIHg9JzE0NC41NzE0OTMnIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNDQtNjAnLz4KPHVzZSB4PScxNTYuOTk2OTc0JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzE2My42NDcwNjknIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNTMtNDMnLz4KPHVzZSB4PScxNzUuNDA4Mzg0JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzE4Mi4zOTU5OScgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c0NC05OCcvPgo8dXNlIHg9JzE4Ny4zNzMwOTYnIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNDQtODAnLz4KPHVzZSB4PScxOTYuNTQ0MTk0JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTExMScvPgo8dXNlIHg9JzIwMi4xNzE2MzInIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nMjA2LjE2NTA2NCcgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScyMTMuMTUyNjcnIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnNDQtMTE2Jy8+Cjx1c2UgeD0nMjE3LjM3OTgyOScgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c0NC0xMTUnLz4KPHVzZSB4PScyMjIuODkzODM1JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTc3Jy8+Cjx1c2UgeD0nMjM1LjQ2NzQ0MicgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c0NC0xMDUnLz4KPHVzZSB4PScyMzkuNDYwODc0JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzI0OS40MzcyNzInIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnOC0xMTYnLz4KPHVzZSB4PScyNTMuNDE4Mjk5JyB5PSc1NDkuMTQzMjI4JyB4bGluazpocmVmPScjZzgtMTA0Jy8+Cjx1c2UgeD0nMjYwLjA2NTMwMicgeT0nNTQ5LjE0MzIyOCcgeGxpbms6aHJlZj0nI2c4LTEwMScvPgo8dXNlIHg9JzI2NS4zNzMzMzEnIHk9JzU0OS4xNDMyMjgnIHhsaW5rOmhyZWY9JyNnOC0xMTAnLz4KPHVzZSB4PScxLjYxNDAxOScgeT0nNTYzLjU4OTA1NicgeGxpbms6aHJlZj0nI2cxOS01MCcvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzE5LTU1Jy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nNTYuMTg5MjU0JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTExNCcvPgo8dXNlIHg9JzYxLjc4OTcyNycgeT0nNTYzLjU4OTA1NicgeGxpbms6aHJlZj0nI2c0NC0xMDUnLz4KPHVzZSB4PSc2NS43ODMxNTknIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNDQtMTAzJy8+Cjx1c2UgeD0nNzEuODE3NDE2JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTEwNCcvPgo8dXNlIHg9Jzc4LjU1NTk3MScgeT0nNTYzLjU4OTA1NicgeGxpbms6aHJlZj0nI2c0NC0xMTYnLz4KPHVzZSB4PSc4Mi43ODMxMycgeT0nNTYzLjU4OTA1NicgeGxpbms6aHJlZj0nI2c0NC02NicvPgo8dXNlIHg9JzkyLjI3OTM5MScgeT0nNTYzLjU4OTA1NicgeGxpbms6aHJlZj0nI2c0NC0xMTEnLz4KPHVzZSB4PSc5Ny45MDY4MjknIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNDQtMTE3Jy8+Cjx1c2UgeD0nMTA0LjU2OTI2OCcgeT0nNTYzLjU4OTA1NicgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScxMTEuNTU2ODc0JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzExNy42Mzk1NjcnIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNDQtNzMnLz4KPHVzZSB4PScxMjMuNzQyMzQ5JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzEzMC43Mjk5NTUnIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nMTM2LjgxMjY0OCcgeT0nNTYzLjU4OTA1NicgeGxpbms6aHJlZj0nI2c0NC0xMDEnLz4KPHVzZSB4PScxNDIuMjM4MDg4JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTEyMCcvPgo8dXNlIHg9JzE1Mi4yMTEwMDQnIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNDItMzInLz4KPHVzZSB4PScxNjcuNDg3MDM2JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzE3NC4xMzcxMzInIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNTMtNDMnLz4KPHVzZSB4PScxODUuODk4NDQ3JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzE5Mi44ODYwNTInIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNDQtOTgnLz4KPHVzZSB4PScxOTcuODYzMTU4JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTgwJy8+Cjx1c2UgeD0nMjA3LjAzNDI1NicgeT0nNTYzLjU4OTA1NicgeGxpbms6aHJlZj0nI2c0NC0xMTEnLz4KPHVzZSB4PScyMTIuNjYxNjk0JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzIxNi42NTUxMjYnIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nMjIzLjY0MjczMicgeT0nNTYzLjU4OTA1NicgeGxpbms6aHJlZj0nI2c0NC0xMTYnLz4KPHVzZSB4PScyMjcuODY5ODkxJyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTExNScvPgo8dXNlIHg9JzIzMy4zODM4OTcnIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNDQtNzcnLz4KPHVzZSB4PScyNDUuOTU3NTA0JyB5PSc1NjMuNTg5MDU2JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzI0OS45NTA5MzYnIHk9JzU2My41ODkwNTYnIHhsaW5rOmhyZWY9JyNnNDQtMTEwJy8+Cjx1c2UgeD0nMS42MTQwMTknIHk9JzU3OC4wMzQ4ODQnIHhsaW5rOmhyZWY9JyNnMTktNTAnLz4KPHVzZSB4PSc2LjU5NTMzOScgeT0nNTc4LjAzNDg4NCcgeGxpbms6aHJlZj0nI2cxOS01NicvPgo8dXNlIHg9JzExLjU3NjY1OScgeT0nNTc4LjAzNDg4NCcgeGxpbms6aHJlZj0nI2cxOS01OCcvPgo8dXNlIHg9JzM4LjI1NjUwMScgeT0nNTc4LjAzNDg4NCcgeGxpbms6aHJlZj0nI2c4LTEwMScvPgo8dXNlIHg9JzQzLjU2NDUzMScgeT0nNTc4LjAzNDg4NCcgeGxpbms6aHJlZj0nI2c4LTExMCcvPgo8dXNlIHg9JzUwLjIxMTUzMycgeT0nNTc4LjAzNDg4NCcgeGxpbms6aHJlZj0nI2c4LTEwMCcvPgo8dXNlIHg9JzU5Ljg0NzMyNycgeT0nNTc4LjAzNDg4NCcgeGxpbms6aHJlZj0nI2c4LTEwNScvPgo8dXNlIHg9JzYzLjE3MDc0OCcgeT0nNTc4LjAzNDg4NCcgeGxpbms6aHJlZj0nI2c4LTEwMicvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnMTktNTAnLz4KPHVzZSB4PSc2LjU5NTMzOScgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzE5LTU3Jy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSczOC4yNTY1MDEnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi00NycvPgo8dXNlIHg9JzQxLjU3OTkyMycgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTQ3Jy8+Cjx1c2UgeD0nNDcuODkyMTM2JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItNTAnLz4KPHVzZSB4PSc1My44Njk3MicgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTQ2Jy8+Cjx1c2UgeD0nNjAuNTY0NTg1JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItNzMnLz4KPHVzZSB4PSc2NC41NDU2MTMnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PSc3MC41MjMxOTcnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi05OScvPgo8dXNlIHg9Jzc1LjgzMTIyNicgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9Jzc5LjgxMjI1MycgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9Jzg1LjEyMDI4MycgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nOTAuNDI4MzEyJyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTE1Jy8+Cjx1c2UgeD0nOTUuMDc4NzU3JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nOTguNDAyMTc5JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMTA0LjM3OTc2MycgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTEwMycvPgo8dXNlIHg9JzExMy4zNDYxMzknIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMTcnLz4KPHVzZSB4PScxMTkuMzIzNzIzJyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTEyJy8+Cjx1c2UgeD0nMTI1LjMwMTMwNycgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTExMicvPgo8dXNlIHg9JzEzMS4yNzg4OTEnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxMzYuNTg2OTInIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PScxNDMuNTU2NzQnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi05OCcvPgo8dXNlIHg9JzE0OS41MzQzMjQnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PScxNTUuNTExOTA4JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTE3Jy8+Cjx1c2UgeD0nMTYxLjQ4OTQ5MicgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzE2Ny40NjcwNzYnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PScxNzYuNDMzNDUyJyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMTgyLjQxMTAzNicgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTEwMicvPgo8dXNlIHg9JzE4OS4zODA4NTYnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScxOTQuNjg4ODg1JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTA4Jy8+Cjx1c2UgeD0nMTk4LjAxMjMwNicgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzIwMS4zMzU3MjcnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDMnLz4KPHVzZSB4PScyMDcuMzEzMzExJyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjEwLjYzNjczMycgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTk4Jy8+Cjx1c2UgeD0nMjE2LjYxNDMxNycgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTEwOCcvPgo8dXNlIHg9JzIxOS45Mzc3MzgnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScyMjguMjM0NTU5JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTA1Jy8+Cjx1c2UgeD0nMjMxLjU1Nzk4MScgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzIzNy41MzU1NjUnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScyNDAuODU4OTg2JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMjQ2LjE2NzAxNScgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTExNCcvPgo8dXNlIHg9JzI1MC4xNDgwNDMnIHk9JzYwNi45MjY1NCcgeGxpbms6aHJlZj0nI2c1Mi0xMTgnLz4KPHVzZSB4PScyNTUuODI2NzQ0JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PScyNjEuMTM0Nzc0JyB5PSc2MDYuOTI2NTQnIHhsaW5rOmhyZWY9JyNnNTItMTA4Jy8+Cjx1c2UgeD0nMjY0LjQ1ODE5NScgeT0nNjA2LjkyNjU0JyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzE5LTUxJy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnMTktNDgnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSczOC4yNTY1MDEnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnOC0xMDInLz4KPHVzZSB4PSc0MS45Mzg2NDcnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnOC0xMTEnLz4KPHVzZSB4PSc0Ny45MTYyMzEnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnOC0xMTQnLz4KPHVzZSB4PSc1Ni4yMTMwNTInIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDQtMTE0Jy8+Cjx1c2UgeD0nNjEuODEzNTI2JyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzY1LjgwNjk1OCcgeT0nNjIxLjM3MjM2OCcgeGxpbms6aHJlZj0nI2c0NC0xMDMnLz4KPHVzZSB4PSc3MS44NDEyMTQnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDQtMTA0Jy8+Cjx1c2UgeD0nNzguNTc5NzY5JyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzQ0LTExNicvPgo8dXNlIHg9JzgyLjgwNjkyOScgeT0nNjIxLjM3MjM2OCcgeGxpbms6aHJlZj0nI2c0NC02NicvPgo8dXNlIHg9JzkyLjMwMzE4OScgeT0nNjIxLjM3MjM2OCcgeGxpbms6aHJlZj0nI2c0NC0xMTEnLz4KPHVzZSB4PSc5Ny45MzA2MjcnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDQtMTE3Jy8+Cjx1c2UgeD0nMTA0LjU5MzA2NycgeT0nNjIxLjM3MjM2OCcgeGxpbms6aHJlZj0nI2c0NC0xMTAnLz4KPHVzZSB4PScxMTEuNTgwNjcyJyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzExNy42NjMzNjUnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDQtNzMnLz4KPHVzZSB4PScxMjMuNzY2MTQ3JyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzEzMC43NTM3NTMnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nMTM2LjgzNjQ0NicgeT0nNjIxLjM3MjM2OCcgeGxpbms6aHJlZj0nI2c0NC0xMDEnLz4KPHVzZSB4PScxNDIuMjYxODg2JyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzQ0LTEyMCcvPgo8dXNlIHg9JzE1Mi4yMzQ4MDMnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDItMjAnLz4KPHVzZSB4PScxNjQuODU0MTI5JyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzQ0LTEwNicvPgo8dXNlIHg9JzE3My42OTA0NTQnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDItMjAnLz4KPHVzZSB4PScxODYuMzA5NzgnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMTkxLjYxNzgwOScgeT0nNjIxLjM3MjM2OCcgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScxOTcuNTk1MzkzJyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzUyLTEwMCcvPgo8dXNlIHg9JzIwNi41NjE3NycgeT0nNjIxLjM3MjM2OCcgeGxpbms6aHJlZj0nI2c1Mi0xMTEnLz4KPHVzZSB4PScyMTIuNTM5MzU0JyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzUyLTEwMicvPgo8dXNlIHg9JzIxOS41MDkxNjYnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDQtNzYnLz4KPHVzZSB4PScyMjcuNDczNjcyJyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzQ0LTEwOScvPgo8dXNlIHg9JzIzNy43MTI5MzknIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDQtOTcnLz4KPHVzZSB4PScyNDMuODU3ODgzJyB5PSc2MjEuMzcyMzY4JyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzI0OS45NDA1NzYnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nMjU5LjAxMjA2MScgeT0nNjIxLjM3MjM2OCcgeGxpbms6aHJlZj0nI2c4LTEwMCcvPgo8dXNlIHg9JzI2NS42NTkwNjMnIHk9JzYyMS4zNzIzNjgnIHhsaW5rOmhyZWY9JyNnOC0xMTEnLz4KPHVzZSB4PScxLjYxNDAxOScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2cxOS01MScvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzE5LTQ5Jy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nNTYuMTg5MjU0JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzQ0LTExNScvPgo8dXNlIHg9JzYxLjcwMzI1OScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c0NC0xMTYnLz4KPHVzZSB4PSc2NS45MzA0MTknIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nNzUuMzMzOTQxJyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzQyLTMyJy8+Cjx1c2UgeD0nOTAuNjA5OTczJyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTExNScvPgo8dXNlIHg9Jzk1LjI2MDQxOScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PSc5OC41ODM4NCcgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi05NycvPgo8dXNlIHg9JzEwMy44OTE4NjknIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMTA5Ljg2OTQ1MycgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PScxMTUuODQ3MDM3JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMTIxLjE1NTA2NicgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMTQnLz4KPHVzZSB4PScxMjUuMTM2MDk0JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTEwMCcvPgo8dXNlIHg9JzEzNC4xMDI0NycgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PScxNDAuMDgwMDU0JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzE0NS4wODkyMDEnIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNTItMTE4Jy8+Cjx1c2UgeD0nMTUxLjA2Njc4NScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScxNTQuMzkwMjA2JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTk3Jy8+Cjx1c2UgeD0nMTU5LjY5ODIzNScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMTYnLz4KPHVzZSB4PScxNjMuMDIxNjU3JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTEwNScvPgo8dXNlIHg9JzE2Ni4zNDUwNzgnIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNTItMTExJy8+Cjx1c2UgeD0nMTcyLjMyMjY2MicgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PScxODEuMjg5MDM4JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTExMScvPgo8dXNlIHg9JzE4Ny4yNjY2MjInIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNTItMTAyJy8+Cjx1c2UgeD0nMTk0LjIzNjQ0MicgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c0NC03NicvPgo8dXNlIHg9JzIwMi4yMDA5NDgnIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNDQtMTA5Jy8+Cjx1c2UgeD0nMjEyLjQ0MDIxNScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c0NC05NycvPgo8dXNlIHg9JzIxOC41ODUxNTknIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nMjI0LjY2Nzg1MicgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c0NC0xMDAnLz4KPHVzZSB4PScyMzMuNzM5MzM3JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTk4Jy8+Cjx1c2UgeD0nMjM5LjcxNjkyMicgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScyNDUuMDI0OTUxJyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTExNicvPgo8dXNlIHg9JzI0OC4zNDgzNzInIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNTItMTE5Jy8+Cjx1c2UgeD0nMjU2Ljk3OTk3MScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMDEnLz4KPHVzZSB4PScyNjIuMjg4JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzI2Ny41OTYwMjknIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNTItMTEwJy8+Cjx1c2UgeD0nMjc2LjU2MjQwNScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMDUnLz4KPHVzZSB4PScyNzkuODg1ODI2JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTExMCcvPgo8dXNlIHg9JzI4NS44NjM0MScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMDAnLz4KPHVzZSB4PScyOTEuODQwOTk0JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTEwMScvPgo8dXNlIHg9JzI5Ni45Njk4MScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMjAnLz4KPHVzZSB4PSczMDIuNzY4MTgnIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNTItMTAxJy8+Cjx1c2UgeD0nMzA4LjA3NjIwOScgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMTUnLz4KPHVzZSB4PSczMTUuNzE1NDQ3JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzQ0LTEwNScvPgo8dXNlIHg9JzMyMi42OTc2NzEnIHk9JzYzNS44MTgxOTYnIHhsaW5rOmhyZWY9JyNnNTItOTcnLz4KPHVzZSB4PSczMjguMDA1NycgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c1Mi0xMTAnLz4KPHVzZSB4PSczMzMuOTgzMjg0JyB5PSc2MzUuODE4MTk2JyB4bGluazpocmVmPScjZzUyLTEwMCcvPgo8dXNlIHg9JzM0Mi45NDk2NicgeT0nNjM1LjgxODE5NicgeGxpbms6aHJlZj0nI2c0NC0xMDYnLz4KPHVzZSB4PScxLjYxNDAxOScgeT0nNjUwLjI2NDAyNScgeGxpbms6aHJlZj0nI2cxOS01MScvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzE5LTUwJy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nNTYuMTg5MjU0JyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzgtMTA1Jy8+Cjx1c2UgeD0nNTkuNTEyNjc1JyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzgtMTAyJy8+Cjx1c2UgeD0nNjYuNDgyNDk1JyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzQ0LTExNScvPgo8dXNlIHg9JzcxLjk5NjUnIHk9JzY1MC4yNjQwMjUnIHhsaW5rOmhyZWY9JyNnNDQtMTE2Jy8+Cjx1c2UgeD0nNzYuMjIzNjYnIHk9JzY1MC4yNjQwMjUnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nODUuNjI3MTgyJyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzQ0LTYwJy8+Cjx1c2UgeD0nOTguMDUyNjYzJyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzQ0LTExNScvPgo8dXNlIHg9JzEwMy41NjY2NjknIHk9JzY1MC4yNjQwMjUnIHhsaW5rOmhyZWY9JyNnNDQtMTE2Jy8+Cjx1c2UgeD0nMTA3Ljc5MzgyOCcgeT0nNjUwLjI2NDAyNScgeGxpbms6aHJlZj0nI2c0NC0xMDAnLz4KPHVzZSB4PScxMTMuODc2NTIxJyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzQ0LTc3Jy8+Cjx1c2UgeD0nMTI2LjQ1MDEyOCcgeT0nNjUwLjI2NDAyNScgeGxpbms6aHJlZj0nI2c0NC0xMDUnLz4KPHVzZSB4PScxMzAuNDQzNTYxJyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzE0MC40MTk5NTgnIHk9JzY1MC4yNjQwMjUnIHhsaW5rOmhyZWY9JyNnOC0xMTYnLz4KPHVzZSB4PScxNDQuNDAwOTg2JyB5PSc2NTAuMjY0MDI1JyB4bGluazpocmVmPScjZzgtMTA0Jy8+Cjx1c2UgeD0nMTUxLjA0Nzk4OCcgeT0nNjUwLjI2NDAyNScgeGxpbms6aHJlZj0nI2c4LTEwMScvPgo8dXNlIHg9JzE1Ni4zNTYwMTcnIHk9JzY1MC4yNjQwMjUnIHhsaW5rOmhyZWY9JyNnOC0xMTAnLz4KPHVzZSB4PScxLjYxNDAxOScgeT0nNjY0LjcwOTg1MycgeGxpbms6aHJlZj0nI2cxOS01MScvPgo8dXNlIHg9JzYuNTk1MzM5JyB5PSc2NjQuNzA5ODUzJyB4bGluazpocmVmPScjZzE5LTUxJy8+Cjx1c2UgeD0nMTEuNTc2NjU5JyB5PSc2NjQuNzA5ODUzJyB4bGluazpocmVmPScjZzE5LTU4Jy8+Cjx1c2UgeD0nNzQuMTIyMDA2JyB5PSc2NjQuNzA5ODUzJyB4bGluazpocmVmPScjZzQ0LTExNScvPgo8dXNlIHg9Jzc5LjYzNjAxMicgeT0nNjY0LjcwOTg1MycgeGxpbms6aHJlZj0nI2c0NC0xMTYnLz4KPHVzZSB4PSc4My44NjMxNzEnIHk9JzY2NC43MDk4NTMnIHhsaW5rOmhyZWY9JyNnNDQtMTAwJy8+Cjx1c2UgeD0nODkuOTQ1ODY0JyB5PSc2NjQuNzA5ODUzJyB4bGluazpocmVmPScjZzQ0LTc3Jy8+Cjx1c2UgeD0nMTAyLjUxOTQ3MScgeT0nNjY0LjcwOTg1MycgeGxpbms6aHJlZj0nI2c0NC0xMDUnLz4KPHVzZSB4PScxMDYuNTEyOTAzJyB5PSc2NjQuNzA5ODUzJyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9JzExNi44MjEzMzgnIHk9JzY2NC43MDk4NTMnIHhsaW5rOmhyZWY9JyNnNDItMzInLz4KPHVzZSB4PScxMzIuMDk3MzcnIHk9JzY2NC43MDk4NTMnIHhsaW5rOmhyZWY9JyNnNDQtMTE1Jy8+Cjx1c2UgeD0nMTM3LjYxMTM3NicgeT0nNjY0LjcwOTg1MycgeGxpbms6aHJlZj0nI2c0NC0xMTYnLz4KPHVzZSB4PScxNDEuODM4NTM1JyB5PSc2NjQuNzA5ODUzJyB4bGluazpocmVmPScjZzQ0LTEwMCcvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc2NzkuMTU1NjgxJyB4bGluazpocmVmPScjZzE5LTUxJy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzY3OS4xNTU2ODEnIHhsaW5rOmhyZWY9JyNnMTktNTInLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzY3OS4xNTU2ODEnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSc3NC4xMjIwMDYnIHk9JzY3OS4xNTU2ODEnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nNzguMTE1NDM4JyB5PSc2NzkuMTU1NjgxJyB4bGluazpocmVmPScjZzQ0LTExMCcvPgo8dXNlIHg9Jzg1LjEwMzA0NCcgeT0nNjc5LjE1NTY4MScgeGxpbms6aHJlZj0nI2c0NC0xMDAnLz4KPHVzZSB4PSc5MS4xODU3MzcnIHk9JzY3OS4xNTU2ODEnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nOTYuNjExMTc3JyB5PSc2NzkuMTU1NjgxJyB4bGluazpocmVmPScjZzQ0LTEyMCcvPgo8dXNlIHg9JzEwMy4yNjMyNjQnIHk9JzY3OS4xNTU2ODEnIHhsaW5rOmhyZWY9JyNnNDQtMTAxJy8+Cjx1c2UgeD0nMTA4LjY4ODcwNCcgeT0nNjc5LjE1NTY4MScgeGxpbms6aHJlZj0nI2c0NC0xMTUnLz4KPHVzZSB4PScxMTcuNTIzNTM5JyB5PSc2NzkuMTU1NjgxJyB4bGluazpocmVmPScjZzQyLTMyJy8+Cjx1c2UgeD0nMTMyLjc5OTU3MScgeT0nNjc5LjE1NTY4MScgeGxpbms6aHJlZj0nI2c1My00MCcvPgo8dXNlIHg9JzEzNy4zNTE4OTcnIHk9JzY3OS4xNTU2ODEnIHhsaW5rOmhyZWY9JyNnNDQtMTA1Jy8+Cjx1c2UgeD0nMTQxLjM0NTMyOScgeT0nNjc5LjE1NTY4MScgeGxpbms6aHJlZj0nI2c0NC01OScvPgo8dXNlIHg9JzE0Ni41ODk0ODgnIHk9JzY3OS4xNTU2ODEnIHhsaW5rOmhyZWY9JyNnNDQtMTA2Jy8+Cjx1c2UgeD0nMTUyLjEwNDk4MycgeT0nNjc5LjE1NTY4MScgeGxpbms6aHJlZj0nI2c1My00MScvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc2OTMuNjAxNTA5JyB4bGluazpocmVmPScjZzE5LTUxJy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzY5My42MDE1MDknIHhsaW5rOmhyZWY9JyNnMTktNTMnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzY5My42MDE1MDknIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PSc1Ni4xODkyNTQnIHk9JzY5My42MDE1MDknIHhsaW5rOmhyZWY9JyNnOC0xMDEnLz4KPHVzZSB4PSc2MS40OTcyODMnIHk9JzY5My42MDE1MDknIHhsaW5rOmhyZWY9JyNnOC0xMTAnLz4KPHVzZSB4PSc2OC4xNDQyODUnIHk9JzY5My42MDE1MDknIHhsaW5rOmhyZWY9JyNnOC0xMDAnLz4KPHVzZSB4PSc3Ny43ODAwNzknIHk9JzY5My42MDE1MDknIHhsaW5rOmhyZWY9JyNnOC0xMDUnLz4KPHVzZSB4PSc4MS4xMDM1JyB5PSc2OTMuNjAxNTA5JyB4bGluazpocmVmPScjZzgtMTAyJy8+Cjx1c2UgeD0nMS42MTQwMTknIHk9JzcwOC4wNDczMzcnIHhsaW5rOmhyZWY9JyNnMTktNTEnLz4KPHVzZSB4PSc2LjU5NTMzOScgeT0nNzA4LjA0NzMzNycgeGxpbms6aHJlZj0nI2cxOS01NCcvPgo8dXNlIHg9JzExLjU3NjY1OScgeT0nNzA4LjA0NzMzNycgeGxpbms6aHJlZj0nI2cxOS01OCcvPgo8dXNlIHg9JzM4LjI1NjUwMScgeT0nNzA4LjA0NzMzNycgeGxpbms6aHJlZj0nI2c4LTEwMScvPgo8dXNlIHg9JzQzLjU2NDUzMScgeT0nNzA4LjA0NzMzNycgeGxpbms6aHJlZj0nI2c4LTExMCcvPgo8dXNlIHg9JzUwLjIxMTUzMycgeT0nNzA4LjA0NzMzNycgeGxpbms6aHJlZj0nI2c4LTEwMCcvPgo8dXNlIHg9JzU5Ljg0NzMyNycgeT0nNzA4LjA0NzMzNycgeGxpbms6aHJlZj0nI2c4LTEwMicvPgo8dXNlIHg9JzYzLjUyOTQ3MicgeT0nNzA4LjA0NzMzNycgeGxpbms6aHJlZj0nI2c4LTExMScvPgo8dXNlIHg9JzY5LjUwNzA1NicgeT0nNzA4LjA0NzMzNycgeGxpbms6aHJlZj0nI2c4LTExNCcvPgo8dXNlIHg9JzEuNjE0MDE5JyB5PSc3MzYuOTM4OTkzJyB4bGluazpocmVmPScjZzE5LTUxJy8+Cjx1c2UgeD0nNi41OTUzMzknIHk9JzczNi45Mzg5OTMnIHhsaW5rOmhyZWY9JyNnMTktNTUnLz4KPHVzZSB4PScxMS41NzY2NTknIHk9JzczNi45Mzg5OTMnIHhsaW5rOmhyZWY9JyNnMTktNTgnLz4KPHVzZSB4PScyMC4zMjM3NDknIHk9JzczNi45Mzg5OTMnIHhsaW5rOmhyZWY9JyNnOC0xMDEnLz4KPHVzZSB4PScyNS42MzE3NzgnIHk9JzczNi45Mzg5OTMnIHhsaW5rOmhyZWY9JyNnOC0xMTAnLz4KPHVzZSB4PSczMi4yNzg3ODEnIHk9JzczNi45Mzg5OTMnIHhsaW5rOmhyZWY9JyNnOC0xMDAnLz4KPHVzZSB4PSc0MS45MTQ1NzUnIHk9JzczNi45Mzg5OTMnIHhsaW5rOmhyZWY9JyNnOC0xMDInLz4KPHVzZSB4PSc0NS41OTY3MicgeT0nNzM2LjkzODk5MycgeGxpbms6aHJlZj0nI2c4LTExMScvPgo8dXNlIHg9JzUxLjU3NDMwNCcgeT0nNzM2LjkzODk5MycgeGxpbms6aHJlZj0nI2c4LTExNCcvPgo8L2c+Cjwvc3ZnPg==)
As a final remark, Algorithm 1 should thus be provided with a list of \(h\) values representing the search
space within which to find the stable interval, i.e., the optimal bandwidth interval. More precisely, to
compute this list, it is important to note that it is not necessary to consider every possible discrete \(h\)
within \((0, 1]\). Indeed, an infinity of particular \(h\) would yield the same number of bins \(m\), which does not affect
the resulting MADD value. For instance, both \(h = 0.7\) and \(h = 0.6\) lead to the same \(m = \lfloor 1/h \rfloor = 1\) bin, as well as \(h = 0.71\), \(h = 0.711\), \(h = 0.7111\), and so on.
Therefore, we propose to compute the relevant values of \(h\) directly from a list of distinct \(m\) values,
handled in the maddlib package (see the getting-started tutorials3). For instance, let us
assume that we want to find the optimal bandwidth interval considering a search space
with only 5 \(h\) values, as a toy example. We first compute \(m = [1, 2, 3, 4, 5[\) that we turn by definition (\(\lfloor 1/h \rfloor \)) into \(h = [1, 0.50, 0.3\overline {3}, 0.25, 0.2[\),
finally reversed to become the search space \(h = ]0.2, 0.25, 0.3\overline {3}, 0.50, 1]\). Repeating this process with a large number
of \(m\) or \(h\), e.g., 500, the larger the \(m\), the smaller the \(h\). Thus, in the resulting search space, the
small \(h\) values are finer-grained (e.g., \(\lfloor 1/498 \rfloor \) vs. \(\lfloor 1/499 \rfloor \)) than the higher ones (e.g., \(\lfloor 1/2 \rfloor \) vs. \(\lfloor 1/3 \rfloor \)). That is why
MADD will look like a step function with respect to \(h\) (see Figures 9 and 10), since the
MADD value changes only when the value of \(h\) is derived from a distinct number of bins
\(m\).
4.3.2. Description
We now describe Algorithm 1 that we designed to perform the optimal bandwidth interval search defined above. Firstly, in lines 2-6, we take as inputs the list of \(h\) values to look for the stable interval, then the corresponding MADD values for each \(h\), the number of individuals in both groups \(G_0\) and \(G_1\), \(nbPointsMin\) set to 50 and \(percent\) set to 0.45 by default, as said in the previous part 4.3.1. After that, in lines 12 to 14, we initialize the variables to be updated during the search, and in lines 15 and 16, we compute the \(order\) as defined as \(h_{sup}\) based on Theorem 2, and infer \(intervalLengthMin\) from it.
Secondly, from lines 18 to 37, we start the search by delimiting an eligible interval with its left index \(i\) and its right index \(j\) (there are two “for” loops over \(i\) and \(j\) respectively). In line 21, if its lower bound, derived from the left index \(i\) (\(Lh[i]\) line 19), is already too large, the desired minimal length of the interval cannot be achieved and the loop stops (lines 21-23). Otherwise, between lines 24-28, we build this interval with an initial length \(intervalLengthMin\) (line 24) and we check if there are enough MADD values (\(nbPointsMin\)) into it (lines 25-26). If not, we extend it to reach \(nbPointsMin\) (line 27). Then, the right index \(j\) moves forward from the end of the considered interval to the end of the list of all possible \(h\) (line 30; \(Lmadd\) contains the same number of elements as \(Lh\)). Thus, all eligible intervals, between \(i\) and \(j\) indexes, are considered, and we compute the standard deviation of MADD values for each of them (lines 30-36). If an interval comes up with a standard deviation smaller than the previously saved one, then we update \(stdMin\) and the \(indexes\) with the information of the newly selected interval. We repeat this process moving forward \(i\) index, too (two “for” loops). This enables to find the most stable interval as defined in the previous part, i.e., with the smallest standard deviation.
At the end of Algorithm 1, we output, as presented in lines 8 to 10, the information about the optimal interval where the stable value of MADD is the best estimate of (un)fairness between the groups \(G_0\) and \(G_1\). In the next Section 4.4, we illustrate the search of optimal bandwidths with simulated data.
4.4. Application with Simulated Data
Here, to showcase the effectiveness of our automated search algorithm and how the theoretical findings can be illustrated (e.g., convergence, order of \(h\)), we run an experiment via simulated data. Here, simulated data allows us to know the expected results so that we can compare these with the results we obtain with our approach, which is not the case in practice. Experiments with real-world data are rather conducted in Section 5 to replicate our previous work (Verger et al., 2023) with optimal bandwidths. After introducing the simulated distributions and the bandwidths we will work with (parts 4.4.1 and 4.4.2), we empirically observe the convergence of MADD in the optimal bandwidth interval (part 4.4.3), and how our automated search algorithm is able to determine the stable MADD value that is the best estimate of the distance between the two distributions (part 4.4.4).
4.4.1. Simulated data
We simulate \((\hat {p}_i)_{i \in G_0}\) and \((\hat {p}_i)_{i \in G_1}\) as if they have been obtained from the output of a classifier. Let \((\hat {p}_i)_{i \in G_0}\) and \((\hat {p}_i)_{i \in G_1}\) be samples of some respective PDFs \(f^{G_0}\) and \(f^{G_1}\). We choose two arbitrary PDFs \(f^{G_0}\) and \(f^{G_1}\) so as to simulate a scenario where the model tends to give higher probabilities to the group \(G_1\) over the group \(G_0\). As displayed in Figure 7a, we define them as part of the gamma distribution \(\Gamma (4,1)\) and the normal distribution \(\mathcal {N}(0.55,1)\) respectively, properly scaled along the x-axis thanks to coefficients \(10\) and \(11\), and normalized within the interval \([0, 1]\):
\begin {equation} \begin {alignedat}{2} f^{G_0}(x) &:= \frac {1}{C_0} f_{\Gamma (4,1)} (11x) \mathds {1}_{[0,1]}(x) &\quad &C_0:=\int _0^1 f_{\Gamma (4,1)} (11x) dx \\ f^{G_1}(x) &:= \frac {1}{C_1} f_{\mathcal {N}(0.55,1)} (10x) \mathds {1}_{[0,1]}(x) &\quad &C_1:=\int _0^1 f_{\mathcal {N}(0.55,1)} (10x) dx \end {alignedat} \end {equation}
Based on the above PDFs, we generate \(10,000\) samples of \({(\hat {p}_i)}_{i \in G_0}\) and \(10,000\) samples of \({(\hat {p}_i)}_{i \in G_1}\), whose vectors \(D_{G_0}\) and \(D_{G_1}\) can be illustrated in Figure 7b.
4.4.2. Bandwidth search space
We compute \(1,000\) values of \(h\) into \((0, 1]\), on the one hand, to examine a large number of them inside the search space to find the optimal ones, and on the other hand, to show that the optimal bandwidth interval can indeed be found before \(h_{sup}\). As highlighted at the end of part 4.3.1, they are not regularly spaced since different \(h\) values could lead to the same number of bins \(m\), and thus create some redundancy in the results. Therefore, we generate \(1,000\) values of \(m\) linearly spaced by 1, and for each of them, we calculate the corresponding \(h\). We remind that, as a consequence, we have many more \(h\) concentrated towards the small values (when \(m\) is higher), which we can see in Figures 9 and 10.
4.4.3. Convergence of MADD and optimal bandwidth interval
Now that we have defined the distributions and the bandwidths of study, our goal is twofold: to observe an effective convergence of MADD (to a specific value), and to verify that the optimal bandwidth interval is indeed situated before \(h_{sup}\), given Theorem 2.
To do so, we analyze the difference between MADD, i.e. \(|| \widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h ||_{L_1[0,1]}\) (as defined in Theorem 1), and the true distance \(|| f^{G_0} - f^{G_1} ||_{L_1[0,1]}\) that MADD is meant to estimate. While we cannot access the latter in practice, here, with simulated data, we can check if MADD indeed converges to the true distance, i.e., if we are able to observe a stable zone of errors between both as well as if this zone is located before \(h_{sup}\).
Let \( A = { \left | \text {MADD}\left (D_{G_0}, D_{G_1}\right ) - || f^{G_0} - f^{G_1} ||_{L_1[0,1]} \right | }\) be the error between MADD and the true distance. We want to observe how \(A\) varies across all \(h\) values to see when \(A\) is the smallest or even null, meaning that MADD best estimates the true distance.
In Figure 8a, we can first see that when \(h\) becomes greater than about \(0.1\), \(A\) increases rapidly. It means that a too large \(h\) leads to inaccurate MADD results. Therefore, it is not advisable to have less than \(m=10\) bins.
If we zoom on the smallest \(h\) values in Figure 8b, we can observe an interval of bandwidths where \(A\) is null, meaning that MADD provides optimal results. This interval, between the green vertical dotted lines, expectedly falls before \(h_{sup}\) which is equal to \(h_{sup} = \left (\frac {100+100}{10000}\right )^{\frac {2}{3}} \approx 0.074\) and illustrated by a red vertical dotted line.


4.4.4. Automated search of optimal bandwidths with our proposed algorithm
Our goal now is to check if our automated search algorithm is able to determine where is the optimal bandwidth interval as well as the stable MADD value (the best estimate of the distance between the two distributions). To do so, we test Algorithm 1 to identify the above-mentioned interval in part 4.4.3, without knowing the exact distance between the distributions via \(A\). We look directly at the MADD results instead of \(A\) as we would do in practice.
Thus, we plot MADD according to the \(h\) values in Figure 10. Then, we use our Algorithm 1 to find the optimal bandwidth interval. We can observe in this figure that MADD converges to a specific value as expected. Our automated search algorithm successfully identified the optimal interval, enclosed between the green vertical dotted lines. In this interval, the average MADD value is \(1.19\), illustrated by a green horizontal dotted line. This value is consequently the most accurate MADD measurement for this simulated scenario, with the distributions displayed in Figure 8.
More precisely, this optimal interval, found by the algorithm, is \(h \in [0.007, 0.040]\) (included before \(h_{sup} \approx 0.074\)). Therefore, a practical bandwidth \(h\) chosen from this interval will provide a stable and accurate MADD value, closest or even equal to the true distance \(\left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]}\). To transition to real data, we will also study the influence of the number of samples or students in a dataset in the next Section 4.5.
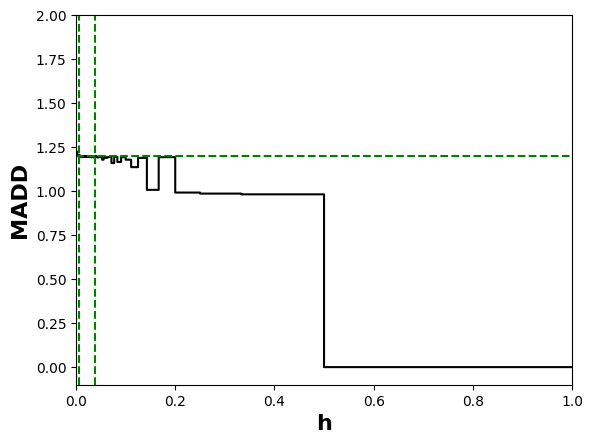
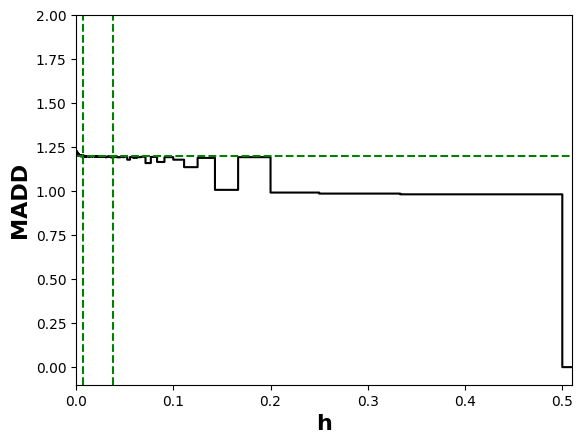
4.5. Influence of the number of samples
Additionally to the bandwidth, we will briefly study the influence of the number of samples on the MADD computation. Not only are the bandwidths important to an accurate measurement, but the number of samples plays a role, too. Indeed, as we saw in Theorem 2, \(h_{sup}\) depends on \(n_0\) and \(n_1\).
Our objective here is to compute the error \(A = \left | \text {MADD}\left (D_{G_0}, D_{G_1}\right ) - || f^{G_0} - f^{G_1} |_{L_1[0,1]} \right |\) according to various sample sizes. We remind that \(n\) is the total number of samples, where \(n = n_0 + n_1\) (Section 3.1). We experiment with various \(n\) values taken from the following set: \(\{ \lfloor \exp (5) \rfloor , \lfloor \exp (5.5) \rfloor , \cdots , \lfloor \exp (14.5) \rfloor \}\), as shown on the x-axis in Figure 11. We repeat each calculation of \(A\) for each \(n\) 50 times to account for the variability resulting from the sampling of the probabilities that represent the two distributions. In the subsequent paragraphs, we will analyze the case where \(n_0\) and \(n_1\) are balanced as well as the general case where they are unbalanced thanks to theoretical considerations, using optimal \(h\) values for both scenarios.
Firstly, we set a 1:1 ratio for \(n_0\) and \(n_1\) so that \(n_0 = \lfloor n/2 \rfloor \). In Figure 11, the blue solid line represents the error in this scenario. In Figure 10a, we observe a linear decrease in logarithmic error as the logarithmic sample size \(n\) increases. This implies that the accuracy of MADD improves with an increase in \(n\). We plot the actual errors \(A\) without the logarithmic scale in Figure 10b to provide a more intuitive understanding of this trend, the blue solid line converging to a null error. We notice that for a small dataset, when \(n=\lfloor \exp {(6)} \rfloor = 403\), the error is only \(0.08\) (\(4\%\) error). For a small or medium-sized dataset, when \(n=\lfloor \exp {(8)} \rfloor = 2981\), the error is \(0.028\) (\(1\)% error). For larger datasets, the error is nearly zero, indicating that MADD is the most accurate estimate of (un)fairness.
Secondly, for other ratios of \(n_0\) and \(n_1\), i.e., for the most general case, we will take the logarithm of \(\left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}}\) to determine its relationship with \(n\) by linearization (transforming power into multiplicative factor). To do so, we introduce two ratios \(0 < \alpha = n_0/n < 1\) and \(\beta = 1 - \alpha \), and we obtain the following, by substituting \(n_0\) and \(n_1\) by \(\alpha \) and \(\beta \) (see proof in Appendix 10.3):
\begin {equation} \label {eq:logUNDERSCOREcvUNDERSCOREspeed} \log \left ( \left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}} \right ) = -\frac {1}{3} \left ( \frac {\alpha \beta }{1+2\sqrt {\alpha \beta }} \right ) -\frac {1}{3} \log (n) \end {equation}
According to this equation, we see that \(\log \left ( \left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}} \right )\) has a linear relationship with \(\log (n)\) (with a coefficient of \(-1/3\) and an intercept of \(-\frac {1}{3} \left ( \frac {\alpha \beta }{1+2\sqrt {\alpha \beta }} \right )\)). This means that, for any different ratios of \(n_0\) and \(n_1\), we will also observe a linear decrease of the logarithmic errors when \(n\) increases, as the 1:1 ratio scenario. Indeed, we observe the above linear relationship in both Figures 10a and 10b thanks to orange dotted lines, following the trend of the 1:1 scenario.
Moreover, with the two scenarios displayed in the same figure, we can see that when \(n_0\) and \(n_1\) are balanced (blue solid line), MADD converges (to the true distance \(\|f^{G_0} - f^{G_1}\|_{L_1}\)) with even lower errors than the general case in orange dotted lines (the blue line has a better coefficient of \(-0.51 < -1/3\)).
As a summary, MADD is friendly to large but also small datasets, and for different ratios of \(n_0\) and \(n_1\), all the more when the number of samples \(n\) increases.
5. Replication of (Verger et al., 2023) experiments
We now aim to replicate the experiments reported in our previous work, but using the bandwidth search algorithm we proposed above (Algorithm 1) to find the optimal \(h\) values for computing MADD. To do so, we leverage the same dataset that we used in (Verger et al., 2023), namely the Open University Learning Analytics Dataset (OULAD) (Kuzilek et al., 2017). In Section 5.1, we will first provide a high-level description of the experimental setup. Further information about the choices of the data and models can be found in (Verger et al., 2023). Then, in Sections 5.2 and 5.3, we will present the updated results.
5.1. OULAD Dataset and Models
The dataset we used in our study is sourced from The Open University, a distance-learning institution based in the United Kingdom, and concerns student activity and demographics between 2013 and 2014. Notably, the dataset includes information on at least three sensitive features, namely gender, poverty, and disability (see Table 1). Our research aims to evaluate the fairness of classifiers that predict whether a student will pass or fail a course, using this data. As in (Verger et al., 2023), among the seven courses provided in the OULAD dataset, we chose two specific courses, labeled as “BBB” and “FFF”, with a total of \(7,903\) and \(7,758\) enrolled students, respectively.
In particular, the passing rate in these two courses was to some extent correlated with the gender feature. Thus, they were good candidates for examining the impact of gender bias on the predictive models’ fairness. Moreover, the “BBB” course corresponds to a Social Sciences course and the “FFF” course to a STEM (Science, Technology, Engineering, and Mathematics) course, making them relevant candidates for examining the impact of gender bias on the predictive models’ fairness on two different student populations. In addition, both courses presented very high imbalances in terms of disability (respectively \(91.2\)-\(8.8\)% and \(91.7\)-\(8.3\)% for the not disable-disable groups in courses “BBB” and “FFF”) and gender (respectively \(88.4\)-\(11.6\)% and \(17.8\)-\(82.2\)% for female-male groups in courses “BBB” and “FFF”), and still some imbalance for poverty (respectively \(42.3\)-\(57.7\)% and \(46.9\)-\(53.1\)% for less-more deprived groups in courses “BBB” and “FFF”). Based on these preliminary unfairness expectations derived from the skews in the data, it is interesting to analyze whether and how the models will suffer from these biases in both courses. Indeed, by nature, imbalanced data means there is less representation of the minority groups, making it harder to train a ML model from them than from the majority group. It is therefore a plausible initial hypothesis that the models trained here may lead to a higher error rate for the minority groups.
The features we use to predict whether a student will pass or fail a course are displayed in Table 1.
Regarding the three sensitive features considered in this study, it is questionable to use demographic
information during training (Baker et al., 2023), but since we precisely want to
understand how these sensitive features play a role in the models’ outcomes, we kept them. The
sum_click feature was the only one that was not immediately available as is, and we computed it
from inner joins and aggregation on the original data. Then, we learn out-of-the-box classifiers on this
data, using a \(70\)-\(30\)% split ratio between the training and the test sets. We use the exact same classifiers as in
(Verger et al., 2023) for the sake of comparison, namely a logistic regression classifier
(LR), a k-nearest neighbors classifier (KN), a decision tree classifier (DT), and a naive Bayes classifier
(NB).
The accuracy of the trained classifiers was above a majority-class baseline (\(70\)%), and up to \(93\)% for DT, except for the NB (\(62\)%) which instead presented interesting behaviors in the previous analyses and was deemed worth keeping it. It is important to note that our experiments focused on analyzing fairness in widely used models rather than solely achieving optimal predictive performance, which is typically the goal of most ML studies. Thus, in a practical application, the initial aim would be to find models with acceptable predictive performance and subsequently use the MADD method to select the fairest options from that set.
To compute MADD, we use the bandwidth search algorithm we proposed (Algorithm 1) to find the optimal \(h\) values for each combination of models and demographics in both “BBB” and “FFF” courses, i.e., for every measurement. This approach not only demonstrates the practical application of our search algorithm in real-world educational data but also enables us to compare MADD results when using an optimal bandwidth vs. a predefined one, as previously done in (Verger et al., 2023). We remind that, in our previous work, the bandwidth parameter was arbitrarily set to \(0.01\), corresponding to a variation of the probability of success or failure of \(1\)%.
| Name | Feature type | Description |
|---|---|---|
gender\(^*\) | binary | students’ gender |
age | ordinal | the interval of students’ age |
disability\(^*\) | binary | indicates whether students have declared a disability |
highest_education | ordinal | the highest student education level on entry to the course |
poverty\(^*\)4 | ordinal | specifies the Index of Multiple Deprivation (Kuzilek et al., 2017) band of the place where students lived during the course |
num_of_prev_attempts | numerical | the number of times students have attempted the course |
studied_credits | numerical | the total number of credits for the course students are currently studying |
sum_click | numerical | the total number of times students interacted with the material of the course |
5.2. Results for Course “BBB"
We present both the MADD results previously obtained from (Verger et al., 2023), in Table 2, and the updated MADD results computed with optimal bandwidths, in Table 3. We highlight in bold, in the latter table, the MADD results that do not change after the optimal computation, and we add for each measurement its corresponding optimal bandwidth interval.
|
Model | Sensitive features | ||||
gender | poverty | disability | Average | ||
|
MADD | LR | 1.72 | 1.85 | 1.57 | 1.71 |
| KN | 1.13 | 1.12 | 0.93 | 1.06 | |
| DT | 0.69 | 0.85 | 0.65 | 0.73 | |
| NB | 0.52 | 0.9 | 1.37 | 0.93 | |
| Average | 1.02 | 1.18 | 1.13 | ||
Comparing Tables 2 and 3, we see that 7 of the 12 MADD values are identical, in particular for the KN and DT models. Indeed, these models, by definition of their inner workings, already output only a few discrete values of possible predicted probabilities (see Figures 4 and 5 from (Verger et al., 2023) as examples). In the case of the KN model, it does not inherently provide a continuous probability distribution, as the predicted probability for a class is based only on the proportion of neighbors belonging to that class within the local neighborhood. In the case of the DT model, its predictions are inherently discrete and simply cannot provide a continuous probability distribution. Therefore, their MADD values are extremely stable for any number of bins \(m\) and thus for any \(h\) values, which is shown in Figure 12. As for the 5 other MADD values that are not identical to the previous results, they are on average \(1.3\)% different (\(0.026\) error on average), which is very low. This is due to the fact that even when it was not inside the optimal bandwidth interval, the \(h\) value empirically chosen in that paper was always very close to it.
These results show not only that the conclusions from (Verger et al., 2023) still hold, but also that we can now safely exclude that a poor choice of \(h\) might have unfairly and artificially increased the MADD value for one of the tested classifiers. In particular, while we expected that gender and disability would generate more algorithmic unfairness as discussed above (Section 5.1), MADD is actually the worst for poverty on average (\(1.17\), see Table 3). Furthermore, trained on the same data, the models exhibit different levels of algorithmic unfairness (e.g., NB is the most fair for gender whereas DT and KN are the most fair for disability). This does confirm the need to investigate and compare systematically the fairness of different models on a given dataset.
As for the search algorithm, Figure 12 also shows that for classifiers like DT and KN that output a few discrete probabilities (e.g., \(0\), \(0.5\), and \(1\) for DT), it is rather trivial to find an optimal \(h\). Thus, for completeness, we also showcase in Figure 13 the output of Algorithm 1 on the LR classifier that provides more continuous probabilities. Figure 13 shows similar findings than with the simulated data above, confirming that the algorithm can effectively identify the optimal bandwidth intervals with real-world data, too.
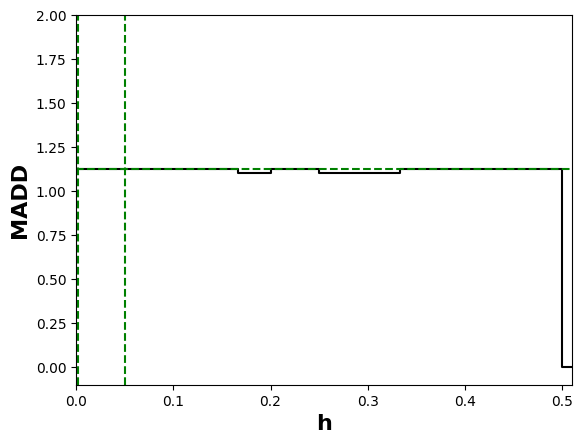
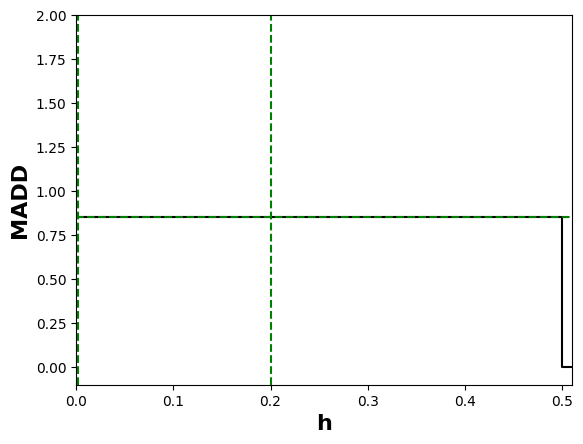
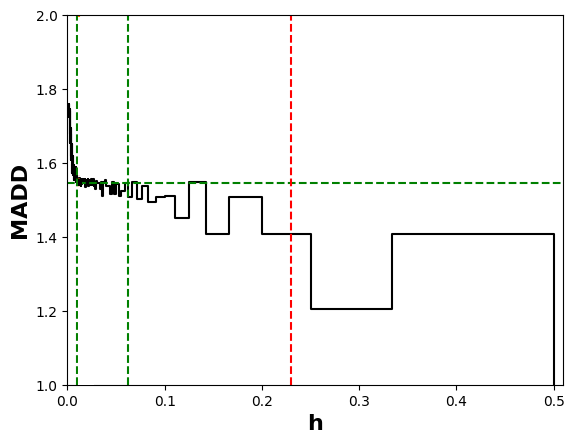
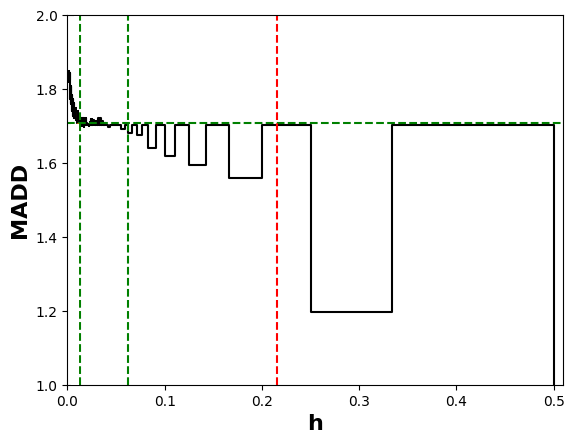

5.3. Results for Course “FFF"
For this course, we present the previous results in Table 4 and the current results in Table 5. Again, we highlight in bold, in the latter table, the results that do not change after choosing an \(h\) value within the optimal bandwidth intervals. We see that 6 of the 12 MADD values are identical, again for the KN and DT models for the same reason as previously. For the other 6 values, they are on average \(3.5\)% different (\(0.07\) error on average), which is still quite low and therefore does not jeopardize the conclusions drawn from experiments described in (Verger et al., 2023).
Our algorithm thus obtains successful results also for real-world educational data, where the number of samples in the dataset is limited (\(1,590\) and \(1,422\) in the respective test sets of the courses “BBB” and “FFF”) and the types of distributions scattered compared to simulated data. Now, in the next Section 6, we will demonstrate how MADD can be used not only to measure unfairness, but also to mitigate it through post-processing of the model output while preserving its accuracy as much as possible.
|
Model | Sensitive features | ||||
gender | poverty | disability | Average | ||
|
MADD | LR | 1.18 | 1.06 | 1.12 | 1.12 |
| KN | 1.06 | 0.93 | 0.78 | 0.92 | |
| DT | 0.76 | 0.65 | 0.55 | 0.65 | |
| NB | 0.56 | 0.47 | 0.90 | 0.64 | |
| Average | 0.89 | 0.78 | 0.84 | ||
6. Improving fairness with MADD
In this Section 6, we propose to use the MADD metric to mitigate algorithmic unfairness. To do so, we develop a post-processing method based on MADD, which modifies the initial predicted probabilities of a model to fairer probabilities and thus predictions.
6.1. The MADD Post-Processing Approach
6.1.1. Purpose
As introduced in Section 3, the closer MADD is to 0, the fairer the outcome of the model is (w.r.t to attribute \(S\)), since the distributions of predicted probabilities are no longer distinguishable regarding the group membership (\(G_0\) or \(G_1\)). Thus, to illustrate how the post-processing with MADD would work, we consider a toy example with a model that tends to give higher predicted probabilities (i.e., probabilities of success predictions) to a group than to the other, as shown in Figure 13a. Therefore, the goal of the MADD post-processing is to reduce the gaps between the distributions of both groups, to obtain a result similar to what we can observe in Figure 13b.
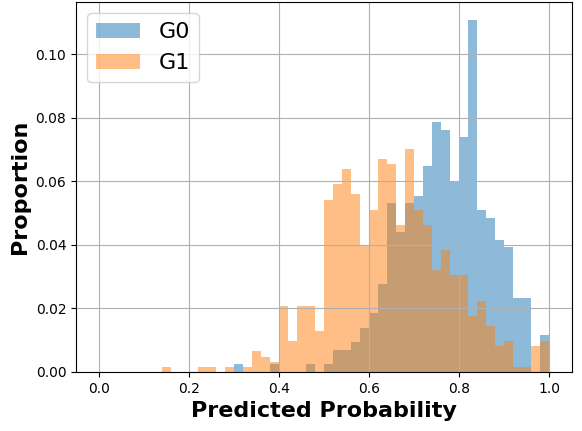
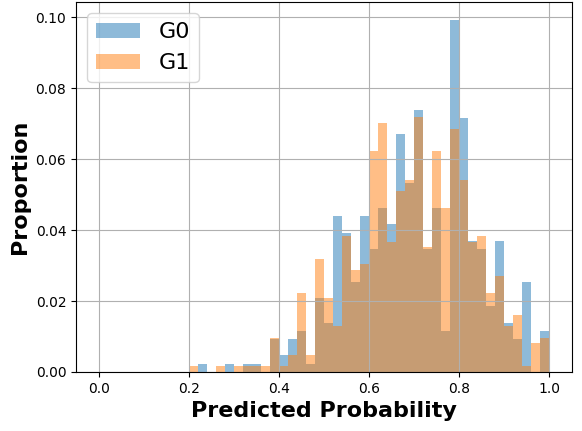
6.1.2. Approach
Following up on the previous part, a question can be raised: where should the two distributions coincide? Indeed, should the distribution of \(G_1\) move to the one of \(G_0\), or is there a better location between the two? To solve this issue, let us first note as \(D\) the distribution related to all students, composed of students from both groups \(G_0\) and \(G_1\) (see the black histogram in Figure 14a). In machine learning, the goal for a model is to approximate the “true” relationship (or prediction function \(\mathcal {X} \rightarrow \mathcal {Y}\)) between the attributes \(X\) in input and the target variable \(Y\) in output. As a consequence, we assume that a model that shows satisfying predictive performance outputs a discrete distribution \(D\) which should be really close to \(\mathcal {D}\), its “true” distribution (see the black line in Figure 14a). Therefore, assuming having such a model, our goal is to make the distributions \(D_{G_0}\) and \(D_{G_1}\) coincide at the place of \(D\), which should best approximate \(\mathcal {D}\). Indeed, this allows both to reduce the gaps between the two groups, hence improving fairness and preventing a loss in predictive performance. Therefore, the MADD post-processing is based on the following theoretical considerations.
As seen earlier in part 4.2.1, since \(D\), \(D_{G_0}\) and \(D_{G_1}\) correspond to histograms, they can be mathematically considered as estimators of the PDFs they describe (see Figure 6) (Devroye and Gyorfi, 1985) and noted as \(f\), \(f^{G_0}\) and \(f^{G_1}\) respectively. We thus want \(f^{G_0}\) and \(f^{G_1}\) to move towards the target \(f\), as the intuition was given in the previous paragraph. To define how these functions should get closer, we define the new theoretical PDFs \(\widetilde {f}\), \(\widetilde {f}^{G_0}\) and \(\widetilde {f}^{G_1}\) that will be estimated thanks to the post-processing. Thus, \(f, f^{G_0}\), \(f^{G_1}\), \(\widetilde {f}^{G_0}\), and \(\widetilde {f}^{G_1}\) should be colinear (see Figure 14b for an illustration and see proof in Appendix 10.4). As a consequence, the ratio between \(\widetilde {f}^{G_0}\) and \(f\) and between \(\widetilde {f}^{G_1}\) and \(f\) remains constant (as shown in Figure 14b), which prevents improving fairness more for one group than for the other. By introducing a \(\lambda \) parameter, that we call fairness coefficient of distribution convergence, such that: \begin {align} \widetilde {f}^{G_0} = (1-\lambda ) f^{G_0} + \lambda f \label {eq:2} \\ \widetilde {f}^{G_1} = (1-\lambda ) f^{G_1} + \lambda f \label {eq:3} \end {align}
\(\lambda \) can be seen as a distance ratio (see Figure 14b) so that \(\lambda \in [0, 1]\), with \(\lambda = 0\) when the PDFs of \(G_0\) and \(G_1\) are at their
initial state and \(\lambda = 1\) when they both coincide. \(\lambda \) between 0 and 1 means that the distributions are getting
closer (see discrete examples of distribution convergence in Figure 17, later). The challenge is to find
the highest \(\lambda \) possible that best improves the fairness without affecting the accuracy of the results.
However, in practice, as we do not know the true \(f\), \(f^{G_0}\) and \(f^{G_1}\), we cannot directly compute \(\widetilde {f}\), \(\widetilde {f}^{G_0}\) and \(\widetilde {f}^{G_1}\) as written in
Equations \eqref{eq:2} and \eqref{eq:3} with different values of \(\lambda \). That is why we introduce fip in
the next part.
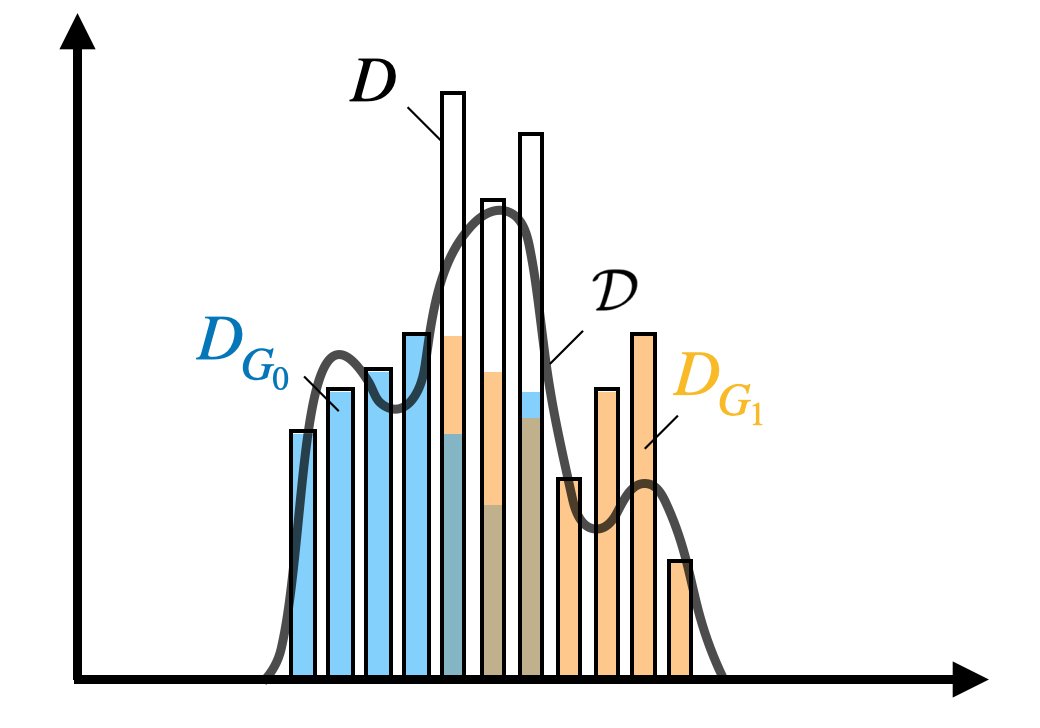

6.1.3. Implementation
We will generate a mapping function5,
fairness_improved_prediction or in short fip, between the discrete estimates of \(f\), \(f^{G_0}\), \(f^{G_1}\) (i.e. \(D\), \(D_{G_0}\), \(D_{G_1}\))
and the discrete estimates of \(\widetilde {f}\), \(\widetilde {f}^{G_0}\), \(\widetilde {f}^{G_1}\) that we will note as \(\overline {D}\), \(\overline {D}_{G_0}\), \(\overline {D}_{G_1}\). The purpose of fip is more precisely to take as
inputs the \(\hat {p}_i\) available at the output of a trained model and a value of \(\lambda \), and to output the new fairer
predicted probabilities that we note as \(\overline {p}_{i}^{(\lambda )}\) (fip: \((\hat {p}_i\), \(\lambda )\) \(\mapsto \) \(\overline {p}_{i}^{(\lambda )}\)). Consequently, \(\overline {p}_{i}^{(\lambda )}\) will allow to reconstruct the new \(\overline {D}_{G_0}\) and
\(\overline {D}_{G_1}\), as shown in Figure 13b.
fip will be generated as follows. Let us focus on the group \(G_0\) first. As we want the proportions of
students having the same predicted probabilities to be kept even if the predicted probabilities values are
changing with the post-processing, we will seek to make the cumulative density function (CDF) of the
initial \(\hat {p}_i\) of group \(G_0\) being equal to the CDF of the new \(\overline {p}_{i}^{(\lambda )}\) of group \(G_0\). Thus, it comes that (see proof in
Appendix 10.5):
\begin {alignat} {2} & &\operatorname {CDF}_{G_0}(\hat {p}_{i}) &= \overline {\operatorname {CDF}}_{G_0}^{(\lambda )}\left (\overline {p}_{i}^{(\lambda )}\right ) \label {eq:7}\\ &\Longrightarrow &\overline {p}_{i}^{(\lambda )} &= \overline {\operatorname {CDF}}_{G_0}^{-1(\lambda )}(\operatorname {CDF}_{G_0}(\hat {p}_{i})) \label {eq:8} \end {alignat}
where \(\overline {\operatorname {CDF}}_{G_0}^{(\lambda )} = (1-\lambda )\operatorname {CDF}_{G_0} + \lambda \operatorname {CDF}\), and \(\overline {\operatorname {CDF}}_{G_0}^{-1(\lambda )}\) is the general inverse function of \(\overline {\operatorname {CDF}}_{G_0}^{(\lambda )}\). We will have the same equations for the group \(G_1\). In the
end, what we do is to compute the different \(\operatorname {CDF}\)s and \(\overline {\operatorname {CDF}}\)s thanks to interp1d and cumtrapz Python
functions from scipy library that estimate their “true” equivalents based on the discrete values of \(\hat {p}_i\) we
have access to, which gives us the core of our fip mapping function. Now that we have the ability to
compute the \(\overline {p}_{i}^{(\lambda )}\), let us define an objective function based on both the accuracy and the fairness of the new
fairer predicted probability results which depend on \(\lambda \), to evaluate the outcome of our MADD
post-processing method.
6.1.4. Objective function
Similarly to existing balancing methods between accuracy and penalty values, we define the general objective function as follows:
\begin {equation} \mathcal {L} = (1-\theta ) \operatorname {AccuracyLoss}(\lambda ) + \theta \operatorname {FairnessLoss}(\lambda ) \end {equation}
where \(\theta \in [0, 1]\) represents the importance of the accuracy and the fairness in the objective function. Indeed, a larger \(\theta \) puts more emphasis on fairness, while a smaller \(\theta \) favors accuracy. The value of \(\theta \) could be set by an expert depending on what one wants to put more emphasis on, or experimentally determined like what we do with \(\lambda \) in part 6.3.1. The \(\operatorname {AccuracyLoss}(\lambda )\), compatible with any common loss functions \(\ell \) (e.g., binary cross-entropy loss), and the \(\operatorname {FairnessLoss}(\lambda )\) could be, as an example, written as:
\begin {align} \operatorname {AccuracyLoss}(\lambda ) &= \frac {1}{n} \sum _{i=1}^n \ell \left (\overline {p}_{i}^{(\lambda )}, y_i \right ) \\ \operatorname {FairnessLoss}(\lambda ) &= \operatorname {MADD}\left (\overline {D}_{G_0}, \overline {D}_{G_1}\right ) \end {align}
However, since the two losses may vary across different scales of values, one should pay particular attention to the choice of \(\ell \) and the way of rescaling both losses to balance them effectively. We will show an example in part 6.2.2.
6.2. Experiments set up
6.2.1. Workflow
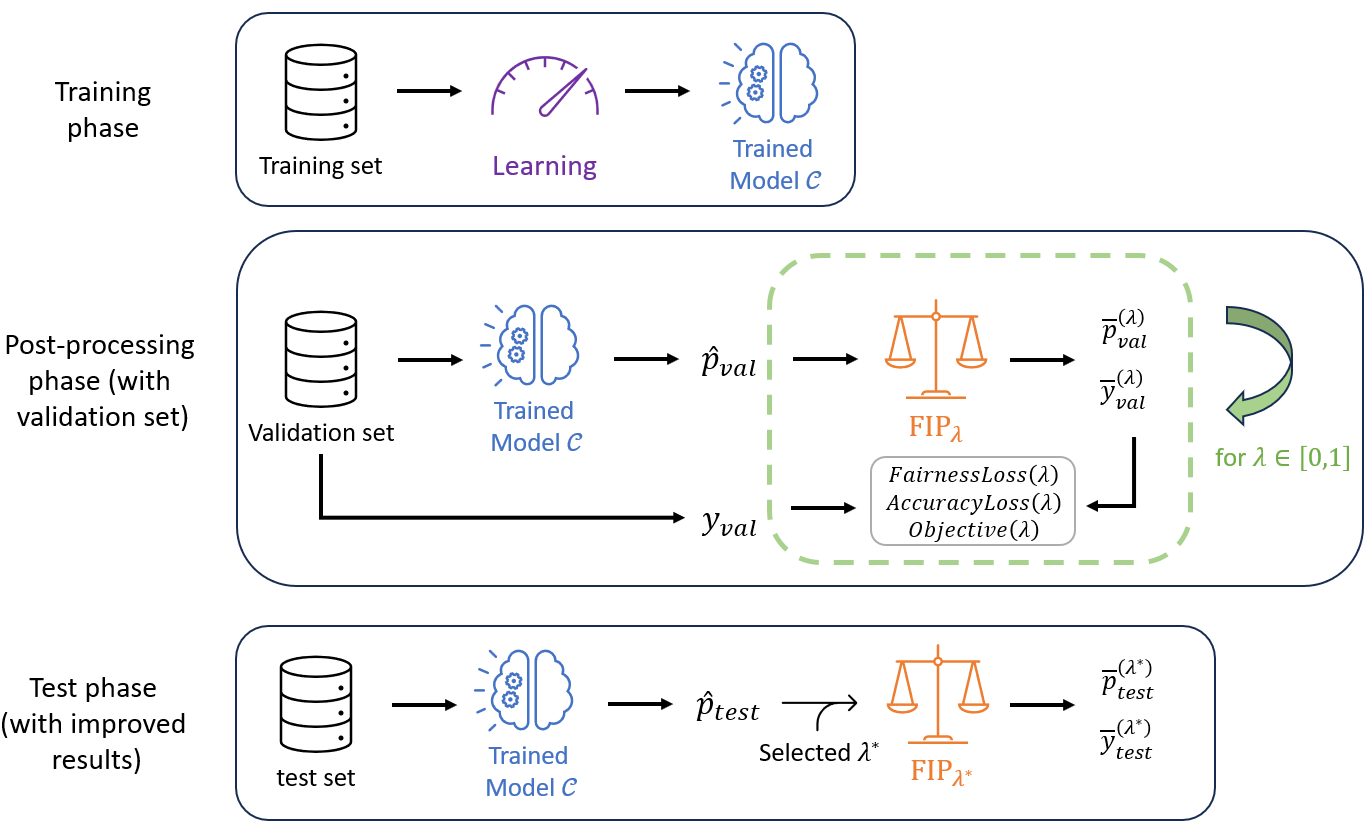
Our MADD post-processing method, illustrated in Figure 16, can be applied for a fixed \(\theta \)
as follows. Let us have a training, a validation and a test sets. We first train a classifier.
Then, we use this trained model on the validation set to output the predictions \(\hat {y}_{i,{validation}}\) and predicted
probabilities \(\hat {p}_{i,{validation}}\). Next, we apply our fip mapping function with various values of \(\lambda \) to obtain different
corresponding \(\overline {p}_{i,{validation}}^{(\lambda )}\). We will thus deduce the new \(\overline {y}_{i,{validation}}^{(\lambda )}\) thanks to the classification threshold \(t\). Now, with
the new \(\overline {p}_{i,{validation}}^{(\lambda )}\), \(\overline {y}_{i,{validation}}^{(\lambda )}\) and the true labels \(y_{i,{validation}}\), we can plot the results of our objective function depending
on the \(\lambda \)s to find the optimal \(\lambda ^{*}\) that will best improve the results of the classifier. Finally, we
evaluate the accuracy and the fairness of the results with the chosen \(\lambda ^{*}\) on the test set (i.e., with \(\overline {p}_{i,{test}}^{(\lambda ^*)})\), \(\overline {y}_{i,{test}}^{(\lambda ^{*})}\)
and the true labels \(y_{i,{test}}\)). For the sake of simplification, in the experiments we omit training,
validation and test subscripts from the notations, but they will be easily deduced from the
context.
6.2.2. Rescaled objective function
For our experiments, we use the objective function that we named \(\mathcal {L}_{exp}\) composed of the rescaled terms we define in Equations \eqref{eq:9}6 and \eqref{eq:10}. Notably, we multiply MADD by \(1/2\) for the term \(\operatorname {FairnessLoss}_{exp}\) to be in the same scale of the one of \(\operatorname {AccuracyLoss}_{exp}\). Therefore, both losses have a range of \([0, 100\%]\). The \(\operatorname {AccuracyLoss}_{exp}(\lambda )\) is the percentage of incorrect predictions, and the \(\operatorname {FairnessLoss}_{exp}(\lambda )\) now represents a percentage of dissimilarity between the two distributions. Thus, the resulting objective function \(\mathcal {L}_{exp}\) is a weighted average of these two losses based on their importance. However, as a case study, we choose to give, in all our experiments, the same importance both to the accuracy and the fairness in the post-processing, so we fix \(\theta = 0.5\). Additionally, it is important to note that in the case of this \(\operatorname {AccuracyLoss}_{exp}(\lambda )\), it exactly corresponds to 1 minus the standard accuracy score, which we will exploit in our results in Section 6.3. Our goal will be to experimentally find the optimal parameter \(\lambda ^*\) that minimizes this objective function \(\mathcal {L}_{exp}\), with \(\theta = 0.5\).
\begin {align} \operatorname {AccuracyLoss}_{exp}(\lambda ) &= \frac {1}{n} \sum _{i=1}^n \mathds {1}_{y_i \neq \overline {y}_i} \label {eq:9} \\ \operatorname {FairnessLoss}_{exp}(\lambda ) &= \frac {1}{2} \text {MADD}\left (\overline {D}_{G_0}, \overline {D}_{G_1}\right ) \label {eq:10} \end {align}
6.2.3. Simulated data
To demonstrate the validity of our approach, we first experiment with our MADD post-processing method on simulated data of \(\hat {p}_i\) for which we know the real distributions. We thus use the same simulated data that we presented in Section 4.4, and we refer the reader to this part for the details of how it has been generated.
Additionally to Section 4.4, we need here to simulate the true label \(y_i\) for each student \(i\). This will enable us to simulate how a classifier would perform before the post-processing, to compare its results with those obtained after the post-processing. The latter are thus deduced from the classification threshold parameter \(t\) that we set to 0.5 in this paper, and we refer the reader to the footnote 6. Thus, for the simulated \(y_i\), we arbitrarily choose to pass the simulated \(\hat {p}_i\) value as a parameter of a Bernoulli law: Bernoulli(\(\hat {p}_i\)) \(\in \left \{0, 1\right \}\).
6.2.4. Real-world educational data
As a second testbed for our approach, we use it with real-world educational data. Again, we use the data we already presented in Section 5. Since \(S = \text {poverty}\) obtained the highest MADD value in the course “BBB” (see Table 3), it is thus a relevant feature with respect to which it is interesting to improve fairness. It is worth noticing that as we split the data in a different way to have an additional validation set, it leads to slightly different distributions in the current test set from what was previously obtained.
6.3. Results
6.3.1. Simulated data
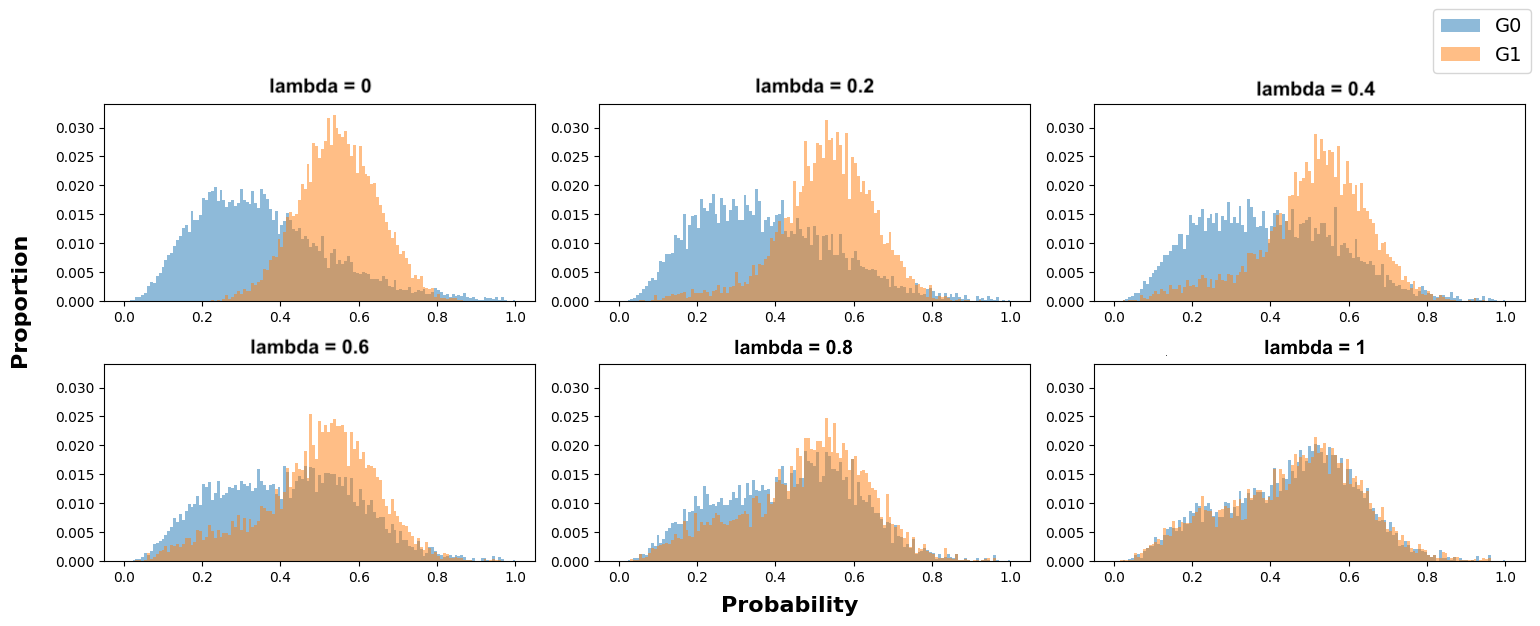
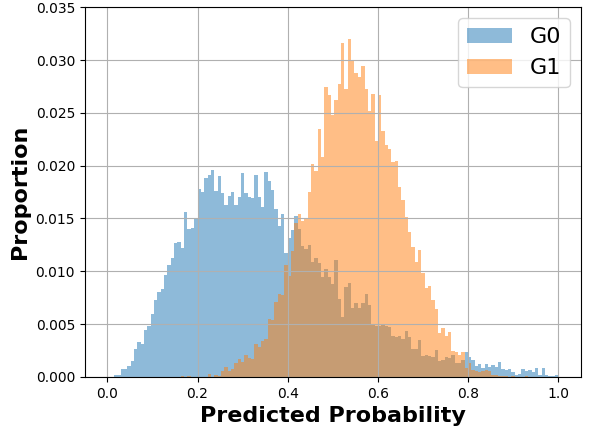
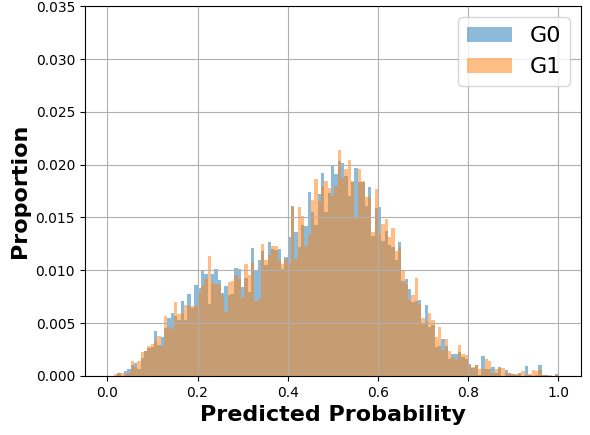
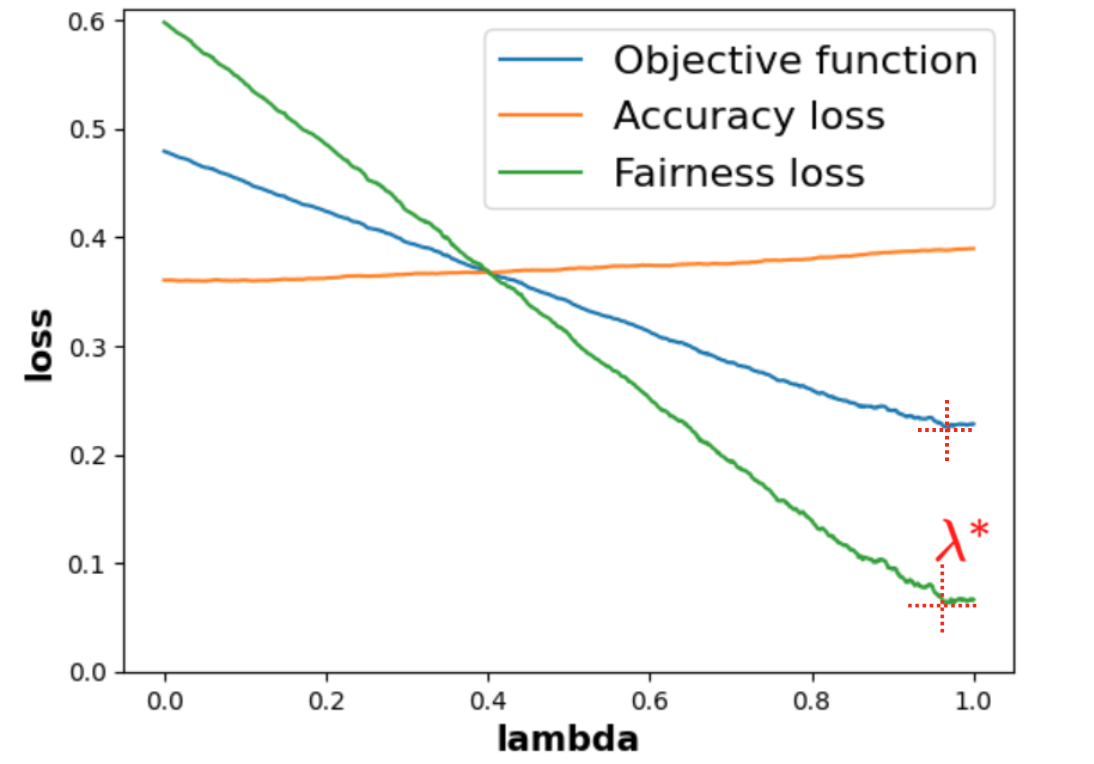
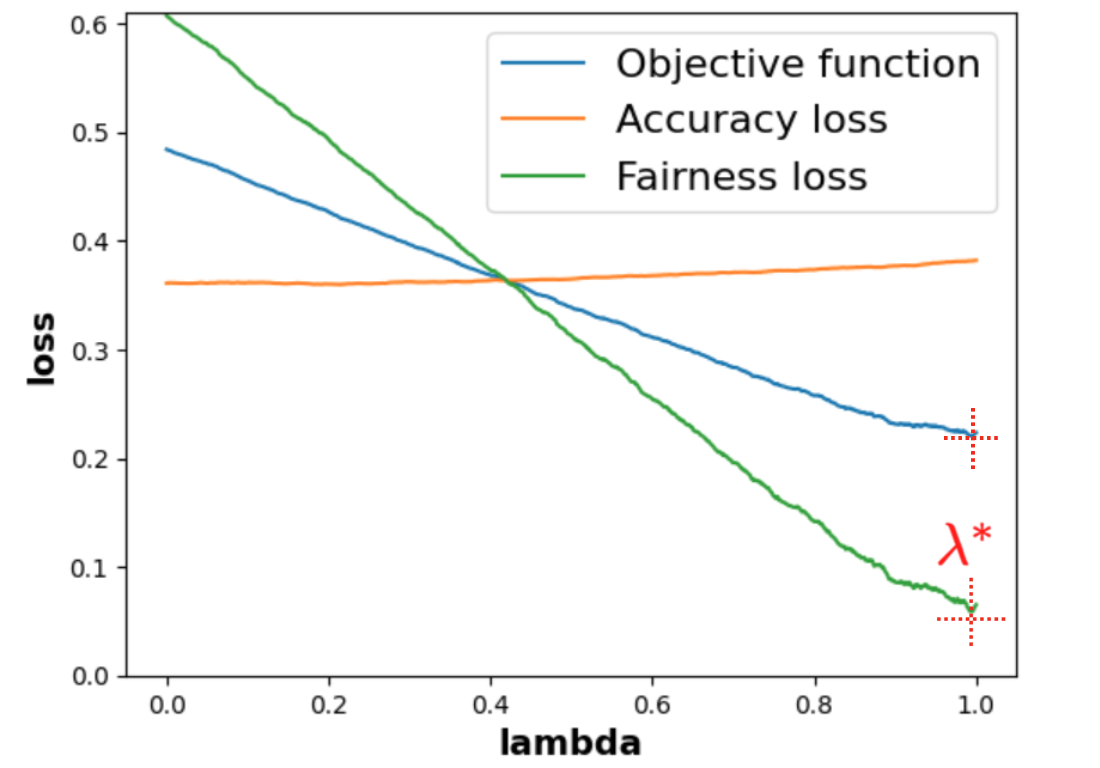
Figure 18: Simulated data results. (a) Histograms of \(D_{G_0}\) and \(D_{G_1}\) from simulated \(\hat {p}_{i \in G_0}\) and \(\hat {p}_{i \in G_1}\). (b) Histograms of the new \(\overline {D}_{G_0}\) and \(\overline {D}_{G_1}\). (c, d) Objective function (total loss), accuracy loss and fairness loss.
We generate \(1,000\) values of \(\lambda \) with a constant step in its interval \([0,1]\), and then we compute all the
corresponding \(\overline {p}_i(\lambda )\), in order to obtain the relationships between the next three \(\mathcal {L}_{exp}\), \(\operatorname {AccuracyLoss}_{exp}(\lambda )\), \(\operatorname {FairnessLoss}_{exp}(\lambda )\) and \(\lambda \). In Figure 17, we
present how the new predicted probabilities progress with some increasing values of \(\lambda \). In Figure 17c,
we display for all values of \(\lambda \) the evolution of \(\mathcal {L}_{exp}\), \(\operatorname {AccuracyLoss}_{exp}(\lambda )\) and \(\operatorname {FairnessLoss}_{exp}(\lambda )\). We remind that we set \(\theta = 0.5\) as we decided to give equal
importance to both the accuracy and the fairness in the post-processing. As we can see in Figure 17c,
on the one hand, when \(\lambda \) increases, the accuracy loss increases too (while we want to minimize it), but
only slightly (\(0.361\) to \(0.390\), i.e., about +\(8\)%). On the other hand, the fairness loss, which corresponds to
half of MADD, significantly drops as what we look for (\(0.598\) to its lowest at \(0.063\), i.e. about -\(90\)%). In
addition, the objective function \(\mathcal {L}_{exp}\) reaches its minimum value \(0.226\) at \(\lambda ^{*} = 0.970\), almost 1. Therefore, if we
accept to lose about \(8\)% of accuracy (we can make this interpretation because of how we
defined our \(\operatorname {AccuracyLoss}_{exp}(\lambda )\)), then by choosing \(\lambda ^{*} = 0.970\), we would increase the fairness of the results by \(90\)% w.r.t the
MADD criterion. After that, we only have to pass \(\lambda ^{*} = 0.970\) and the \(\hat {p}_i\) as inputs of fip to obtain our new
fairer predicted probabilities as shown in Figure 17b. We have repeated the simulation by
generating some other random \(10,000\) samples for each group, and the results are very similar
(see Figure 17d), which strengthens the estimation of \(\lambda ^{*}\) being close to \(1\). To conclude, this
experiment, based on a simulated and ideal case study with sufficient data, demonstrates that the
MADD post-processing manages to preserve a reasonably similar level of accuracy while
significantly improving the fairness of the results. Let us now apply it to real-world data in the next
part.
6.3.2. Real-world educational data
Similarly to what was done in the previous section, we display in Figure 18c the evolution of \(\mathcal {L}_{exp}\), \(\operatorname {AccuracyLoss}_{exp}(\lambda )\) and \(\operatorname {FairnessLoss}_{exp}(\lambda )\), for the values of \(\lambda \) we generated in part 6.3.1. When \(\lambda \) increases, the accuracy loss remains almost constant (\(0.332\) to \(0.336\) i.e. about +1%), and the fairness loss significantly drops again (\(0.431\) to its lowest at \(0.158\), i.e. about \(-63\%\)). However, Figure 18c shows a lot more variability than in the previous case study, which comes from the much lower number of samples in the validation set (about \(700\)). This loss in precision makes it more challenging to find an optimal \(\lambda ^{*}\). Indeed, we see that the minimum of the objective function (\(0.241\)) is not necessarily reached at the optimal \(\lambda ^{*}\) (\(0.798\)) because the \(\operatorname {FairnessLoss}(\lambda )\) seems to keep decreasing but the computation is not precise enough. Nonetheless, we select this \(\lambda ^{*} = 0.798\) value to visually evaluate how close or far the results are from satisfying fairness. We can still observe satisfying results from Figures 18a to 18b. To conclude, similarly to ML in general, the MADD post-processing is sensitive to the number of data, but it still shows very successful fairness improvement without losing too much accuracy of the results.
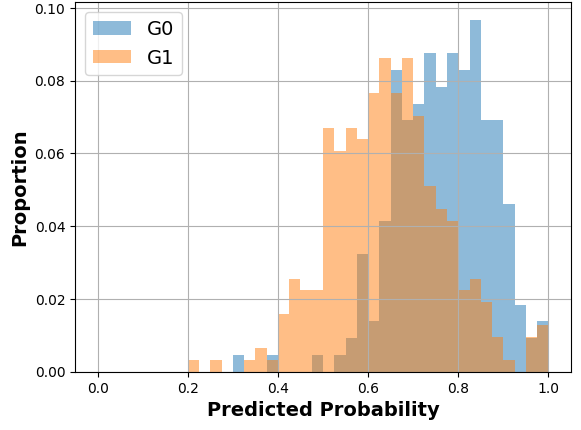
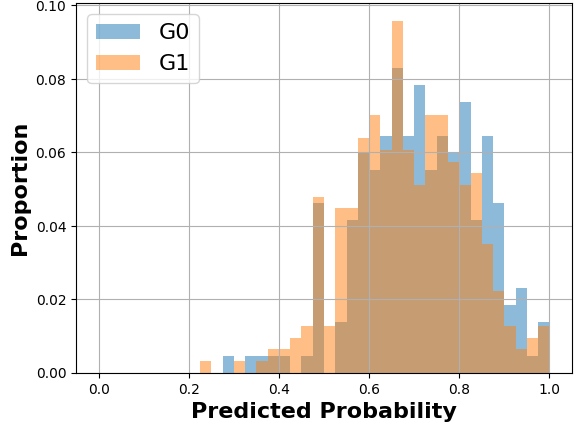
Figure 19: Real-world educational data results.
6.4. Influence of the number of samples
Moreover, thanks to our definition of the post-processing method, the fairness of the improved estimated probabilities is predictable. Indeed, the MADD of the improved estimated probabilities, \(\text {MADD}\left (\overline {D}_{G_0}, \overline {D}_{G_1}\right )\), is a function of \(\lambda \) that converges when the sample size \(n\) increases to \((1 - \lambda ) \cdot \text {MADD}\left ({D}_{G_0}, {D}_{G_1}\right )\). This means that, for any selected \(\lambda \), after post-processing, its new MADD value approximates \((1 - \lambda )\) times the old MADD value, and the larger the sample size \(n\), the more accurate this estimate is. This property is shown in Figure 20: the \(\text {MADD}\left (\overline {D}_{G_0}, \overline {D}_{G_1}\right )\) function converges to the function \((1 - \lambda ) \text {MADD}\left ({D}_{G_0}, {D}_{G_1}\right ) \) as the sample size increases.
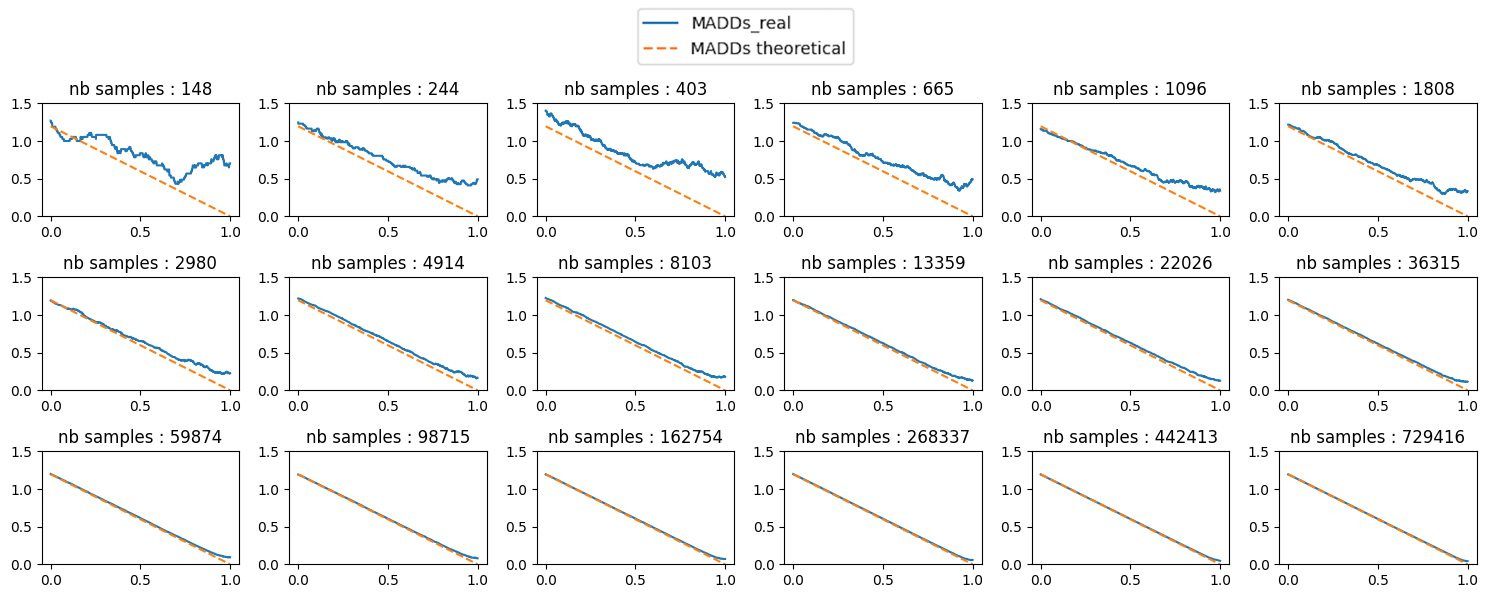
7. Discussion
We now discuss the main implications of our work regarding (1) the MADD metric itself, (2) the fairness evaluation with MADD, and (3) the MADD post-processing.
Firstly, the strengths of MADD consist in taking into account the entire predicted probability distributions compared to existing metrics, and handling any of their forms. It is also an easily interpretable fairness metric, enabling visual analyses through the plot of the two related distributions. On the other hand, a major limitation of MADD in its original version was its sensitivity to its bandwidth parameter (\(h\)) and to the number of samples (\(n\)) contained in a dataset. In this paper, we provided theoretical guarantees and an automated search algorithm to alleviate this issue, by finding optimal bandwidths for which MADD best estimates algorithmic unfairness. This is an important contribution as it ensures the robustness of MADD. Regarding the choice of standard deviation in the automated search algorithm, any other variation metric would have given the same result, since we are looking for the interval where MADD is stable, relatively over the search space, and since any optimal \(h\), and not a single one, is valid in this interval.
In future work, we aim to apply MADD to other educational datasets and predictive tasks, so as to
further assess fairness in other contexts. In line with this, we provided a Python package, maddlib3,
so that other researchers and developers can replicate, assess, and mitigate the fairness of their results
with this metric. Also, MADD currently works for binary groups and binary prediction classes, which,
as said in the introduction, is suitable in many cases as it corresponds in practice to the
main prediction tasks in education. While focusing on binary information has advantages,
including the fact that it makes it possible to plot and interpret MADD easily, other relevant
applications of predictive models in education are not binary, which could be addressed in future
work.
Secondly, regarding fairness evaluation with MADD, we saw that this metric best estimates the distance between the distributions of two groups when \(h\) is carefully chosen into its optimal interval. These optimal \(h\) values mostly depend on the numbers of students belonging to both groups, \(n_0\) and \(n_1\), as explained in Section 4.2. This has two important consequences. First, the optimal interval should be computed for each feature with respect to which we want to evaluate algorithmic unfairness and more specifically for each measurement (model-feature combination). Second, two MADD values should be compared only if they have been computed with an optimal \(h\), otherwise there is no guarantee that both of these values had converged. For instance, if we assume that a given sensitive feature (e.g., gender) leads to a MADD score of \(1.5\) with a model \(\mathcal {M}_1\) trained on a dataset \(d_1\), and a score of \(0.5\) with a model \(\mathcal {M}_2\) trained on a dataset \(d_2\), then we can say that the first setting is more discriminant with regards to this sensitive feature than the second one, provided that MADD was calculated with an optimal \(h\) in both cases.
Although it is essential to choose the right bandwidth \(h\), it is worth emphasizing that performing a
fairness evaluation with MADD does not prevent from evaluating the predictive performance of the
models as well. Indeed, as mentioned in (Verger et al., 2023), a model that shows poor
predictive performance is not necessarily behaving unfairly regarding the studied groups, but it would
then be unable to make relevant predictions for the success or failure of students for instance,
which makes this model not usable in practice. We refer the reader to Section 5.2 of (Verger
et al., 2023) for a comparison with a predictive-performance oriented fairness
metric, ABROCA (Gardner et al., 2019), and the main related takeaways
in part 5.2.3. Furthermore, an extension of MADD would be to generalize its definition
(Equation \eqref{MADDeq}) to take into account the influence of several features on the fairness
evaluation, which is scarcely studied in the literature. Several possibilities exist and will be further
studied in future work.
Thirdly, regarding the mitigation with MADD through post-processing, its performance depends on
the number of samples \(n_0\) and \(n_1\), too. Indeed, the more precise both distributions are, the more likely it is
that the new fairer distributions will reach the target distribution as precisely as possible. Granted that
there is sufficient data, we found that our method can successfully improve the fairness of the results
regarding two groups, without losing too much accuracy. While there is a need to replicate this finding,
it is noteworthy that we could improve the MADD values of some results by up to \(63\)% with real-world
data.
Overall, even if, with MADD or any other metric, we seek to best estimate algorithmic unfairness
and mitigate it, these fairness metrics cannot be the only way to assess the fairness of a system meant
to improve the learning experience or to assist decision making. Indeed, fairness should
be considered as a global notion including the system, with all its components (e.g., data,
models, interfaces), but also its multiple stakeholders (e.g., institutions, students, instructors,
developers, researchers – see Romero and Ventura (2020), Holstein and Doroudi (2021) for a
complete list of them in an educational context – but also policymakers, lawyers, sociologists,
philosophers, etc.). Calvi and Kotzinos (2023) thus paves the way towards a global framework to
reach a higher level of evaluation through an algorithmic impact assessment (AIA) of the
systems. AIAs are meant to be iterative processes used to investigate the possible short and
long-term societal impacts of AI systems before their use, but with ongoing monitoring and
periodic revisiting even after their implementation. Nonetheless, fairness metrics are so far the
most advanced techniques available to evaluate algorithmic fairness (Calvi and Kotzinos,
2023).
8. Conclusion
In this paper, we focused on Model Absolute Density Distance (MADD), a fairness metric we recently proposed (Verger et al., 2023) to measure predictive models’ discriminatory behaviors between groups. This metric is based on comparing the probability distributions outputted by the models for each group, to uncover and measure the difference in these distributions that could reveal unfair predictions.
Specifically, in this paper, we contributed to the work of Verger et al. (2023) in three
ways. First, we provide a more rigorous definition of the MADD metric, based on the mathematical
properties of histogram estimators. This allowed us to provide an algorithm for automatically
optimizing the bandwidth, i.e., the MADD hyperparameter, which in our previous work was arbitrarily
set to a predefined default value (Verger et al., 2023). Second, we provide a method that
leverages MADD to mitigate the algorithmic unfairness of a model without hindering its accuracy, via
post-processing of the probability distributions produced by the model. Third, we developed an
open-source Python package named maddlib3 to facilitate the usage of MADD in future
work.
To evaluate our work, we conducted experiments with both simulated and real-world educational data. In particular, the real-world data came from two online courses, and we studied the fairness of ML classifiers which predicted whether students would pass or fail courses, depending on their demographics and interactions with the course material. Our results did show that trained on the same data, models exhibit different discriminatory behaviors according to different sensitive features, thus generating different levels of unfair predictions. Furthermore, there is no direct relationship between the bias that already exists in the data and the algorithmic unfairness of the models. For instance, we found that in a course, several models exhibited more unfair behaviors for students based on their poverty, whereas the data were actually heavily skewed for gender and disability features (Verger et al., 2023).
Our results show that we can successfully and substantially mitigate the unfair behaviors of the models with our MADD-based post-processing method, without hindering accuracy. This finding is promising for the value of our mitigation approach. The data and code of our experiments are publicly available (see Section 1).
For future work, we plan to further study the value of MADD with other datasets. We also plan to target other predictive tasks commonly used in education, such as predicting students at risk of dropping out of a course, predicting skill acquisition, or predicting scholarship acceptance. As for the MADD metric, we aim to extend it to take into account combinations of features that could generate more unfair predictions than each feature taken separately. This is crucial to account for the fact that membership in several groups can result in unique combinations of discrimination, known as intersectional discrimination. To the best of our knowledge, such studies are still lacking in education, and we initiate a work in this direction.
9. Acknowledgements
This work was supported by Sorbonne Center for Artificial Intelligence (SCAI), and Direction du Numérique Educatif (DNE) of the French Ministry of Education. The views and opinions expressed in this manuscript are those of the authors and do not necessarily reflect those of SCAI and DNE.
References
- Anderson, H., Boodhwani, A., and Baker, R. 2019. Assessing the Fairness of Graduation Predictions. In Proceedings of The 12th International Conference on Educational Data Mining (EDM), C. F. Lynch, A. Merceron, M. Desmarais, and R. Nkambou, Eds. International Educational Data Mining Society, Montreal, Canada, 488–491.
- Baker, R. S., Esbenshade, L., Vitale, J., and Karumbaiah, S. 2023. Using Demographic Data as Predictor Variables: a Questionable Choice. Journal of Educational Data Mining (JEDM) 15, 2 (Jun.), 22–52.
- Baker, R. S. and Hawn, A. 2021. Algorithmic Bias in Education. International Journal of Artificial Intelligence in Education (IJAIED) 32, 4 (Nov.), 1052–1092.
- Barocas, S., Hardt, M., and Narayanan, A. 2019. Fairness and Machine Learning: Limitations
and Opportunities. MIT Press, Cambridge, MA.
http://www.fairmlbook.org. - Bolukbasi, T., Chang, K.-W., Zou, J., Saligrama, V., and Kalai, A. 2016. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), D. D. Lee, M. Sugiyama, U. von Luxburg, I. Guyon, and R. Garnett, Eds. Curran Associates Inc., Barcelona, Spain, 4356––4364.
- Buolamwini, J. and Gebru, T. 2018. Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification. In Proceedings of the 1st Conference on Fairness, Accountability and Transparency (ACM FAccT,). Proceedings of Machine Learning Research, vol. 81. PMLR, New York, NY, USA, 77–91.
- Calvi, A. and Kotzinos, D. 2023. Enhancing AI fairness through impact assessment in the European Union: a legal and computer science perspective. In Proceedings of the 6th Conference on Fairness, Accountability, and Transparency (ACM FAccT). Association for Computing Machinery, Chicago, IL, USA, 1229–1245.
- Castelnovo, A., Crupi, R., Greco, G., Regoli, D., Penco, I. G., and Cosentini, A. C. 2022. A clarification of the nuances in the fairness metrics landscape. Scientific Reports 12, 1–21. Nature Publishing Group.
- Caton, S. and Haas, C. 2024. Fairness in Machine Learning: A Survey. ACM Computing Surveys 56, 7 (Apr.), 1–38.
- Cha, S.-H. and Srihari, S. N. 2002. On measuring the distance between histograms. Pattern Recognition 35, 1355–1370.
- Christie, S. T., Jarratt, D. C., Olson, L. A., and Taijala, T. T. 2019. Machine-Learned School Dropout Early Warning at Scale. In Proceedings of The 12th International Conference on Educational Data Mining (EDM), C. F. Lynch, A. Merceron, M. Desmarais, and R. Nkambou, Eds. International Educational Data Mining Society, Montreal, Canada, 726–731.
- d’Alessandro, B., O’Neil, C., and LaGatta, T. 2017. Conscientious Classification: A Data Scientist’s Guide to Discrimination-Aware Classification. Big Data 5, 2 (Jun.), 120–134.
- Dastin, J. 2018. Amazon scraps secret AI recruiting tool that showed bias against women. Reuters.
https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G. - Deho, O. B., Zhan, C., Li, J., Liu, J., Liu, L., and Duy Le, T. 2022. How do the existing fairness metrics and unfairness mitigation algorithms contribute to ethical learning analytics? British Journal of Educational Technology 53, 4, 822–843.
- Devroye, L. 1986. Non-Uniform Random Variate Generation. Springer, New York, NY.
- Devroye, L. and Gyorfi, L. 1985. Nonparametric Density Estimation: The L1 View. In Wiley Series
in Probability and Statistics. John Wiley and Sons, New York.
https://www.szit.bme.hu/˜gyorfi/L1bookBW.pdf. - Gardner, J., Brooks, C., and Baker, R. 2019. Evaluating the Fairness of Predictive Student Models Through Slicing Analysis. In Proceedings of the 9th International Conference on Learning Analytics & Knowledge. ACM, Tempe AZ USA, p. 225–234.
- Holstein, K. and Doroudi, S. 2021. Equity and Artificial Intelligence in Education: Will “AIEd” Amplify or Alleviate Inequities in Education? CoRR abs/2104.12920.
- Hu, Q. and Rangwala, H. 2020. Towards Fair Educational Data Mining: A Case Study on Detecting At-risk Students. In Proceedings of the 13th International Conference on Educational Data Mining (EDM), A. N. Rafferty, J. Whitehill, V. Cavalli-Sforza, and C. Romero, Eds. International Educational Data Mining Society, Fully virtual, 431–437.
- Hutchinson, B. and Mitchell, M. 2019. 50 Years of Test (Un)fairness: Lessons for Machine Learning. In Proceedings of the 2nd Conference on Fairness, Accountability, and Transparency (ACM FAccT). Association for Computing Machinery, Atlanta GA USA, 49–58.
- Hutt, S., Gardner, M., Duckworth, A. L., and D’Mello, S. K. 2019. Evaluating Fairness and Generalizability in Models Predicting On-Time Graduation from College Applications. In Proceedings of the 12th International Conference on Educational Data Mining (EDM), C. F. Lynch, A. Merceron, M. Desmarais, and R. Nkambou, Eds. International Educational Data Mining Society, Montreal, Canada, 79–88.
- Jiang, W. and Pardos, Z. A. 2021. Towards Equity and Algorithmic Fairness in Student Grade Prediction. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, I. Roll, D. McNamara, S. Sosnovsky, R. Luckin, and V. Dimitrova, Eds. Association for Computing Machinery, New York, NY, USA, 608––617.
- Kai, S., Andres, J. M. L., Paquette, L., Baker, R. S., Molnar, K., Watkins, H., and Moore, M. 2017. Predicting Student Retention from Behavior in an Online Orientation Course. In Proceedings of the 10th International Conference on Educational Data Mining (EDM), X. Hu, T. Barnes, A. Hershkovitz, and L. Paquette, Eds. International Educational Data Mining Society, Wuhan, Hubei, China.
- Kizilcec, R. F. and Lee, H. 2022. Algorithmic Fairness in Education. In Ethics in Artificial Intelligence in Education, W. Holmes and K. Porayska-Pomsta, Eds. Taylor & Francis, New York.
- Kuzilek, J., Hlosta, M., and Zdrahal, Z. 2017. Open University Learning Analytics dataset. Scientific data 4, 1, 1–8.
- Lallé, S., Bouchet, F., Verger, M., and Luengo, V. 2024. Fairness of MOOC Completion Predictions Across Demographics and Contextual Variables. In Proceedings of the 25th International Conference on Artificial Intelligence in Education (AIED). Springer, Recife, Brazil. In press.
- Larson, J., Mattu, S., Kirchner, L., and Angwin, J. 2016.
How We Analyzed the COMPAS Recidivism Algorithm. ProPublica.
https://www.propublica.org/article/how-we-analyzed-the-compas-recidivism-algorithm. - Le Quy, T., Roy, A., Iosifidis, V., Zhang, W., and Ntoutsi, E. 2022. A survey on datasets for fairness-aware machine learning. WIREs Data Mining and Knowledge Discovery 12, 3, e1452.
- Lee, H. and Kizilcec, R. F. 2020. Evaluation of Fairness Trade-offs in Predicting Student Success.
FATED (Fairness, Accountability, and Transparency in Educational Data) Workshop at EDM 2020.
https://doi.org/10.48550/arXiv.2007.00088. - Li, C., Xing, W., and Leite, W. 2021. Yet another predictive model? Fair predictions of students’ learning outcomes in an online math learning platform. In Proceedings of the 11th International Learning Analytics and Knowledge Conference. Association for Computing Machinery, Irvine, CA, USA, 572–578.
- Lopez, P. 2021. Bias does not equal bias: a socio-technical typology of bias in data-based algorithmic systems. Internet Policy Review 10, 4 (Dec.), 1–29.
- Makhlouf, K., Zhioua, S., and Palamidessi, C. 2021. Machine learning fairness notions: Bridging the gap with real-world applications. Information Processing & Management 58, 5 (Sep.), 102642.
- Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., and Galstyan, A. 2022. A Survey on Bias and Fairness in Machine Learning. ACM Computing Surveys 54, 6, 1–35.
- Pessach, D. and Shmueli, E. 2023. Algorithmic Fairness. In Machine Learning for Data Science Handbook: Data Mining and Knowledge Discovery Handbook, L. Rokach, O. Maimon, and E. Shmueli, Eds. Springer, Cham, Switzerland, 867–886.
- Romero, C. and Ventura, S. 2020. Educational data mining and learning analytics: An updated survey. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery 10, 3, e1355.
- Selbst, A. D., Boyd, D., Friedler, S. A., Venkatasubramanian, S., and Vertesi, J. 2019. Fairness and Abstraction in Sociotechnical Systems. In Proceedings of the 2nd Conference on Fairness, Accountability, and Transparency (ACM FAccT). Association for Computing Machinery, Atlanta GA USA, 59–68.
- Sha, L., Rakovic, M., Whitelock-Wainwright, A., Carroll, D., Yew, V. M., Gasevic, D., and Chen, G. 2021. Assessing algorithmic fairness in automatic classifiers of educational forum posts. In Proceedings of the 22nd International Conference on Artificial Intelligence in Education (AIED), I. Roll, D. McNamara, S. Sosnovsky, R. Luckin, and V. Dimitrova, Eds. Springer, Utrecht, The Netherlands, 381–394.
- Sovrano, F., Sapienza, S., Palmirani, M., and Vitali, F. 2022. A Survey on Methods and Metrics for the Assessment of Explainability under the Proposed AI Act. In Legal Knowledge and Information Systems: JURIX 2021: The Thirty-fourth Annual Conference, E. Schweighofer, Ed. IOS Press, Vilnius, Lithuania, 235–242.
- Suresh, H. and Guttag, J. V. 2021. A Framework for Understanding Sources of Harm throughout the Machine Learning Life Cycle. In Proceedings of the 1st ACM Conference on Equity and Access in Algorithms, Mechanisms, and Optimization. Association for Computing Machinery, New York, NY, USA, 1–9.
- Vasquez Verdugo, J., Gitiaux, X., Ortega, C., and Rangwala, H. 2022. FairEd: A Systematic Fairness Analysis Approach Applied in a Higher Educational Context. In LAK22: 12th International Learning Analytics and Knowledge Conference. Association for Computing Machinery, Online USA, 271–281.
- Verger, M., Lallé, S., Bouchet, F., and Luengo, V. 2023. Is Your Model “MADD”? A Novel Metric to Evaluate Algorithmic Fairness for Predictive Student Models. In Proceedings of the 16th International Conference on Educational Data Mining, M. Feng, T. Käser, and P. Talukdar, Eds. International Educational Data Mining Society, Bengaluru, India, 91–102.
- Verma, S. and Rubin, J. S. 2018. Fairness Definitions Explained. In Proceedings of the 2018 IEEE/ACM International Workshop on Software Fairness (FairWare). Association for Computing Machinery, Gothenburg Sweden, 1–7.
- Yu, R., Lee, H., and Kizilcec, R. F. 2021. Should college dropout prediction models include protected attributes? In Proceedings of the Eighth ACM Conference on Learning @ Scale. L@S ’21. Association for Computing Machinery, New York, NY, USA, p. 91–100.
- Yu, R., Li, Q., Fischer, C., Doroudi, S., and Xu, D. 2020. Towards accurate and fair prediction of college success: Evaluating different sources of student data. In Proceedings of The 13th International Conference on Educational Data Mining (EDM), A. N. Rafferty, J. Whitehill, V. Cavalli-Sforza, and C. Romero, Eds. International Educational Data Mining Society, Fully virtual, 292–301.
- Švábenský, V., Verger, M., Rodrigo, M. M. T., Monterozo, C. J. G., Baker, R. S., Saavedra, M. Z. N. L., Lallé, S., and Shimada, A. 2024. Evaluating Algorithmic Bias in Models for Predicting Academic Performance of Filipino Students. In Proceedings of The 17th International Conference on Educational Data Mining (EDM). International Educational Data Mining Society, Atlanta, Georgia, USA. In press.
10. Appendices
10.1. Proof of Theorem 1
Proof. To prove the theorem, we start from the definition of MADD (Equation 3) and the properties of the indicator function (noted \(\mathds {1}\) and defined in Equation \eqref{indicatorUNDERSCOREfunctionUNDERSCOREeq}). Specifically, we have:
\[ \begin {aligned} &\operatorname {MADD}\left (D_{G_0}, D_{G_1}\right ) \\ := &\sum _{k=1}^m\left | d_{G_0, k} - d_{G_1, k} \right | \\ &\text {by definition of $d_{G_0, k}$ and $d_{G_1, k}$ in Equation~\eqref {d-k-def}:}\\ = &\sum _{k=1}^m \left | \frac {1}{n_0} \sum _{i=1}^{n_0} \mathds {1}_{I_k}\left ( \hat {p}_i^{(0)} \right ) - \frac {1}{n_1} \sum _{i=1}^{n_1} \mathds {1}_{I_k}\left ( \hat {p}_i^{(1)} \right ) \right |\\ &\text {by calculating the integral thanks to the definition of the indicator function:}\\ = &\int _0^1 \frac {1}{h} \sum _{k=1}^m \left | \frac {1}{n_0} \sum _{i=1}^{n_0} \mathds {1}_{I_k}\left ( \hat {p}_i^{(0)} \right ) - \frac {1}{n_1} \sum _{i=1}^{n_1} \mathds {1}_{I_k}\left ( \hat {p}_i^{(1)} \right ) \right | \mathds {1}_{I_k}(x) dx\\ &\text {by distributing the indicator function:}\\ =&\int _0^1 \left |\frac {1}{h} \sum _{k=1}^m \left ( \frac {1}{n_0} \sum _{i=1}^{n_0} \mathds {1}_{I_k}\left ( \hat {p}_i^{(0)} \right ) \right ) \mathds {1}_{I_k}(x) - \frac {1}{h} \sum _{k=1}^m \left ( \frac {1}{n_1} \sum _{i=1}^{n_1} \mathds {1}_{I_k}\left ( \hat {p}_i^{(1)} \right ) \right ) \mathds {1}_{I_k}(x) \right | dx \\ &\text {by definition of histogram function (Definition 1):}\\ =&\int _0^1 \left |\widehat {f}^{G_0}_h(x) - \widehat {f}^{G_1}_h(x) \right | dx \\ &\text {by definition of } L_1 \text { distance (Definition 2):}\\ = &\left \|\widehat {f}^{G_0}_h(x) - \widehat {f}^{G_1}_h(x)\right \|_{L_1[0,1]} \end {aligned} \]
10.2. Proof of Theorem 2
We first clarify the conditions required for Theorem 2 to be held. Let us introduce \(\mathcal {F}\), the class of functions satisfying the following conditions for any function \(\xi \in \mathcal {F}\):
-
\(\xi \) has compact support,
-
\(\xi \) is absolutely continuous with derivative \(\xi ^{\prime }\) almost everywhere,
-
\(\xi ^{\prime }\) is bounded and continuous.
Thus, we assume that both PDFs \(f^{G_0}, f^{G_1} \in \mathcal {F}\). Indeed, the first condition is necessarily satisfied since, in our case, the model gives predicted probabilities that are continuous-valued in \([0,1]\) (compact support), and the two other conditions, which are smoothness assumptions, are generally regarded as standard and relatively undemanding requirement in continuous-valued non-parametric estimation (Devroye and Gyorfi, 1985).
Before going into the details of Theorem 2, we introduce some necessary notions. In statistics, the risk often represents the mathematical expectation of the absolute quadratic error between an estimator and its target. Here, the error is the difference between MADD and the true \(\left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]}\). The reason for finding the expectation of this difference is that the samples are random, so the value of MADD will be different for different samples. Thus, the risk of an estimator represents its theoretical mean error. Therefore, we define the risk as follows:
Definition 3 (Risk). \begin {align*} &\mathcal {R}\left ( \operatorname {MADD}\left (D_{G_0}, D_{G_1}\right ), \left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]} \right ) \\ := &\ \mathbb {E}\left [ \left | \operatorname {MADD}\left (D_{G_0}, D_{G_1}\right ) - \left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]} \right | \right ] \end {align*}
For a good estimator, this risk should converge to 0 when the number of samples converges to infinity. Nonetheless, in general, we also need to know how quickly it converges to 0. For example, if the risk of one estimator is \(1/n\), and the risk of another estimator is \(1/n^2 + 1/n^3\), we should choose the second one, even if when \(n=1\), the first risk is smaller than the second, because the second risk converges to 0 more quickly, which means that when \(n\) is sufficiently large, the second risk will be much smaller than the first one. Now, we define the convergence speed formally:
Definition 4 (Convergence speed). For an estimator \(\widehat {\xi }\) and its risk \(\mathcal {R}\left (\widehat {\xi }, \xi \right )\), if there exists a constant \(C>0\) and a positive function \(\psi (n)\) such that \[ \limsup _{n \rightarrow +\infty } \psi (n) \mathcal {R}\left (\widehat {\xi }, \xi \right )=C \] i.e., \(\mathcal {R}\left (\widehat {\xi }, \xi \right ) = O \left ( \psi (n)^{-1} \right )\), then the convergence rate of \(\widehat {\xi }\) is said to be at least of order \(\psi (n)^{-1}\).
Then, for an estimator which needs a parameter \(h\) dynamically chosen according to \(n\), we define the optimal convergence speed as follows:
Definition 5 (Optimal convergence speed). For an estimator \(\widehat {\xi }_h\) and its risk \(\mathcal {R}\left (\widehat {\xi }_h, \xi \right )\), if there exists a constant \(C>0\) and a positive function \(\psi (n)\) such that \[ \limsup _{n \rightarrow +\infty } \inf _{h} \psi (n) \mathcal {R}\left (\widehat {\xi }_h, \xi \right )=C \] then the optimal convergence rate of \(\widehat {\xi }_h\) is said to be at least of order \(\psi (n)^{-1}\).
We also clarified the two following definitions.
Definition 6 (Asymptotic speed upper bound). Let a \(\in \mathbb {R}\). For two functions \(f\) and \(g\), if \(\exists d>0, C>0, \forall x \text { s.t }. |x-a|<d \Rightarrow |f(x)| \leq C|g(x)|\), then we denote \[ f(x)=\underset {x \rightarrow a}{O}(g(x)) \] If \(g\) is non-zero in the neighbourhood of \(a\), is equivalent to say \[ \limsup _{x \rightarrow a}\left |\frac {f(x)}{g(x)}\right |<\infty \]
Definition 7 (Asymptotically negligible). For two positive functions \(f\) and \(g\), if \(\displaystyle \lim _{x \rightarrow a} \frac {f(x)}{g(x)} = 0\), then we denote \[ f(x)=\underset {x \rightarrow a}{o}(g(x)) \] We can say that \(f\) is negligible compared to \(g\). When the context is clear, the subscript \(x \rightarrow a\) below \(O\) and \(o\) can be omitted.
We can now propose a mathematically rigorous version of Theorem 2 as follows using Definition 5:
Theorem 2 (Complete version)_____________________________
If \(f^{G_0}, f^{G_1} \in \mathcal {F}\), then \(\text {MADD}\left (D_{G_0}, D_{G_1}\right )\) converges to \(\left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]}\) in the sense of the risk in \(L_1\), with an optimal convergence speed of at least \(\left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}}\), i.e. \(\exists C>0\) : \begin {equation} \label {eq:cv_rate} \limsup _{\substack {n_0 \rightarrow +\infty \\ n_1 \rightarrow +\infty }} \inf _h \left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{-\frac {2}{3}} \mathbb {E}\left [ \left | \operatorname {MADD}\left (D_{G_0}, D_{G_1}\right ) - \left \| f^{G_0} - f^{G_1} \right \|_{L_1[0,1]} \right | \right ] = C \end {equation} where \(D_{G_0}\) and \(D_{G_0}\) depend on \(h\). This speed is reached when \(h=O\left (\left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}}\right )\).
_________
Proof. To establish the theorem, we begin by examining the \(L_1\) difference between \(f^{G_0} - f^{G_1}\) and \(\widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h\):
\[ \begin {aligned} &\left \| \left ( f^{G_0} - f^{G_1} \right ) - \left ( \widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h \right ) \right \|_{L_1} \\ = &\left \| \left ( f^{G_0} - \widehat {f}^{G_0}_h \right ) - \left ( f^{G_1} - \widehat {f}^{G_1}_h \right ) \right \|_{L_1} \\ \leq &\left \| f^{G_0} - \widehat {f}^{G_0}_h \right \|_{L_1} + \left \| f^{G_1} - \widehat {f}^{G_1}_h \right \|_{L_1} \end {aligned} \]
Drawing upon Theorems 5 and 6 as well as their proofs in Chapter 5 of “Nonparametric Density Estimation: The L1 View” (Devroye and Gyorfi, 1985), we find that the \(L_1\) risk for a histogram estimator \(\widehat {\xi }_h\) is bounded as follows:
\[ \mathbb {E} \left [ \left \| \widehat {\xi }_h - \xi \right \|_{L_1} \right ] \leq \sqrt {\frac {2}{\pi }} \int \sqrt {\frac {\xi }{n h}}+\frac {h}{4} \int \left |\xi ^{\prime }\right | +o\left (h+\frac {1}{\sqrt {nh}}\right ) \]
where \(o\left (h+\frac {1}{\sqrt {nh}}\right )\) represents a term that converges to 0 when \(h+\frac {1}{\sqrt {nh}}\) converges to 0. Applying this to our specific case, we obtain:
\begin {align} &\mathbb {E} \left [ \left \| \left ( f^{G_0} - f^{G_1} \right ) - \left ( \widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h \right ) \right \|_{L_1} \right ] \label {eq:proof2UNDERSCOREa} \\ & \leq \mathbb {E} \left [ \left \| \left (f^{G_0} - \widehat {f}^{G_0}_{h}\right ) \right \|_{L_1} \right ] + \mathbb {E} \left [ \left \| \left (f^{G_1} - \widehat {f}^{G_1}_{h} \right ) \right \|_{L_1} \right ] \\ & \quad \begin {aligned} \leq \sqrt {\frac {2}{\pi }} \int _0^1 \sqrt {\frac {f^{G_0}}{n_0 h}}+\frac {h}{4} \int _0^1\left |\left (f^{G_0}\right )^{\prime }\right | + \sqrt {\frac {2}{\pi }} \int _0^1 \sqrt {\frac {f^{G_1}}{n_1 h}}+\frac {h}{4} \int _0^1\left |\left (f^{G_1}\right )^{\prime }\right |\\ + o\left ( h + \frac {1}{\sqrt {n_0 h}} + \frac {1}{\sqrt {n_1 h}} \right ) \end {aligned}\label {eq:proof2UNDERSCORE0} \end {align}
Combining similar terms in Equation \eqref{eq:proof2UNDERSCORE0} with respect to \(h\) gives:
\begin {align} &\sqrt {\frac {2}{\pi }} \int _0^1 \sqrt {\frac {f^{G_0}}{n_0 h}}+\frac {h}{4} \int _0^1\left |\left (f^{G_0}\right )^{\prime }\right | + \sqrt {\frac {2}{\pi }} \int _0^1 \sqrt {\frac {f^{G_1}}{n_1 h}}+\frac {h}{4} \int _0^1\left |\left (f^{G_1}\right )^{\prime }\right | \\ = &\sqrt {\frac {2}{\pi }} \left ( n_0^{- \frac {1}{2}} \int _0^1 \sqrt {f^{G_0}} +n_1^{- \frac {1}{2}} \int _0^1 \sqrt {f^{G_1}} \right ) h^{- \frac {1}{2}} + \frac {1}{4} \left ( \int _0^1 \left |\left (f^{G_0}\right )^{\prime }\right | + \int _0^1 \left |\left (f^{G_1}\right )^{\prime }\right | \right ) h \label {eq:proof2UNDERSCORE1} \end {align}
By taking the derivative of Equation \eqref{eq:proof2UNDERSCORE1} with respect to \(h\), we find that the global minimum \(h^*\), minimizing the term, is:
\begin {align} h^*&= 2 \pi ^{- \frac {1}{3}} \left ( \int _0^1 \left | \left (f^{G_0}\right )^{\prime } \right | + \int _0^1 \left | \left (f^{G_1}\right )^{\prime } \right | \right )^{- \frac {2}{3}} \left ( \frac {\sqrt {n_0} \int _0^1 \sqrt {f^{G_0}} + \sqrt {n_1} \int _0^1 \sqrt {f^{G_1}}}{\sqrt {n_0 n_1}} \right )^{\frac {2}{3}} \label {eq:proof2UNDERSCORE2}\\ &=O\left (\left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}}\right ) \end {align}
We note that \(h^*\) satisfies the following properties:
-
\(\displaystyle \lim _{\substack {n_0 \rightarrow +\infty \\ n_1 \rightarrow +\infty }} h^* =0\)
-
\(\displaystyle \lim _{n_0 \rightarrow +\infty } n_0 h^* = \infty \)
-
\(\displaystyle \lim _{n_1 \rightarrow +\infty } n_1 h^* = \infty \)
From these properties, we can deduce that when we seek the upper limit of Equation \eqref{eq:proof2UNDERSCORE0}, the limit of the term \(o\left ( h + \frac {1}{\sqrt {n_0 h}} + \frac {1}{\sqrt {n_1 h}} \right )\) is 0. By substituting Equation \eqref{eq:proof2UNDERSCORE2} into Equation \eqref{eq:proof2UNDERSCORE1} and looking at the upper limit of the initial left-side term in inequality \eqref{eq:proof2UNDERSCOREa}, we get:
\begin {align*} &\limsup _{\substack {n_0 \rightarrow +\infty \\ n_1 \rightarrow +\infty }} \inf _{h} \mathbb {E} \left [ \left \| \left ( f^{G_0} - f^{G_1} \right ) - \left ( \widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h \right ) \right \|_{L_1} \right ]\\ & \begin {aligned} \leq \limsup _{\substack {n_0 \rightarrow +\infty \\ n_1 \rightarrow +\infty }} \inf _{h} \sqrt {\frac {2}{\pi }} \left ( n_0^{- \frac {1}{2}} \int _0^1 \sqrt {f^{G_0}} +n_1^{- \frac {1}{2}} \int _0^1 \sqrt {f^{G_1}} \right ) h^{- \frac {1}{2}} + \frac {1}{4} \left ( \int _0^1 \left |\left (f^{G_0}\right )^{\prime }\right | + \int _0^1 \left |\left (f^{G_1}\right )^{\prime }\right | \right ) h\\ + o\left ( h + \frac {1}{\sqrt {n_0 h}} + \frac {1}{\sqrt {n_1 h}} \right ) \end {aligned}\\ & \quad = \limsup _{\substack {n_0 \rightarrow +\infty \\ n_1 \rightarrow +\infty }} \sqrt {\frac {2}{\pi }} \left ( n_0^{- \frac {1}{2}} \int _0^1 \sqrt {f^{G_0}} +n_1^{- \frac {1}{2}} \int _0^1 \sqrt {f^{G_1}} \right ) h^{* - \frac {1}{2}} + \frac {1}{4} \left ( \int _0^1 \left |\left (f^{G_0}\right )^{\prime }\right | + \int _0^1 \left |\left (f^{G_1}\right )^{\prime }\right | \right ) h^* \end {align*}
Since \(\sqrt {\frac {2}{\pi }} \left ( n_0^{- \frac {1}{2}} \int _0^1 \sqrt {f^{G_0}} +n_1^{- \frac {1}{2}} \int _0^1 \sqrt {f^{G_1}} \right ) h^{* - \frac {1}{2}} =O\left ( \frac {\sqrt {n_0} + \sqrt {n_1}}{\sqrt {n_0 n_1}} \right )^{\frac {2}{3}}\), then
\[ \limsup _{\substack {n_0 \rightarrow +\infty \\ n_1 \rightarrow +\infty }} \inf _h \mathbb {E} \left [ \left \| \left ( f^{G_0} - f^{G_1} \right ) - \left ( \widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h \right ) \right \|_{L_1} \right ] =O\left (\left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}}\right ) \]
According to the Theorem 1, we have \(\operatorname {MADD}\left (D_{G_0}, D_{G_1}\right ) = \left \|\widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h\right \|_{L_1}\). Thus, by the absolute value inequality: \[ \mathbb {E}\left [ \left | \left \| f^{G_0} - f^{G_1} \right \|_{L_1} - \operatorname {MADD}\left (D_{G_0}, D_{G_1}\right ) \right | \right ] \leq \mathbb {E}\left [ \left \| \left ( f^{G_0} - f^{G_1} \right ) - \left (\widehat {f}^{G_0}_h - \widehat {f}^{G_1}_h \right ) \right \|_{L_1} \right ] \]
Therefore, \(\exists C>0\) : \[ \limsup _{\substack {n_0 \rightarrow +\infty \\ n_1 \rightarrow +\infty }} \inf _h \left ( \frac {\sqrt {n_0} + \sqrt {n_1}}{\sqrt {n_0 n_1}} \right )^{-\frac {2}{3}} \mathbb {E}\left [ \left | \operatorname {MADD}\left (D_{G_0}, D_{G_1}\right ) - \left \| f^{G_0} - f^{G_1} \right \|_{L_1} \right | \right ] = C \]
This concludes the proof of Theorem 2. \(\square \)
10.3. Proof of Equation \eqref{eq:logUNDERSCOREcvUNDERSCOREspeed}
\begin {align*} \log \left ( \left ( \frac {\sqrt {n_0} + \sqrt {n_1} }{ \sqrt {n_0 n_1}} \right )^{\frac {2}{3}} \right ) &= \log \left ( \left ( \frac {n_0 + n_1 + 2\sqrt {n_0 n_1} }{ n_0 n_1} \right )^{\frac {1}{3}} \right ) \\ &= \frac {1}{3} \log \left ( \frac {n + 2\sqrt {n_0 n_1} }{ n_0 n_1} \right )\\ & = \frac {1}{3} \log \left ( \frac {n + 2\sqrt {\alpha \beta n^2} }{\alpha \beta n^2} \right ) \\ & = \frac {1}{3} \log \left ( \frac {1 + 2\sqrt {\alpha \beta } }{\alpha \beta } \frac {1}{n} \right ) \\ & = \frac {1}{3} \log \left ( \frac {1 + 2\sqrt {\alpha \beta } }{\alpha \beta } \right ) + \frac {1}{3} \log (n^{-1})\\ & = \frac {1}{3} \log \left ( \left (\frac {\alpha \beta }{1 + 2\sqrt {\alpha \beta }} \right )^{-1} \right ) - \frac {1}{3} \log (n) \\ & = -\frac {1}{3} \log \left (\frac {\alpha \beta }{1 + 2\sqrt {\alpha \beta }} \right ) - \frac {1}{3} \log (n) \end {align*}
10.4. Proof of Equations \eqref{eq:2} and \eqref{eq:3} (linear relationships)
We set \(C\) to be a random variable with probability density function \(\mathcal {D}\), representing the predicted probability value of the output of the model \(\mathcal {C}\), and \(S\) to be a random variable subject to Bernoulli distribution, representing the value of the sensitive parameter. Thus, \(\mathcal {D}^{G_0}\) and \(\mathcal {D}^{G_1}\) are the probability density functions of the conditional distributions \(C | S=0\) and \(C | S=1\), respectively. According to the law of total probability, we have: \[ \begin {alignedat}{2} &\quad &\mathbb {P}\left ( C \leq t \right ) &= \mathbb {P}\left ( C \leq t \mid S=0 \right ) \ \mathbb {P}\left ( S=0 \right ) + \mathbb {P}\left ( C \leq t \mid S=1 \right ) \ \mathbb {P}\left ( S=1 \right ) \\ &\Longleftrightarrow & F(t) &= F^{G_0}(t) \ \mathbb {P}\left ( S=0 \right ) + F^{G_1}(t) \ \mathbb {P}\left ( S=1 \right ) \\ &\Longleftrightarrow & \mathcal {D}(t) &= \mathcal {D}^{G_0}(t) \ \mathbb {P}\left ( S=0 \right ) + \mathcal {D}^{G_1}(t) \ \mathbb {P}\left ( S=1 \right ) \end {alignedat} \] where \(F, F^{G_0}, F^{G_1}\) are the cumulative distribution functions (CDFs) of \(\mathcal {D}\), \(\mathcal {D}^{G_0}\), \(\mathcal {D}^{G_1}\), respectively. Since \(\mathbb {P}\left ( S=0 \right ) + \mathbb {P}\left ( S=1 \right ) = 1\), \(f\) is a linear combination of \(\mathcal {D}^{G_0}\) and \(\mathcal {D}^{G_1}\), and \(\mathcal {D}\) lies between \(\mathcal {D}^{G_0}\) and \(\mathcal {D}^{G_1}\) in the function space (i.e., \(\mathcal {D}^{G_0}, \mathcal {D}, \mathcal {D}^{G_0}\) are collinear).
This property is also true for estimators obtained from observed values. In fact, the definition of the sequence of the heights of the histogram is: for the \(m\) equal sub-intervals \(\left ] \frac {k-1}{m}, \frac {k}{m} \right ]\) for all \(k \in \{1, \ldots , m\}\) on \([0,1]\),
\begin {align*} &D_{G_0} &:= \left \{ d_{G_0, k} \mid \forall k \in \{ 1,\ldots , m \} \right \}, &\text { with } d_{G_0, k} &:= &\frac {N_{G_0, k}}{n_0} := \frac {1}{n_0}\sum _{i \in G_0} \mathds {1}_{\hat {p}_i \in I_k} \\ &D_{G_1} &:= \left \{ d_{G_1, k} \mid \forall k \in \{ 1,\ldots , m \} \right \}, &\text { with } d_{G_1, k} &:= &\frac {N_{G_1, k}}{n_1} := \frac {1}{n_1}\sum _{i \in G_1} \mathds {1}_{\hat {p}_i \in I_k} \\ &D_{G} &:= \left \{ d_{G, k} \mid \forall k \in \{ 1,\ldots , m \} \right \}, &\text { with } d_{G, k} &:= &\frac {N_{G_0, k} + N_{G_1, k}}{n_0 + n_1} := \frac {1}{n_0 + n_1}\sum _{i \in G} \mathds {1}_{\hat {p}_i \in I_k} \end {align*}
And because for all \(k \in \{1,\ldots , m\}\), we have:
\begin {align*} d_{G, k} &= \frac {N_{G_0, k} + N_{G_1, k}}{n_0 + n_1} = \frac {n_0 \ d_{G_0,k} + n_1 \ d_{G_1,k}}{n_0 + n_1} \\ &= \frac {n_0}{n_0 + n_1} d_{G_0,k} + \frac {n_1}{n_0 + n_1} d_{G_1,k} \end {align*}
Also, \(f^{G_0}, f, f^{G_1}\) are based on \(D_{G_0}, D_{G}, D_{G_1}\), respectively:
\begin {align*} f^{G_0}(x) &:= \sum _{k=i}^m d_{G_0, k} \mathds {1}_{x \in I_k} \\ f^{G_1}(x) &:= \sum _{k=i}^m d_{G_1, k} \mathds {1}_{x \in I_k} \\ f(x) &:= \sum _{k=i}^m d_{G, k} \mathds {1}_{x \in I_k} \end {align*}
Therefore, \(f(x) = \frac {n_0}{n_0 + n_1} f^{G_0}(x) + \frac {n_1}{n_0 + n_1} f^{G_1}(x)\), so \(f^{G_0}, f, f^{G_1}\) are also collinear (see Figure 14b). This is not a coincidence; in fact, as histogram estimators, when \((n_0, n_1) \to +\infty \), \(\left ( f^{G_0}, f, f^{G_1} \right ) \to \left ( \mathcal {D}_{G_0}, \mathcal {D}_{G}, \mathcal {D}_{G_1} \right )\).
10.5. Proof of Equations \eqref{eq:7} and \eqref{eq:8} (CDF-based distribution transition)
According to Inverse transform sampling (Devroye, 1986), we have the following two theorems:
Theorem 3___________
Let \(\mathcal {A}\) be a distribution and \(F_{\mathcal {A}}\) be the cumulative distribution function of that distribution. If \(X\) obeys the distribution \(\mathcal {A}\) i.e. \(X \sim \mathcal {A}\), then \(F_{\mathcal {A}}(X) \sim \mathcal {U}_{[0, 1]}\), where \(\mathcal {U}_{[0,1]}\) is a uniform distribution over \([0,1]\).
Theorem 4___________
Let \(U \sim \mathcal {U}_{[0,1]}\) and \(F^{-1}_{\mathcal {A}}\) be the generalised inverse function of \(F_{\mathcal {A}}\), then \(F^{-1}_{\mathcal {A}}(U) \sim \mathcal {A}\).
_________
Let us consider group \(G_0\) as an example. By definition, the newly generated prediction \(\overline {p}_{i}^{(\lambda )}\) is \(\overline {\operatorname {CDF}}_{G_0}^{-1(\lambda )}(\operatorname {CDF}_{G_0}(\hat {p}_i))\), and by applying Theorem 3, we have \(\operatorname {CDF}_{G_0}(\hat {p}_i) \sim \mathcal {U}_{[0,1]}\), therefore \(\overline {\operatorname {CDF}}_{G_0}^{-1(\lambda )}(\operatorname {CDF}_{G_0}(\hat {p}_i))\) obeys the newly generated distribution according to Theorem 4. Furthermore, since the CDF is monotone increasing and the inverse function does not change the monotonicity, \(\overline {\operatorname {CDF}}_{G_0}^{-1(\lambda )}\) is also monotone increasing, which means that \(\forall i,j, \hat {p}_i \geq \hat {p}_j \Longrightarrow \overline {p}_{i}^{(\lambda )} \geq \overline {p}_{i}^{(\lambda )}\). The conclusion on \(G_1\) follows the same reasoning.
1e.g., General Data Protection Regulation (2016) at European level, California Consumer Privacy Act (2018) at the United-States level, Principles on Artificial Intelligence (2019) from OECD (Organization for Economic Cooperation and Development) at the international level, and more specifically the upcoming European AI Act (Sovrano et al., 2022).
2https://github.com/melinaverger/MADD
3https://pypi.org/project/maddlib
4Named imd_bandin the original data.
5Here, not a mathematical function, but a programming function. See details at
https://github.com/melinaverger/MADD.
6\(\overline {y}_i\) corresponds to the new predictions (1 or 0) obtained thanks to the new \(\overline {p}_{i}^{(\lambda )}\) thresholded with the classification threshold parameter \(t\) we primarily set at \(0.5\) (i.e. \(\overline {y}_i = 0\) when \(\overline {p}_{i}^{(\lambda )} < 0.5\), \(\overline {y}_i = 1\) otherwise).